SAP HANA ArchiPředmět: Přehled databáze
⚡ Chytré shrnutí
SAP HANA ArchiTextura, krajina a dimenzování tvoří základ platformy pro data v paměti postavené na SUSE Linuxu a C++Tento článek vysvětluje indexový server, úložné moduly, úložiště řádků a sloupců, delta slučování a metody změny velikosti hardwaru.

Co je to SAP Databáze HANA?
SAP HANA je platforma pro správu dat zaměřená na hlavní paměť. Databáze běží na serveru SUSE Linux Enterprise Server (SLES) a Red Hat Enterprise Linux (RHEL) a je napsán v C++Pro velmi velké úlohy se dá škálovat na více počítačů.
Klíčové výhody SAP HANA:
- Extrémně rychlý výkon dotazů, protože všechna data jsou načítána do paměti, čímž se z kritické cesty odstraňují pomalé diskové I/O operace.
- Kombinace OLAP (Online Analytical Processing) a OLTP (Online Transaction Processing) na stejné databázi, což zjednodušuje datovou krajinu.
SAP Databáze HANA je sestavena ze sady procesorů v paměti. Výpočtový engine je hlavní a interaguje s dalšími enginy, jako je relační engine (úložiště řádků a sloupců), OLAP engine, textový engine a grafový engine. Relační tabulka se nachází buď v úložišti řádků, nebo ve sloupcovém úložišti a další enginy zpracovávají textová a grafová data, pokud je k dispozici paměť.
SAP HANA Architecture
Data ve sloupcovém úložišti jsou komprimována pomocí technik, jako je slovníkové kódování, kódování délky běhu, řídké kódování, kódování clusterů a nepřímé kódování. Po dosažení limitu hlavní paměti se nepoužívané databázové objekty (tabulky, pohledy atd.) automaticky uvolní na disk a znovu načtou, když jsou znovu vyžádány.
Administrátoři mohou také ručně načíst nebo uvolnit jednotlivé tabulky kliknutím pravým tlačítkem myši na tabulku v SAP Studio HANA a výběr vyložit or Zatížení.
SAP Server HANA se skládá z:
- Indexový server
- Preprocesorový server
- Název serveru
- Statistický server
- Motor XS
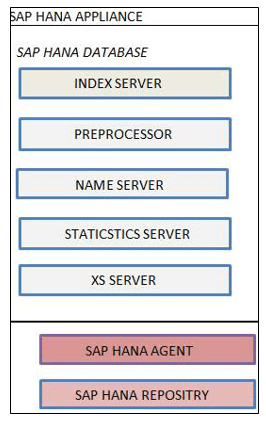
1. SAP Indexový server HANA
Indexový server je hlavní SAP Databázová komponenta HANA:
- Je to srdce SAP Databázový engine HANA.
- Obsahuje skutečná datová úložiště a moduly, které data zpracovávají.
- Provádí příchozí příkazy SQL a MDX.
Architektura indexového serveru je znázorněna níže.

SAP Přehled indexového serveru HANA
- Správce relace a transakcí: Komponenta Session spravuje připojení a relace pro databázi. Správce transakcí koordinuje a řídí všechny transakce.
- SQL a MDX procesor: SQL procesor odesílá dotazy do příslušného enginu (SQL / SQL Script / R / Calc Engine). MDX procesor zpracovává vícerozměrné dotazy (například proti analytickému zobrazení).
- SQL / SQL Script / R / Calc Engine: Spouští SQL, SQL Script, R a výpočetní modely na datech.
- Repository: Udržuje verzování pro SAP Objekty metadat HANA, jako jsou zobrazení atributů, analytická zobrazení a uložené procedury.
- Vrstva perzistence: Poskytuje vestavěnou funkci pro zotavení po havárii zápisem bodů uložení a protokolů do datového svazku na disku.
2. Server preprocesoru
Server preprocesoru je používán analýzou textu. Využívátracts a připraví data z textového obsahu při vyvolání vyhledávací funkce.
3. Jmenný server
Name Server uchovává informace o celém systémovém prostředí. V distribuovaném nasazení tracks každou spuštěnou komponentu a umístění dat napříč uzly, aby dotazy mohly být směrovány na správný server.
4. Statistický server
Statistický server shromažďuje data o stavu, alokaci zdrojů, spotřebě a výkonu pro SAP Systém HANA. Poznámka: v HANA SPS 7 a novějších verzích běží integrovaná statistická služba uvnitř indexového serveru, nikoli jako samostatný proces.
5. XS Server
XS Server hostuje XS Engine, který umožňuje externím aplikacím a vývojářům využívat SAP Databáze HANA přes HTTP. XS Engine sám o sobě funguje jako lehký HTTP server, který umožňuje klientům z prohlížeče a REST klientům komunikovat přímo s HANA.
SAP Krajina HANA
„HANA“ je zkratka pro Vysoce výkonný analytický přístroj a je dodáván jako kombinovaná hardwarová a softwarová platforma.
- Moderní hardware nabízí mnohem více jader CPU, paměti RAM a šířky pásma úložiště, než pro jaké byly navrženy starší databázové servery.
- SAP HANA toho zneužívá tím, že keeping všechna pracovní data v hlavní paměti, čímž se eliminuje úzké hrdlo diskového I/O, které omezuje tradiční databáze.
Níže uvedený diagram shrnuje SAP Inovace hardwaru a softwaru HANA.

SAP HANA podporuje dvě relační datová úložiště: Prodejna řádků a Sloupový obchod.
Prodejna řádků
Úložiště řádků se chová jako tradiční databáze (Oracle, SQL Server). Klíčový rozdíl spočívá v tom, že všechny řádky se nacházejí v hlavní paměti v SAP HANA, zatímco tradiční databáze je uchovává primárně na disku.
Sloupový obchod
Sloupcové úložiště uchovává data v paměti ve sloupcové podobě. Zde se ukládají sloupcové tabulky a engine vyvažuje dobrý výkon zápisu s optimalizovaným výkonem čtení. Níže uvedený diagram ukazuje dvě struktury, které této rovnováhy dosahují.

Hlavní úložiště
Hlavní úložiště uchovává většinu dat. Pro úsporu paměti a zrychlení vyhledávání se používají kompresní metody, jako je slovníkové kódování, klastrové kódování, řídké kódování a kódování délky běhu.
- Úprava komprimovaných dat přímo v hlavním úložišti je nákladná, takže zápisy nejsou zaměřeny na hlavní úložiště.
- Místo toho se každá změna zapisuje do samostatné oblasti s názvem Delta SkladováníČtení může zasáhnout buď hlavní, nebo delta úložiště.
Data lze načíst nebo uvolnit ručně pomocí Načíst do paměti a Uvolnit z paměti možnosti uvedené níže.

Delta Skladování
Delta Úložiště je optimalizováno pro zápisy a používá lehčí kompresi. Všechny nepotvrzené změny v tabulce sloupců se uchovávají zde. Pokud je třeba změny sloučit zpět do hlavního úložiště, spusťte příkaz Delta Spojit operace z SAP Studio HANA.

- Delta sloučení přesune změny shromážděné v delta úložišti do hlavního úložiště.
- Po sloučení se nový obsah hlavního úložiště uloží na disk a komprese se přepočítá.
Jak se data přesouvají z Delta do hlavního úložiště

Řádkově organizovaná vyrovnávací paměť s názvem L1-Delta nachází se před každou tabulkou sloupců, a proto může tabulka sloupců absorbovat zápisy s vysokou propustností.
- Uživatel spustí v tabulce příkaz UPDATE nebo INSERT.
- Data se nejprve dostanou do L1-Delta (nepotvrzená data).
- Po potvrzení jsou data přesunuta do sloupcově orientovaného L2-Delta vyrovnávací paměti.
- Když L2-Delta je plná nebo se spustí sloučení, data se zapíší do hlavního úložiště.
Sloupcové úložiště je proto optimalizováno jak pro zápis (prostřednictvím delta L1 a L2), tak pro čtení (prostřednictvím hlavního úložiště). Po zpracování jsou data ukládána vrstvou perzistence na disk.
Příklad tabulky založené na řádcích:

Stejná logická tabulka je uložena na disku různě v závislosti na typu úložiště. V úložišti řádků jsou řádky zapisovány souvisle:

V úložišti sloupců jsou hodnoty ze stejného sloupce uloženy společně:

Protože hodnoty sloupců sdílejí datový typ a často se opakují, rozvržení sloupců se extrémně dobře komprimuje – což je hlavní paměťová výhoda úložiště sloupců.

SAP Velikost HANA
Stanovení velikosti je proces určení hardwarových zdrojů – RAM, disku a CPU – potřebných pro SAP Systém HANA. Paměť je nejdůležitějším faktorem, CPU je druhý a disk je odvozen od prvních dvou.
V SAP Při implementaci HANA je výběr správné velikosti serveru pro danou obchodní zátěž jedním z nejdůležitějších úkolů. Ve srovnání s tradičními systémy pro správu databází (DBMS) se dimenzování HANA liší ve třech oblastech:
- Hlavní paměť: řízeno metadaty a objemem transakčních a analytických dat uložených v paměti.
- CPU: odhadované spíše než měřené, založené na prognózovaných dotazech a vzorcích zatížení.
- Disk: dimenzováno pro perzistenci dat a objemy protokolů, nikoli pro data online dotazů.
CPU a paměť aplikačního serveru zůstávají ve srovnání s předchozí databází nezměněny, protože HANA nahrazuje pouze databázovou vrstvu.
SAP nabízí několik metod pro výpočet správné velikosti:
- Stanovení velikosti pomocí sestavy ABAP (kód transakce) ST03 data a zpráva /SDF/HDB_SIZING).
- Určení velikosti pomocí databázového skriptu pro systémy bez ABAP.
- Dimenzování pomocí SAP Rychlý sizer nástroj na SAP Tržiště služeb.
Při použití nástroje Quick Sizer se požadavek zobrazí v níže uvedeném formátu.
