Lokátory v Selenium
⚡ Chytré shrnutí
Lokátory v Selenium jsou příkazy, které řídí automatizační engine k identifikaci prvků grafického uživatelského rozhraní, jako jsou textová pole, tlačítka a zaškrtávací políčka. Tato příručka vysvětluje typy lokátorů ID, Name, Link Text, DOM a XPath s praktickými příklady, syntaktickými pravidly a strategiemi výběru pro spolehlivé skripty webové automatizace.

Co jsou lokátory Selenium?
Lokátor je příkaz, který nařizuje Selenium IDE nebo Selenium WebDriver ke správnému prvku grafického uživatelského rozhraní, jako je textové pole, tlačítko, odkaz nebo zaškrtávací políčko, na kterém má být provedena akce. Identifikace správného prvku grafického uživatelského rozhraní je předpokladem pro vytvoření jakéhokoli spolehlivého automatizačního skriptu. Přesná identifikace je však náročnější, než se zdá. Někdy se může stát, že budete interagovat se špatným prvkem nebo vůbec bez prvku. Aby se to vyřešilo, Selenium nabízí řadu strategií vyhledávání, které umožňují přesné cílení prvků grafického rozhraní.
Zatímco některé příkazy, například příkaz „otevřít“, nevyžadují lokátor, většina z nich Selenium Příkazy závisí na lokátorech prvků. Výběr lokátoru do značné míry závisí na vaší testované aplikaci (AUT). V tomto tutoriálu se budeme střídat mezi Facebookem a Mercury Demo stránky Tours (newtours.demoaut) na základě toho, které lokátory jednotlivé aplikace podporují. Stejně tak ve vaší vlastní Testování projektu vyberete lokátor elementů v Selenium WebDriver na základě struktury vaší aplikace.
Lokalizace podle ID
Toto je nejběžnější metoda vyhledávání prvků, protože ID mají být jedinečná pro každý prvek na stránce. Kdykoli existuje atribut ID, měl by být vaší první volbou pro rychlé, stabilní a čitelné testovací skripty.
Target Formát: id=id prvku
V tomto příkladu použijeme demo stránku na Facebooku, protože Mercury Tours nepoužívá atributy ID pro hlavní pole formuláře.
Krok 1) Použijte tuto ukázkovou stránku https://demo.guru99.com/test/facebook.html pro testování. Zkontrolujte textové pole „E-mail nebo telefon“ pomocí vestavěných nástrojů pro vývojáře ve vašem prohlížeči (stiskněte klávesu F12 v Chrome, Edge nebo Firefox) a poznamenejte si jeho ID. V tomto případě je ID „e-mail“.

Krok 2) zahájit Selenium IDE a do pole zadejte „id=email“. Target pole. Klikněte na tlačítko Najít a všimněte si, že textové pole „E-mail nebo telefon“ je zvýrazněno žlutě se zeleným okrajem, což znamená, že Selenium IDE správně lokalizovalo prvek.

Lokalizace podle jména
Vyhledávání prvků podle názvu je podobné vyhledávání podle ID, s tím rozdílem, že používáme "jméno =" prefix místo toho. Tento přístup je užitečný, když elementům chybí ID, ale mají definovaný atribut name.
Target Formát: jméno=název prvku
Pro následující demonstraci použijeme Mercury Prohlídky, protože všechny významné prvky formuláře na webu nesou atribut name.
Krok 1) přejděte na https://demo.guru99.com/test/newtours/ a pomocí nástrojů pro vývojáře prohlížeče zkontrolujte textové pole „Uživatelské jméno“. Všimněte si jeho atributu name.

Zde je název prvku „userName“.
Krok 2) In Selenium IDE, do pole zadejte „name=userName“. Target a klikněte na tlačítko Najít. Selenium IDE by mělo najít textové pole Uživatelské jméno jeho zvýrazněním.

Jak najít prvek podle názvu pomocí filtrů
Filtry jsou užitečné, když několik prvků sdílí stejný atribut name. Filtry jsou další atributy používané k rozlišení prvků se stejným názvem. Bez filtrů, Selenium by se standardně použil pouze první odpovídající prvek.
Target Formát: name=name_of_the_element filter=value_of_filter
Pojďme si projít příklad.
Krok 1) Přihlaste se Mercury Prohlídky.
Přihlaste se do služby Mercury Prohlídky s použitím „tutorial“ jako uživatelského jména i hesla. Měla by se zobrazit stránka Vyhledávač letů, jak je znázorněno níže.

Krok 2) Pomocí nástrojů pro vývojáře zkontrolujte atributy VALUE.
Všimněte si, že přepínače Zpáteční cesta a Jednosměrná cesta mají stejný název „tripType“. Mají však různé atributy VALUE, takže každou hodnotu můžeme použít jako filtr.

Krok 3) Klikněte na první řádek v editoru.
- Nejprve se dostaneme k přepínači Jednosměrný směr. Klikněte na první řádek v Selenium Editor IDE.
- Do pole Příkaz zadejte příkaz „kliknout“.
- v Target zadejte do pole „name=tripType value=oneway“. Část „value=oneway“ slouží jako náš filtr.

Krok 4) Klepněte na tlačítko Najít.
Všimněte si to Selenium IDE zvýrazní přepínač Jednosměrný přístup zeleně, což potvrzuje, že k prvku byl úspěšně přistupováno prostřednictvím jeho atributu VALUE.

Krok 5) Vyberte přepínač Jednosměrná doprava.
Stiskněte klávesu „X“ na klávesnici pro spuštění příkazu kliknutí. Přepínač Jednosměrný je nyní vybrán.

Stejnou akci můžete provést s přepínačem Zpáteční cesta, tentokrát s použitím „name=tripType value=zpáteční cesta“ jako cíle.
Lokalizace podle textu odkazu
Tato strategie lokace platí pouze pro texty hypertextových odkazů. K odkazu přistupujeme tak, že před cíl přidáme „link=“ a poté viditelný text hypertextového odkazu. Tato metoda je snadno čitelná a funguje dobře pro testování navigace.
Target Formát: odkaz=text_odkazu
V následujícím příkladu se dostaneme k odkazu „REGISTRACE“, který se nachází na Mercury Domovská stránka prohlídek.
Krok 1)
- Nejprve se ujistěte, že jste odhlášeni z Mercury Prohlídky.
- Přejděte na Mercury Domovská stránka prohlídek.
Krok 2)
- Pomocí nástrojů pro vývojáře zkontrolujte odkaz „REGISTRACE“. Text odkazu se zobrazí mezi otevíracím a uzavíracím kotevním tagem.
- V tomto případě je text odkazu „REGISTRACE“. Zkopírujte text odkazu.
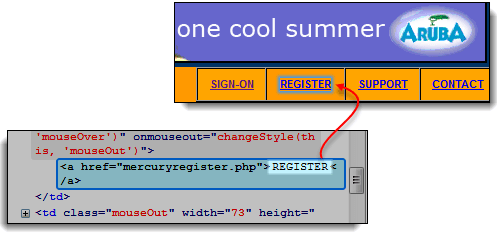
Krok 3) Zkopírujte text odkazu a vložte ho do Selenium IDE Target krabice. Před ním uveďte „link=“.

Krok 4) Klepněte na tlačítko Najít. Selenium IDE správně zvýrazní odkaz REGISTER.

Krok 5) Pro další ověření zadejte „clickAndWait“ do pole Příkaz a spusťte jej. Selenium IDE úspěšně klikne na odkaz REGISTRACE a přesměruje vás na registrační stránku zobrazenou níže.

Lokalizace podle DOM (model objektu dokumentu)
Jedno Model objektu dokumentu (DOM)Jednoduše řečeno, popisuje, jak jsou HTML prvky strukturovány jako strom uzlů. Selenium IDE může procházet tento strom a přistupovat k prvkům stránky. Při použití této metody Target Pole vždy začíná „dom=document…“. Předpona „dom=“ se obvykle vynechává, protože Selenium IDE automaticky interpretuje jakoukoli hodnotu začínající na „document“ jako cestu DOM.
Existují čtyři základní způsoby, jak najít prvek v DOMu. Selenium:
- getElementById
- getElementsByName
- dom:name (platí pouze pro prvky v pojmenovaném formuláři)
- dom:index
Lokalizace podle DOM – getElementById
Nejprve se podívejme na metodu getElementById v DOMu. SeleniumTato metoda vrací jeden prvek na základě porovnání jeho atributu ID.
Syntax
document.getElementById("id of the element")
- id elementu = hodnota atributu ID elementu, ke kterému se má přistupovat. Tato hodnota musí být vždy uzavřena do uvozovek.
Krok 1) Použijte tuto ukázkovou stránku https://demo.guru99.com/test/facebook.htmlPřejděte k němu a pomocí Nástrojů pro vývojáře zkontrolujte zaškrtávací políčko „Zůstat přihlášen/a“. Poznamenejte si jeho ID.

ID, které bychom měli použít, je „persist_box“.
Krok 2) Otevřená Selenium IDE a v Target Do pole zadejte document.getElementById(„persist_box“) a poté klikněte na tlačítko Najít. Selenium IDE vyhledá zaškrtávací políčko „Zůstat přihlášen/a“. I když vnitřek zaškrtávacího políčka nelze zvýraznit, prvek obklopí jasně zeleným okrajem, jak je znázorněno níže.

Lokalizace podle DOM – getElementsByName
Metoda getElementById přistupuje vždy pouze k jednomu prvku, a to k prvku se zadaným ID. Metoda getElementsByName se chová jinak. Vrací pole prvků, které sdílejí zadaný název. K jednotlivým prvkům se přistupuje pomocí číselného indexu, který začíná na 0.
 |
getElementById Vrací pouze jeden prvek. Tento prvek má ID uvedené v závorkách funkce getElementById(). |
 |
getElementsByName Vrací kolekci prvků, jejichž názvy jsou shodné. Každý prvek je indexován číslem začínajícím 0, podobně jako pole. Konkrétní prvek vyberete umístěním jeho indexu do hranatých závorek v níže uvedené syntaxi. |
Syntax
document.getElementsByName("name")[index]
- name = jméno prvku, jak je definováno jeho atributem 'name'
- index = celé číslo, které označuje, který prvek v poli getElementsByName bude použit.
Krok 1) Přejděte na Mercury Přejděte na domovskou stránku Tours a přihlaste se pomocí uživatelského jména a hesla „tutorial“. Prohlížeč načte obrazovku Vyhledávač letů.
Krok 2) Pomocí nástrojů pro vývojáře zkontrolujte tři přepínače v dolní části stránky (Economy class, Business class a First class). Všimněte si, že všechny mají stejný název, „servClass“.

Krok 3) Nejprve si přepněte přepínač „Ekonomická třída“. Ze tří přepínačů se tento prvek objeví jako první, takže jeho index je 0. V Selenium V IDE zadejte document.getElementsByName(“servClass”)[0] a klikněte na tlačítko Najít. Selenium IDE správně identifikuje přepínač ekonomické třídy.

Krok 4) Změňte indexové číslo na 1, takže vaše Target se stane document.getElementsByName(„servClass“)[1]. Klikněte na tlačítko Najít a Selenium IDE zvýrazní přepínač „Business class“, jak je znázorněno níže.

Lokalizace podle DOM – dom:name
Jak již bylo zmíněno, tato metoda platí pouze v případě, že se prvek, ke kterému přistupujete, nachází v pojmenovaném formuláři. Cesta lokátoru začíná u formuláře a poté se podle názvu přesouvá k cílovému prvku.
Syntax
document.forms["name of the form"].elements["name of the element"]
- název formuláře = hodnota atributu name tagu formuláře, který obsahuje prvek, ke kterému chcete přistupovat
- jméno prvku = hodnota atributu name prvku, ke kterému chcete přistupovat
Krok 1) přejděte na Mercury Domovská stránka prohlídek https://demo.guru99.com/test/newtours/ a pomocí Nástrojů pro vývojáře zkontrolujte textové pole Uživatelské jméno. Všimněte si, že je obsaženo ve formuláři s názvem „domov“.

Krok 2) In Selenium IDE zadejte document.forms[„home“].elements[„userName“] a klikněte na tlačítko Najít. Selenium IDE bude k elementu úspěšně přistupovat.

Lokalizace podle DOM – dom:index
Tato metoda platí i v případě, že element není v pojmenovaném formuláři, protože používá index formuláře místo jeho názvu. To je užitečné pro starší stránky nebo automaticky generované formuláře, kde pojmenování není k dispozici.
Syntax
document.forms[index of the form].elements[index of the element]
- index formuláře = indexové číslo (počínaje 0) formuláře vzhledem k celé stránce
- index elementu = indexové číslo (počínaje 0) elementu vzhledem k formuláři, který jej obsahuje
Získáme přístup k textovému poli „Telefon“ na Mercury Stránka registrace prohlídek. Formulář na této stránce nemá ani atribut názvu, ani atributu ID, takže je dobrým příkladem.
Krok 1) Přejděte na Mercury Prohlédněte si stránku Registrace a prohlédněte si textové pole Telefon. Všimněte si, že okolní formulář nemá atributy ID ani name.

Krok 2) Zadejte document.forms[0].elements[3] do Selenium IDE Target a klikněte na tlačítko Najít. Selenium IDE bude správně přistupovat k textovému poli Telefon.

Krok 3) Alternativně můžete pro stejný výsledek použít název elementu místo jeho indexu. Do pole zadejte document.forms[0].elements[„phone“] Target Textové pole Telefon bude stále zvýrazněno.

Lokalizace pomocí XPath
XPath je dotazovací jazyk používaný k navigaci v uzlech XML (Extensible Markup Language). Protože HTML lze považovat za implementaci XML, XPath může také vyhledávat prvky HTML. Je to jedna z nejúčinnějších strategií vyhledávání v Selenium.
- Výhoda: Může přistupovat k téměř jakémukoli prvku, včetně těch bez atributů třídy, názvu nebo ID.
- Nevýhoda: Je to nejsložitější strategie lokátoru kvůli mnoha pravidlům a syntaktickým variantám.
Moderní nástroje pro vývojáře prohlížečů mohou automaticky generovat výrazy XPath. V Chrome, Edge nebo Firefox, klikněte pravým tlačítkem myši na prvek v panelu Prvky a vyberte Kopírovat > Kopírovat XPath. V následujícím příkladu budeme přistupovat k obrázku, který nelze nalézt pomocí dříve popsaných metod.
Krok 1) Přejděte na Mercury Na domovské stránce Tours si prohlédněte oranžový obdélník napravo od žlutého pole „Odkazy“, jak je znázorněno níže.

Krok 2) Klikněte pravým tlačítkem myši na HTML kód elementu a poté vyberte možnost „Kopírovat XPath“.

Krok 3) In Selenium IDE, zadejte do pole jedno lomítko „/“ Target a poté vložte XPath zkopírovaný v předchozím kroku. Záznam v Target pole by nyní mělo začínat dvěma lomítky „//“.

Krok 4) Klepněte na tlačítko Najít. Selenium IDE zvýrazní oranžový rámeček, jak je znázorněno níže.

Proč je důležitý výběr správného lokátoru
Výběr správné strategie lokátoru je jedním z nejvlivnějších rozhodnutí v Selenium automatizace, protože přímo ovlivňuje stabilitu skriptů, rychlost provádění a dlouhodobé náklady na údržbu. Špatně zvolený lokátor může způsobit nestabilní testy, falešná selhání a časté přepracování při každé změně uživatelského rozhraní aplikace. Pořadí preferencí doporučené zkušenými automatizačními inženýry je nejprve ID, poté Název, následovaný Selektorem CSS, Textem odkazu a nakonec XPath.
Lokátory založené na ID jsou nejrychlejší, protože vyhledávání v prohlížeči je optimalizováno pro jedinečné identifikátory. Lokátory založené na jménech jsou téměř stejně efektivní, pokud jsou jména jedinečná. Selektory CSS a XPath poskytují flexibilitu, ale bývají pomalejší a křehčí, když vývojáři refaktorují DOM. Text odkazu je vynikající pro navigační odkazy, ale nabízí omezené opětovné použití.
Stabilní automatizace závisí také na spolupráci s vývojáři. Když testeři během revizí kódu požadují konzistentní a smysluplné atributy ID nebo data-*, výrazně se zlepší odolnost lokátorů. Vyhněte se spoléhání na automaticky generovaná ID (například ta, která vytvářejí frameworky), protože se mohou mezi sestaveními měnit. Upřednostněním čitelných lokátorů řízených záměrem mohou týmy udržovat testovací sady v udržitelnosti a snižovat technický dluh s vývojem aplikace.
Nejlepší postupy pro psaní spolehlivých lokátorů
Spolehlivé lokátory jsou základem udržovatelné Selenium testovací sada. Následující postupy pomáhají snížit počet selhání skriptů, zlepšit čitelnost a učinit testy odolnými vůči změnám v uživatelském rozhraní.
- Preferujte jedinečná ID: Vždy nejprve zkontrolujte atribut ID. ID mají být v rámci stránky jedinečná a jsou nejúčinnější volbou.
- Použijte sémantický název a atributy data-*: Povzbuďte vývojáře, aby přidávali stabilní atributy testů, jako například data-testid nebo data-qa. Ty zůstávají konzistentní i při změně tříd CSS.
- Vyhněte se absolutnímu XPath: Absolutní cesty jako /html/body/div[2]/div[3]/span se snadno přeruší. Používejte relativní výrazy XPath s atributy jako //input[@name='userName'].
- Kombinujte atributy pro dosažení přesnosti: Pokud jeden atribut není jedinečný, zkombinujte více atributů (například //button[@type='submit' a @name='login']) pro cílení na správný element.
- Používejte text moudře: Lokátory závislé na viditelném textu se mohou narušit v různých jazykových lokalizacích. Textové lokátory používejte pouze tehdy, je-li obsah stabilní a jednojazyčný.
- Centralizujte lokátory: Uložte lokátory do třídy POM (Page Object Model), aby bylo možné aktualizace provádět na jednom místě, nikoli napříč mnoha testovacími skripty.
- Ověřit v nástrojích pro vývojáře: Před přidáním lokátoru do skriptu jej otestujte v konzoli prohlížeče pomocí $x(“//xpath”) pro XPath nebo document.querySelector pro CSS, abyste se ujistili, že vrací přesně jeden prvek.
- Pokud je to možné, vyhněte se lokátorům založeným na indexech: Pozice indexů, jako například [3], závisí na pořadí prvků. I drobné změny rozvržení mohou index posunout a narušit fungování skriptu.
Důsledným uplatňováním těchto postupů vytvářejí automatizační inženýři testovací sady, které se dají škálovat napříč týmy a odolávají častým aktualizacím uživatelského rozhraní s minimální údržbou.