SQL Server Architecture (vysvětleno)
⚡ Chytré shrnutí
SQL Server ArchiTechnologie se řídí modelem klient-server, který je uspořádán do tří základních vrstev: protokolová vrstva pro síťovou komunikaci, relační engine pro zpracování dotazů a úložný engine pro správu a načítání dat.

MS SQL Server je architektura klient-server. Proces MS SQL Serveru začíná odesláním požadavku klientskou aplikací. SQL Server tento požadavek přijímá, zpracovává a odpovídá na něj zpracovanými daty. Pojďme si podrobněji probrat celou architekturu uvedenou níže:
Jak ukazuje níže uvedený diagram, SQL Server má tři hlavní komponenty. Archistruktura:
- Protokolová vrstva
- Relační motor
- Storage Engine
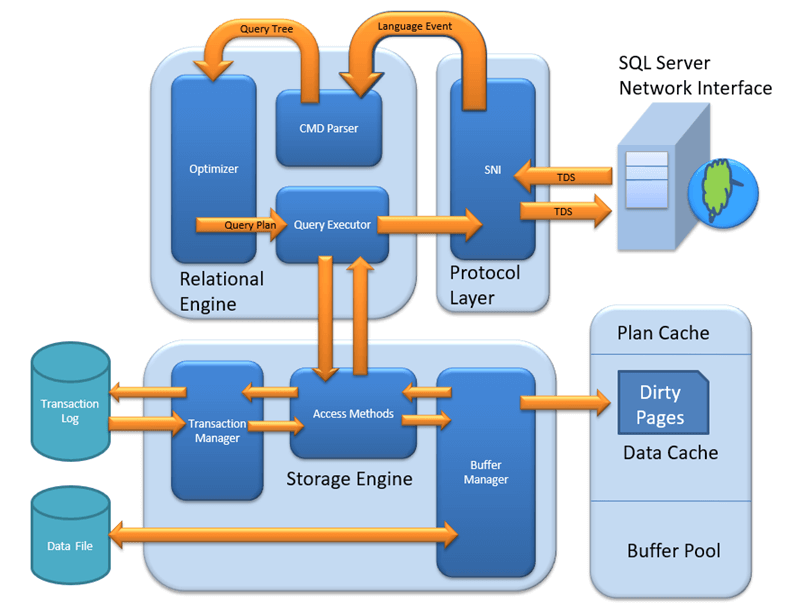
Protokolová vrstva – SNI
Vrstva protokolu SQL Serveru, známá také jako rozhraní serverové sítě (SNI), podporuje tři typy architektury klient-server. Každý protokol slouží jinému síťovému scénáři. Pochopení těchto protokolů je nezbytné před zkoumáním, jak jsou dotazy interně zpracovávány.
Sdílená paměť
Představte si scénář ranního rozhovoru. Tom a jeho maminka jsou na stejném logickém místě, doma. Tom si žádá o kávu a maminka ji přímo naservíruje. Podobně SQL Server poskytuje protokol sdílené paměti, když klient a server běží na stejném počítači. Oba komunikují prostřednictvím sdílené paměti bez jakýchkoli síťových režijních nákladů.

Analogie: Tom se mapuje na klienta, maminka na SQL Server, domovská stránka na počítač a verbální komunikace se mapuje na protokol sdílené paměti.

Poznámky ke konfiguraci: In SQL Management Studio, možnost „Název serveru“ pro lokální připojení může být „.“, „localhost“, „127.0.0.1“ nebo „Počítač\Instance“.
TCP / IP
Nyní si představte, že Tom si přeje kávu z obchodu vzdáleného 10 km. Tom je doma a kavárna je na rušném tržišti. Komunikují přes mobilní síť. Podobně SQL Server poskytuje Protokol TCP / IP když se klient a SQL Server nacházejí na samostatných počítačích připojených přes síť.

Analogie: Tom se mapuje na klienta, kavárna se mapuje na SQL Server, domov a tržiště se mapují na vzdálená místa a mobilní síť se mapuje na protokol TCP/IP.

Poznámky ke konfiguraci: V aplikaci SQL Management Studio musí být pro připojení TCP/IP v části „Název serveru“ uvedena možnost „Počítač\Instance serveru“. SQL Server ve výchozím nastavení používá pro připojení TCP/IP port 1433.
Pojmenované Pipes
Nakonec si Tom přeje zelený čaj od své sousedky Sierry. Jsou na stejném fyzickém místě, jsou sousedé a komunikují prostřednictvím vnitrosítě. Podobně SQL Server poskytuje protokol Named Pipe, když jsou klient a server připojeni prostřednictvím místní sítě (LAN).

Analogie: Tom se mapuje na klienta, Sierra se mapuje na SQL Server, being neighbors se mapuje na LAN a intranetwork se mapuje na protokol Named Pipe.
Poznámky ke konfiguraci: Pojmenované kanály jsou ve výchozím nastavení zakázány a musí být povoleny pomocí Správce konfigurace SQL.
Co je TDS?
Nyní, když jsou tři typy architektury klient-server jasné, podívejme se na TDS:
- TDS je zkratka pro Tabular Data Stream.
- Všechny tři protokoly používají TDS pakety.
- TDS je zapouzdřen v síťových paketech, což umožňuje přenos dat z klientského počítače na server.
- TDS byl původně vyvinut společností Sybase a nyní je vlastněn společností Microsoft.
Následující tabulka porovnává tři protokoly připojení k SQL Serveru:
| vlastnost | Sdílená paměť | TCP / IP | Pojmenované Pipes |
|---|---|---|---|
| Rozsah sítě | Stejný stroj | Vzdálené (WAN/Internet) | Pouze LAN |
| Výchozí port | N / A | 1433 | 445 |
| Výkon | Nejrychlejší (bez síťových režijních nákladů) | Dobré (optimalizováno pro WAN) | Dobré (optimalizováno pro LAN) |
| Ve výchozím nastavení povoleno | Ano | Ano | Ne |
| Nejlepší případ použití | Lokální vývoj a testování | Vzdálený přístup k produkci | Důvěryhodná prostředí LAN |
Vzhledem k tomu, že síťovou komunikaci zajišťuje vrstva protokolu, dalším krokem v architektuře SQL Serveru je zpracování samotného dotazu. Zde přebírá roli relační engine.
Relační motor
Relační engine je také známý jako Query Processor. Obsahuje komponenty SQL Serveru, které určují, co má dotaz dělat a jak jej lze provést nejefektivněji. Je zodpovědný za provádění uživatelských dotazů vyžádáním dat z úložného enginu a zpracováním vrácených výsledků.
Jak je znázorněno na architektonickém diagramu, relační engine se skládá ze tří hlavních komponent:
CMD Parser
Data přijatá z protokolové vrstvy jsou předávána relačnímu enginu. CMD Parser je první komponenta, která přijímá data dotazu. Jeho hlavním úkolem je zkontrolovat dotaz na syntaktické a sémantické chyby a poté vygenerovat strom dotazů.

Syntaktická kontrola: Stejně jako každý jiný programovací jazyk má i SQL Server předdefinovanou sadu klíčových slov a gramatických pravidel. Do předdefinovaného seznamu klíčových slov patří SELECT, INSERT, UPDATE a mnoho dalších. CMD Parser ověřuje, zda vstup splňuje tato pravidla. Pokud se uživatelský vstup odchyluje od očekávané syntaxe, analyzátor vrátí chybu.
Příklad: Představte si Rusa, který vejde do japonské restaurace a objednává si v ruštině. Číšník rozumí pouze japonsky a nemůže objednávku zpracovat. Podobně, pokud uživatel zadá „SELECR“ místo „SELECT“, analyzátor CMD vrátí chybu, protože klíčové slovo nerozpozná.
Sémantická kontrola: Toto provádí normalizátor. Zkontroluje, zda názvy sloupců, názvy tabulek a další dotazované objekty ve schématu skutečně existují. Pokud existují, normalizátor je sváže s dotazem. Tento proces je také známý jako vázání (Binding). Pokud uživatelské dotazy obsahují zobrazení (VIEW), normalizátor jej nahradí interně uloženou definicí zobrazení (VIEW).
Příklad: Běh SELECT * from USER_ID by způsobilo, že by analyzátor během sémantické kontroly vyvolal chybu, pokud by tabulka USER_ID v databázi neexistuje.
Vytvořit strom dotazů: Tento krok generuje různé stromy provádění, které představují různé způsoby, jak lze dotaz spustit. Všechny stromy produkují stejný požadovaný výstup.
Optimalizátor
Optimalizátor vytvoří plán provedení pro dotaz uživatele. Tento plán určuje, jak bude dotaz proveden. Ne všechny dotazy jsou optimalizované. Optimalizace se vztahuje na příkazy DML (Data Modification Language), jako jsou SELECT, INSERT, DELETE a UPDATE. Příkazy DDL, jako jsou CREATE a ALTER, nejsou optimalizovány, ale jsou kompilovány do interního formuláře.

Cena dotazu se vypočítává na základě faktorů, jako je využití CPU, využití paměti a potřeby vstupu/výstupu. Úlohou optimalizátoru je najít nejlevnější a nejvýhodnější plán provedení, ne nutně ten absolutně nejlepší.
Příklad: Představte si, že si chcete otevřít online bankovní účet. V jedné bance vám to zabere maximálně 2 dny. Máte také seznam 20 dalších bank, které vám mohou, ale nemusí zabrat kratší dobu. Prohledávání všech 20 bank nemusí najít rychlejší možnost a samotné hledání stojí čas. Bylo by lepší zvolit první banku. Podobně SQL Optimizer používá vyčerpávající a heuristické algoritmy k minimalizaci doby běhu dotazu.
Optimalizátor vyhledává ve třech fázích:
Fáze 0: Hledání triviálního plánu
Toto je fáze před optimalizací. Pro některé dotazy existuje pouze jeden praktický plán, známý jako triviální plán. Není třeba dále hledat, protože jakékoli další hledání by našlo stejný plán provedení za příplatek.
Fáze 1: Hledání plánů zpracování transakcí
To zahrnuje vyhledávání jednoduchých i složitých plánů. Vyhledávání v jednoduchém plánu využívá statistickou analýzu dat sloupců a indexů, obvykle omezenou na jeden index na tabulku. Pokud není nalezen žádný jednoduchý plán, provede se složitější vyhledávání zahrnující více indexů na tabulku.
Fáze 2: Paralelní zpracování a optimalizace
Pokud předchozí strategie nevedou k adekvátnímu plánu, optimalizátor hledá možnosti paralelního zpracování na základě zpracovatelských schopností stroje. Pokud paralelní zpracování není možné, začíná závěrečná fáze optimalizace, která využívá všechny zbývající možnosti k nalezení nejlepšího možného plánu provedení.
Vykonavatel dotazu
Prováděcí modul dotazu volá metodu přístupu (Access Method) v úložném enginu (Storage Engine). Ta poskytuje plán provedení obsahující logiku pro načítání dat potřebnou pro provedení. Jakmile jsou data přijata ze úložného enginu, je výsledek publikován na vrstvě protokolu (Text Layer) a odeslán koncovému uživateli.

Poté, co relační engine určí, jak provést dotaz, úložný engine zpracovává operace s fyzickými daty. Tato vrstva spravuje, jak jsou data ukládána, ukládána do mezipaměti a načítána z disku.
Storage Engine
Storage Engine je zodpovědný za ukládání dat v úložném systému, jako je disk nebo SAN, a za jejich načítání v případě potřeby. Než se podíváme na komponenty Storage Engine, je důležité pochopit, jak jsou data fyzicky uložena.

Datové soubory a rozsahy
Datové soubory fyzicky ukládají data ve formě datových stránek, přičemž každá stránka má velikost 8 kB. Jedná se o nejmenší paměťovou jednotku v SQL ServerDatové stránky jsou logicky seskupeny do extentů. Žádnému objektu není přímo přiřazena samostatná stránka; údržba se místo toho provádí prostřednictvím extentů. Každá stránka má záhlaví stránky (96 bajtů), které obsahuje metadata, jako je typ stránky, číslo stránky, použité místo, volné místo a ukazatele na další a předchozí stránky.
Typy souborů

Primární soubor: Každá databáze obsahuje jeden primární soubor. Ukládá všechna důležitá data týkající se tabulek, pohledů, triggerů a dalších objektů. Přípona je obvykle .mdf, ale může mít jakoukoli příponu.
Sekundární soubor: Databáze může, ale nemusí obsahovat více sekundárních souborů. Ty jsou volitelné a obsahují data specifická pro uživatele. Přípona je obvykle .ndf, ale může mít libovolnou příponu.
Soubor protokolu: Také známé jako protokoly předzápisu. Přípona je .ldf. Soubory protokolů se používají pro správu transakcí, obnovu z nežádoucích instancí a provádění vrácení nepotvrzených transakcí.
Storage Engine má tři hlavní komponenty. Každá z nich hraje specifickou roli ve správě přístupu k datům a jejich integrity.
Způsob přístupu
Metoda přístupu funguje jako rozhraní mezi Query Executorem a Buffer Správce nebo protokoly transakcí. Samotný dotaz neprovádí, ale určuje jeho typ:
- Pokud je dotaz Příkaz SELECT (DML), je předáván do Buffer Manažer pro další zpracování.
- Pokud je dotaz Příkaz bez SELECT (DDL a DML), je předáván Správci transakcí. To zahrnuje většinou příkazy UPDATE, INSERT a DELETE.

Buffer Manažer
Jedno Buffer Správce spravuje základní funkce pro mezipaměť plánů, parsování dat a zpracování nečistých stránek.

Plán Cache
Stávající plán dotazů: Jedno Buffer Správce kontroluje, zda plán provedení existuje v uložené mezipaměti plánů. Pokud ano, použije se přímo plán dotazů uložený v mezipaměti a jeho přidružená datová mezipaměť.
Plán pro první použití mezipaměti: Pokud je plán spuštění prvního dotazu složitý, uloží se do mezipaměti plánů. To zajišťuje rychlejší dostupnost při příštím přijetí stejného dotazu SQL Serverem.
Analýza dat: Buffer Mezipaměť a úložiště dat
Jedno Buffer Správce poskytuje přístup k požadovaným datům. V závislosti na tom, zda se v mezipaměti nacházejí data, jsou možné dva přístupy:
Buffer Cache – Měkká analýza
Jedno Buffer Manažer hledá data v Buffer Mezipaměť. Pokud jsou data přítomna, Query Executor je použije přímo. To zlepšuje výkon, protože načítání dat z mezipaměti vyžaduje méně I/O operací ve srovnání s načítáním z diskového úložiště.

Ukládání dat – Hard parsování
Pokud data nejsou k dispozici v Buffer Mezipaměť, požadovaná data se vyhledávají v datovém úložišti na disku. Data se poté také ukládají do datové mezipaměti pro budoucí použití.

Správce transakcí
Správce transakcí se volá, když metoda přístupu zjistí, že dotaz není příkazem SELECT. Zajišťuje konzistenci a trvanlivost dat prostřednictvím několika dílčích komponent:

Správce protokolů
Správce protokolů uchovává track všech aktualizací provedených v systému prostřednictvím protokolů uložených v protokolech transakcí. Každý záznam protokolu obsahuje pořadové číslo protokolu spolu s ID transakce a záznamem o úpravě dat. Tento mechanismus tracks potvrzených a vrácených transakcí.
Správce zámku
Během transakce se související data v úložišti dostanou do uzamčeného stavu. Správce zámků tento proces zajišťuje a zajišťuje konzistenci a izolaci dat. Tyto vlastnosti jsou také známé jako ACID (Atomicita, konzistence, izolace, trvanlivost).
Proces provádění
Proces provedení probíhá v těchto krocích:
- Správce protokolů spustí protokolování a Správce zámků uzamkne související data.
- Kopie dat je uchovávána v Buffer Cache.
- Kopie dat, která mají být aktualizována, je uchovávána v protokolu. Buffera všechny události aktualizují data v datovém Buffer.
- Stránky, které ukládají upravená data, se nazývají Špinavé stránky.
Kontrolní body a protokolování předzápisu
Proces kontrolního bodu se spouští přibližně jednou za minutu a označí všechny nečisté stránky k zápisu na disk. Stránka je však nejprve odeslána na datovou stránku souboru protokolu z Buffer Protokolování. Tento mechanismus je známý jako protokolování s předzápisem. Nečisté stránky zůstávají v mezipaměti i po zapsání na disk.
líný Writer
Když SQL Server zaznamená velké zatížení a pro nové transakce je potřeba vyrovnávací paměť, uvolní z mezipaměti nečisté stránky. Writer pracuje s algoritmem LRU (Least Recently Used) pro čištění stránek z vyrovnávací paměti na disk.
Jak SQL Server zpracovává dotaz od začátku do konce
Pochopení každé vrstvy jednotlivě je cenné, ale vidět, jak spolupracují, objasňuje celkový obraz. Když klientská aplikace odešle SQL dotaz, dochází k následující sekvenci:
Jedno Protokolová vrstva přijme požadavek přes sdílenou paměť, TCP/IP nebo pojmenované kanály a zabalí ho do paketu TDS. Relační motor poté převezme kontrolu: analyzátor CMD zkontroluje syntaxi a sémantiku, optimalizátor vygeneruje nejlevnější plán provedení a Query Executor zahájí načítání dat.
Prováděcí modul dotazu volá Úložné motory Přístupová metoda, která směruje dotazy SELECT do Buffer Správce a dotazy na modifikaci pro Správce transakcí. Buffer Manažer kontroluje mezipaměť plánů a Buffer Nejprve se ukládá do mezipaměti (měkká analýza). Pokud data nejsou uložena do mezipaměti, provede se čtení z disku (tvrdá analýza). U operací zápisu koordinuje Správce transakcí Správce protokolů, Správce zámků a proces kontrolních bodů, aby byla zajištěna shoda s ACID.
Jakmile úložný engine vrátí požadovaná data, relační engine naformátuje výslednou sadu a protokolová vrstva ji doručí zpět klientské aplikaci prostřednictvím stejného protokolu TDS.
Jak vybrat správný protokol pro připojení k SQL Serveru
Výběr správného protokolu závisí na fyzickém vztahu mezi klientem a serverem a také na požadavcích na výkon.
Použít sdílenou paměť když klientská aplikace běží na stejném počítači jako SQL Server. Toto je nejrychlejší možnost, protože eliminuje veškeré síťové režijní náklady. Je ideální pro lokální vývoj, testování a nasazení na jednom počítači.
Použít TCP/IP když se klient a server nacházejí na různých počítačích připojených přes WAN nebo internet. Toto je nejčastěji používaný protokol v produkčním prostředí. SQL Server ve výchozím nastavení naslouchá na portu 1433 a tento protokol podporuje šifrovaná připojení přes TLS.
Použití pojmenovaných kanálů když se klient a server nacházejí ve stejné důvěryhodné síti LAN a prioritou je výkon v interních sítích. Pojmenované kanály jsou ve výchozím nastavení zakázány a musí být povoleny pomocí SQL Server Configuration Manager. V moderních nasazeních jsou méně běžné, ale pro starší intranetové aplikace jsou stále užitečné.