Seq2seq (Sequence to Sequence) Model med PyTorch
Hvad er NLP?
NLP eller Natural Language Processing er en af de populære grene af kunstig intelligens, der hjælper computere med at forstå, manipulere eller reagere på et menneske på deres naturlige sprog. NLP er motoren bag Google Translate som hjælper os med at forstå andre sprog.
Hvad er Seq2Seq?
Seq2Seq er en metode til koder-dekoder baseret maskinoversættelse og sprogbehandling, der kortlægger et input af sekvens til et output af sekvens med en tag og opmærksomhedsværdi. Ideen er at bruge 2 RNN'er, der vil arbejde sammen med en speciel token og forsøge at forudsige den næste tilstandssekvens fra den forrige sekvens.
Sådan forudsiger du sekvens fra den forrige sekvens
Følgende er trin til at forudsige sekvens fra den forrige sekvens med PyTorch.
Trin 1) Indlæsning af vores data
Til vores datasæt vil du bruge et datasæt fra Tabulator-separerede tosprogede sætningspar. Her vil jeg bruge det engelsk til indonesiske datasæt. Du kan vælge hvad som helst, men husk at ændre filnavnet og mappen i koden.
from __future__ import unicode_literals, print_function, division
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import numpy as np
import pandas as pd
import os
import re
import random
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
Trin 2) Dataforberedelse
Du kan ikke bruge datasættet direkte. Du skal opdele sætningerne i ord og konvertere dem til One-Hot Vector. Hvert ord vil blive unikt indekseret i Lang-klassen for at lave en ordbog. Lang-klassen gemmer hver sætning og deler den ord for ord med addSentence. Opret derefter en ordbog ved at indeksere hvert ukendt ord for Sequence til sekvensmodeller.
SOS_token = 0
EOS_token = 1
MAX_LENGTH = 20
#initialize Lang Class
class Lang:
def __init__(self):
#initialize containers to hold the words and corresponding index
self.word2index = {}
self.word2count = {}
self.index2word = {0: "SOS", 1: "EOS"}
self.n_words = 2 # Count SOS and EOS
#split a sentence into words and add it to the container
def addSentence(self, sentence):
for word in sentence.split(' '):
self.addWord(word)
#If the word is not in the container, the word will be added to it,
#else, update the word counter
def addWord(self, word):
if word not in self.word2index:
self.word2index[word] = self.n_words
self.word2count[word] = 1
self.index2word[self.n_words] = word
self.n_words += 1
else:
self.word2count[word] += 1
Lang-klassen er en klasse, der vil hjælpe os med at lave en ordbog. For hvert sprog vil hver sætning blive opdelt i ord og derefter tilføjet til beholderen. Hver beholder vil gemme ordene i det relevante indeks, tælle ordet og tilføje indekset for ordet, så vi kan bruge det til at finde indekset for et ord eller finde et ord fra dets indeks.
Fordi vores data er adskilt af TAB, skal du bruge pandaer som vores dataindlæser. Pandas vil læse vores data som dataFrame og opdele dem i vores kilde- og målsætning. For hver sætning du har,
- du vil normalisere det til små bogstaver,
- fjern alle ikke-tegn
- konvertere til ASCII fra Unicode
- del sætningerne op, så du har hvert ord i sig.
#Normalize every sentence
def normalize_sentence(df, lang):
sentence = df[lang].str.lower()
sentence = sentence.str.replace('[^A-Za-z\s]+', '')
sentence = sentence.str.normalize('NFD')
sentence = sentence.str.encode('ascii', errors='ignore').str.decode('utf-8')
return sentence
def read_sentence(df, lang1, lang2):
sentence1 = normalize_sentence(df, lang1)
sentence2 = normalize_sentence(df, lang2)
return sentence1, sentence2
def read_file(loc, lang1, lang2):
df = pd.read_csv(loc, delimiter='\t', header=None, names=[lang1, lang2])
return df
def process_data(lang1,lang2):
df = read_file('text/%s-%s.txt' % (lang1, lang2), lang1, lang2)
print("Read %s sentence pairs" % len(df))
sentence1, sentence2 = read_sentence(df, lang1, lang2)
source = Lang()
target = Lang()
pairs = []
for i in range(len(df)):
if len(sentence1[i].split(' ')) < MAX_LENGTH and len(sentence2[i].split(' ')) < MAX_LENGTH:
full = [sentence1[i], sentence2[i]]
source.addSentence(sentence1[i])
target.addSentence(sentence2[i])
pairs.append(full)
return source, target, pairs
En anden nyttig funktion, som du vil bruge, er at konvertere parrene til Tensor. Dette er meget vigtigt, fordi vores netværk kun læser tensortypedata. Det er også vigtigt, fordi det er den del, der i hver ende af sætningen vil være et token, der fortæller netværket, at inputtet er færdigt. For hvert ord i sætningen vil den få indekset fra det relevante ord i ordbogen og tilføje et symbol i slutningen af sætningen.
def indexesFromSentence(lang, sentence):
return [lang.word2index[word] for word in sentence.split(' ')]
def tensorFromSentence(lang, sentence):
indexes = indexesFromSentence(lang, sentence)
indexes.append(EOS_token)
return torch.tensor(indexes, dtype=torch.long, device=device).view(-1, 1)
def tensorsFromPair(input_lang, output_lang, pair):
input_tensor = tensorFromSentence(input_lang, pair[0])
target_tensor = tensorFromSentence(output_lang, pair[1])
return (input_tensor, target_tensor)
Seq2Seq model

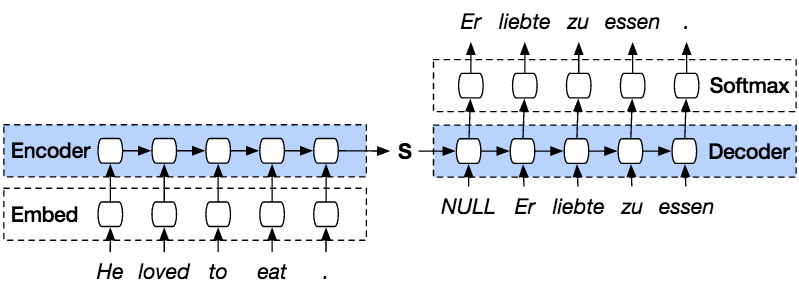
PyTorch Seq2seq model er en slags model, der bruger PyTorch encoder dekoder oven på modellen. Indkoderen vil kode sætningen ord for ord til en indekseret af ordforråd eller kendte ord med indeks, og dekoderen vil forudsige outputtet af det kodede input ved at afkode inputtet i rækkefølge og vil forsøge at bruge det sidste input som det næste input, hvis er det muligt. Med denne metode er det også muligt at forudsige det næste input for at skabe en sætning. Hver sætning vil blive tildelt et token for at markere slutningen af sekvensen. Ved slutningen af forudsigelsen vil der også være et token til at markere slutningen af outputtet. Så fra koderen vil den sende en tilstand til dekoderen for at forudsige outputtet.

Encoderen vil kode vores input sætning ord for ord i rækkefølge, og i sidste ende vil der være en token til at markere slutningen af en sætning. Indkoderen består af et Embedding-lag og et GRU-lag. Indlejringslaget er en opslagstabel, der gemmer indlejringen af vores input i en ordbog med ord i fast størrelse. Det vil blive sendt til et GRU-lag. GRU-lag er en Gated Recurrent Unit, der består af flere lag type RNN som vil beregne det sekvenserede input. Dette lag vil beregne den skjulte tilstand fra den forrige og opdatere nulstillingen, opdateringen og nye porte.

Dekoderen vil afkode input fra encoder output. Det vil forsøge at forudsige det næste output og forsøge at bruge det som det næste input, hvis det er muligt. Dekoderen består af et indlejringslag, GRU-lag og et lineært lag. Indlejringslaget vil lave en opslagstabel for outputtet og overføre det til et GRU-lag for at beregne den forudsagte outputtilstand. Derefter vil et lineært lag hjælpe med at beregne aktiveringsfunktionen for at bestemme den sande værdi af det forudsagte output.
class Encoder(nn.Module):
def __init__(self, input_dim, hidden_dim, embbed_dim, num_layers):
super(Encoder, self).__init__()
#set the encoder input dimesion , embbed dimesion, hidden dimesion, and number of layers
self.input_dim = input_dim
self.embbed_dim = embbed_dim
self.hidden_dim = hidden_dim
self.num_layers = num_layers
#initialize the embedding layer with input and embbed dimention
self.embedding = nn.Embedding(input_dim, self.embbed_dim)
#intialize the GRU to take the input dimetion of embbed, and output dimention of hidden and
#set the number of gru layers
self.gru = nn.GRU(self.embbed_dim, self.hidden_dim, num_layers=self.num_layers)
def forward(self, src):
embedded = self.embedding(src).view(1,1,-1)
outputs, hidden = self.gru(embedded)
return outputs, hidden
class Decoder(nn.Module):
def __init__(self, output_dim, hidden_dim, embbed_dim, num_layers):
super(Decoder, self).__init__()
#set the encoder output dimension, embed dimension, hidden dimension, and number of layers
self.embbed_dim = embbed_dim
self.hidden_dim = hidden_dim
self.output_dim = output_dim
self.num_layers = num_layers
# initialize every layer with the appropriate dimension. For the decoder layer, it will consist of an embedding, GRU, a Linear layer and a Log softmax activation function.
self.embedding = nn.Embedding(output_dim, self.embbed_dim)
self.gru = nn.GRU(self.embbed_dim, self.hidden_dim, num_layers=self.num_layers)
self.out = nn.Linear(self.hidden_dim, output_dim)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, input, hidden):
# reshape the input to (1, batch_size)
input = input.view(1, -1)
embedded = F.relu(self.embedding(input))
output, hidden = self.gru(embedded, hidden)
prediction = self.softmax(self.out(output[0]))
return prediction, hidden
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device, MAX_LENGTH=MAX_LENGTH):
super().__init__()
#initialize the encoder and decoder
self.encoder = encoder
self.decoder = decoder
self.device = device
def forward(self, source, target, teacher_forcing_ratio=0.5):
input_length = source.size(0) #get the input length (number of words in sentence)
batch_size = target.shape[1]
target_length = target.shape[0]
vocab_size = self.decoder.output_dim
#initialize a variable to hold the predicted outputs
outputs = torch.zeros(target_length, batch_size, vocab_size).to(self.device)
#encode every word in a sentence
for i in range(input_length):
encoder_output, encoder_hidden = self.encoder(source[i])
#use the encoder’s hidden layer as the decoder hidden
decoder_hidden = encoder_hidden.to(device)
#add a token before the first predicted word
decoder_input = torch.tensor([SOS_token], device=device) # SOS
#topk is used to get the top K value over a list
#predict the output word from the current target word. If we enable the teaching force, then the #next decoder input is the next word, else, use the decoder output highest value.
for t in range(target_length):
decoder_output, decoder_hidden = self.decoder(decoder_input, decoder_hidden)
outputs[t] = decoder_output
teacher_force = random.random() < teacher_forcing_ratio
topv, topi = decoder_output.topk(1)
input = (target[t] if teacher_force else topi)
if(teacher_force == False and input.item() == EOS_token):
break
return outputs
Trin 3) Træning af modellen
Træningsprocessen i Seq2seq-modeller starter med at konvertere hvert par sætninger til Tensorer fra deres Lang-indeks. Vores sekvens til sekvens model vil bruge SGD som optimizer og NLLLoss funktion til at beregne tabene. Træningsprocessen begynder med at fodre parret af en sætning til modellen for at forudsige det korrekte output. Ved hvert trin vil outputtet fra modellen blive beregnet med de sande ord for at finde tabene og opdatere parametrene. Så fordi du vil bruge 75000 iterationer, vil vores sekvens-til-sekvens-model generere tilfældige 75000 par fra vores datasæt.
teacher_forcing_ratio = 0.5
def clacModel(model, input_tensor, target_tensor, model_optimizer, criterion):
model_optimizer.zero_grad()
input_length = input_tensor.size(0)
loss = 0
epoch_loss = 0
# print(input_tensor.shape)
output = model(input_tensor, target_tensor)
num_iter = output.size(0)
print(num_iter)
#calculate the loss from a predicted sentence with the expected result
for ot in range(num_iter):
loss += criterion(output[ot], target_tensor[ot])
loss.backward()
model_optimizer.step()
epoch_loss = loss.item() / num_iter
return epoch_loss
def trainModel(model, source, target, pairs, num_iteration=20000):
model.train()
optimizer = optim.SGD(model.parameters(), lr=0.01)
criterion = nn.NLLLoss()
total_loss_iterations = 0
training_pairs = [tensorsFromPair(source, target, random.choice(pairs))
for i in range(num_iteration)]
for iter in range(1, num_iteration+1):
training_pair = training_pairs[iter - 1]
input_tensor = training_pair[0]
target_tensor = training_pair[1]
loss = clacModel(model, input_tensor, target_tensor, optimizer, criterion)
total_loss_iterations += loss
if iter % 5000 == 0:
avarage_loss= total_loss_iterations / 5000
total_loss_iterations = 0
print('%d %.4f' % (iter, avarage_loss))
torch.save(model.state_dict(), 'mytraining.pt')
return model
Trin 4) Test modellen
Evalueringsprocessen for Seq2seq PyTorch er at kontrollere modellens output. Hvert par af sekvens til sekvens-modeller vil blive indført i modellen og generere de forudsagte ord. Derefter vil du se den højeste værdi ved hvert output for at finde det korrekte indeks. Og i sidste ende vil du sammenligne for at se vores modelforudsigelse med den sande sætning
def evaluate(model, input_lang, output_lang, sentences, max_length=MAX_LENGTH):
with torch.no_grad():
input_tensor = tensorFromSentence(input_lang, sentences[0])
output_tensor = tensorFromSentence(output_lang, sentences[1])
decoded_words = []
output = model(input_tensor, output_tensor)
# print(output_tensor)
for ot in range(output.size(0)):
topv, topi = output[ot].topk(1)
# print(topi)
if topi[0].item() == EOS_token:
decoded_words.append('<EOS>')
break
else:
decoded_words.append(output_lang.index2word[topi[0].item()])
return decoded_words
def evaluateRandomly(model, source, target, pairs, n=10):
for i in range(n):
pair = random.choice(pairs)
print(‘source {}’.format(pair[0]))
print(‘target {}’.format(pair[1]))
output_words = evaluate(model, source, target, pair)
output_sentence = ' '.join(output_words)
print(‘predicted {}’.format(output_sentence))
Lad os nu starte vores træning med Seq to Seq, med antallet af iterationer på 75000 og antallet af RNN-lag på 1 med den skjulte størrelse på 512.
lang1 = 'eng'
lang2 = 'ind'
source, target, pairs = process_data(lang1, lang2)
randomize = random.choice(pairs)
print('random sentence {}'.format(randomize))
#print number of words
input_size = source.n_words
output_size = target.n_words
print('Input : {} Output : {}'.format(input_size, output_size))
embed_size = 256
hidden_size = 512
num_layers = 1
num_iteration = 100000
#create encoder-decoder model
encoder = Encoder(input_size, hidden_size, embed_size, num_layers)
decoder = Decoder(output_size, hidden_size, embed_size, num_layers)
model = Seq2Seq(encoder, decoder, device).to(device)
#print model
print(encoder)
print(decoder)
model = trainModel(model, source, target, pairs, num_iteration)
evaluateRandomly(model, source, target, pairs)
Som du kan se, matcher vores forudsagte sætning ikke særlig godt, så for at få højere nøjagtighed skal du træne med meget mere data og forsøge at tilføje flere iterationer og antal lag ved hjælp af Sequence til sekvensindlæring.
random sentence ['tom is finishing his work', 'tom sedang menyelesaikan pekerjaannya']
Input : 3551 Output : 4253
Encoder(
(embedding): Embedding(3551, 256)
(gru): GRU(256, 512)
)
Decoder(
(embedding): Embedding(4253, 256)
(gru): GRU(256, 512)
(out): Linear(in_features=512, out_features=4253, bias=True)
(softmax): LogSoftmax()
)
Seq2Seq(
(encoder): Encoder(
(embedding): Embedding(3551, 256)
(gru): GRU(256, 512)
)
(decoder): Decoder(
(embedding): Embedding(4253, 256)
(gru): GRU(256, 512)
(out): Linear(in_features=512, out_features=4253, bias=True)
(softmax): LogSoftmax()
)
)
5000 4.0906
10000 3.9129
15000 3.8171
20000 3.8369
25000 3.8199
30000 3.7957
35000 3.8037
40000 3.8098
45000 3.7530
50000 3.7119
55000 3.7263
60000 3.6933
65000 3.6840
70000 3.7058
75000 3.7044
> this is worth one million yen
= ini senilai satu juta yen
< tom sangat satu juta yen <EOS>
> she got good grades in english
= dia mendapatkan nilai bagus dalam bahasa inggris
< tom meminta nilai bagus dalam bahasa inggris <EOS>
> put in a little more sugar
= tambahkan sedikit gula
< tom tidak <EOS>
> are you a japanese student
= apakah kamu siswa dari jepang
< tom kamu memiliki yang jepang <EOS>
> i apologize for having to leave
= saya meminta maaf karena harus pergi
< tom tidak maaf karena harus pergi ke
> he isnt here is he
= dia tidak ada di sini kan
< tom tidak <EOS>
> speaking about trips have you ever been to kobe
= berbicara tentang wisata apa kau pernah ke kobe
< tom tidak <EOS>
> tom bought me roses
= tom membelikanku bunga mawar
< tom tidak bunga mawar <EOS>
> no one was more surprised than tom
= tidak ada seorangpun yang lebih terkejut dari tom
< tom ada orang yang lebih terkejut <EOS>
> i thought it was true
= aku kira itu benar adanya
< tom tidak <EOS>