ईटीएल (पूर्वtracडेटा वेयरहाउस में (ट्रांसफॉर्म, और लोड) प्रक्रिया
स्मार्ट सारांश
ईटीएल (पूर्वtracडेटा वेयरहाउस में डेटा स्थानांतरण, रूपांतरण और लोडिंग प्रक्रिया (t, Transform, and Load) कई विषम स्रोतों से एक केंद्रीकृत भंडार में डेटा की व्यवस्थित आवाजाही का वर्णन करती है। यह संरचित प्रक्रियाओं के माध्यम से डेटा की स्थिरता, सटीकता और विश्लेषण के लिए तत्परता सुनिश्चित करती है।tracपरिवर्तन, रूपांतरण और अनुकूलित लोडिंग तंत्र।

ETL क्या है?
ईटीएल यह एक ऐसी प्रक्रिया है जो पूर्वtracयह विभिन्न स्रोत प्रणालियों से डेटा एकत्र करता है, फिर डेटा को रूपांतरित करता है (जैसे गणनाएँ लागू करना, डेटा को जोड़ना आदि), और अंत में डेटा को डेटा वेयरहाउस सिस्टम में लोड करता है। ईटीएल का पूरा नाम एक्सपीरियंस्ड डेटा है।tract, ट्रांसफॉर्म और लोड।
यह सोचना लुभावना लगता है कि डेटा वेयरहाउस बनाना केवल कुछ अतिरिक्त कार्यों को शामिल करता है।tracकई स्रोतों से डेटा एकत्र करके उसे डेटाबेस में लोड करना। हालांकि, वास्तविकता में इसके लिए एक जटिल ईटीएल प्रक्रिया की आवश्यकता होती है। ईटीएल प्रक्रिया में डेवलपर्स, विश्लेषकों, परीक्षकों और शीर्ष अधिकारियों सहित विभिन्न हितधारकों से सक्रिय इनपुट की आवश्यकता होती है और यह तकनीकी रूप से चुनौतीपूर्ण है।
निर्णयकर्ताओं के लिए एक उपयोगी उपकरण के रूप में अपनी उपयोगिता बनाए रखने के लिए, डेटा वेयरहाउस सिस्टम को व्यावसायिक परिवर्तनों के साथ बदलना आवश्यक है। ईटीएल (इलेक्ट्रॉनिक, ट्रांसफॉर्मर टाइम मैनेजमेंट) डेटा वेयरहाउस सिस्टम की एक नियमित गतिविधि (दैनिक, साप्ताहिक या मासिक) है और इसे चुस्त, स्वचालित और सुव्यवस्थित होना चाहिए।
आपको ETL की आवश्यकता क्यों है?
संगठन में ETL को अपनाने के कई कारण हैं:
- यह कंपनियों को महत्वपूर्ण व्यावसायिक निर्णय लेने के लिए अपने व्यावसायिक डेटा का विश्लेषण करने में मदद करता है।
- ट्रांजैक्शनल डेटाबेस उन जटिल व्यावसायिक प्रश्नों का उत्तर नहीं दे सकते जिनका उत्तर ईटीएल उदाहरण द्वारा दिया जा सकता है।
- डेटा वेयरहाउस एक साझा डेटा भंडार प्रदान करता है।
- ETL विभिन्न स्रोतों से डेटा को डेटा वेयरहाउस में स्थानांतरित करने की एक विधि प्रदान करता है।
- डेटा स्रोतों में बदलाव होने पर, डेटा वेयरहाउस स्वचालित रूप से अपडेट हो जाएगा।
- एक सुव्यवस्थित और दस्तावेजीकृत ईटीएल प्रणाली डेटा वेयरहाउस परियोजना की सफलता के लिए लगभग अनिवार्य है।
- डेटा रूपांतरण, एकत्रीकरण और गणना नियमों के सत्यापन की अनुमति दें।
- ईटीएल प्रक्रिया स्रोत और लक्ष्य प्रणाली के बीच नमूना डेटा की तुलना करने की अनुमति देती है।
- ईटीएल प्रक्रिया जटिल रूपांतरण कर सकती है और डेटा को संग्रहीत करने के लिए अतिरिक्त क्षेत्र की आवश्यकता होती है।
- ईटीएल डेटा को डेटा वेयरहाउस में माइग्रेट करने में मदद करता है, विभिन्न प्रारूपों और प्रकारों को एक सुसंगत प्रणाली में परिवर्तित करता है।
- ETL, लक्ष्य डाटाबेस में स्रोत डाटा तक पहुंचने और उसमें परिवर्तन करने के लिए एक पूर्वनिर्धारित प्रक्रिया है।
- डेटा वेयरहाउस में ईटीएल व्यवसाय के लिए गहन ऐतिहासिक संदर्भ प्रदान करता है।
- यह उत्पादकता बढ़ाने में मदद करता है क्योंकि यह तकनीकी कौशल की आवश्यकता के बिना डेटा को कोडित और पुन: उपयोग करता है।
ईटीएल के महत्व को स्पष्ट रूप से समझने के बाद, आइए उस तीन-चरणीय प्रक्रिया में गहराई से उतरें जो इसे कारगर बनाती है।
डेटा वेयरहाउस में ईटीएल प्रक्रिया
ETL एक 3-चरणीय प्रक्रिया है
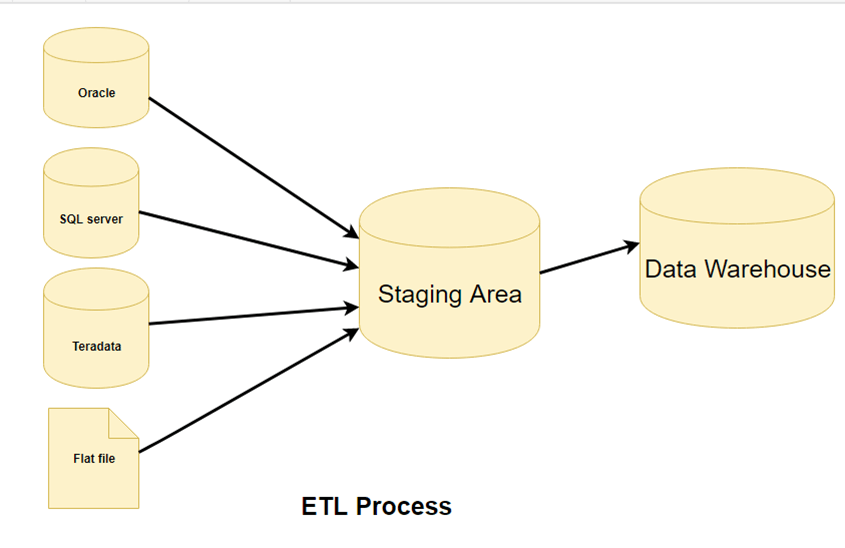
चरण 1) पूर्वtracउत्पादन
ईटीएल आर्किटेक्चर के इस चरण में, डेटा को बाहर निकाला जाता है।tracस्रोत सिस्टम से डेटा को स्टेजिंग एरिया में स्थानांतरित किया जाता है। यदि कोई परिवर्तन आवश्यक हो, तो वह स्टेजिंग एरिया में ही किया जाता है ताकि स्रोत सिस्टम के प्रदर्शन में कोई गिरावट न आए। साथ ही, यदि दूषित डेटा को सीधे स्रोत से डेटा वेयरहाउस डेटाबेस में कॉपी किया जाता है, तो रोलबैक एक चुनौती बन जाएगा। स्टेजिंग एरिया पूर्व-निर्धारित डेटा को मान्य करने का अवसर प्रदान करता है।tracडेटा वेयरहाउस में जाने से पहले डेटा को संसाधित किया जाता है।
डेटा वेयरहाउस को उन प्रणालियों को एकीकृत करने की आवश्यकता है जिनमें अलग-अलग डीबीएमएस, हार्डवेयर आदि हैं। Operaसंचार प्रणालियाँ और संचार प्रोटोकॉल। स्रोतों में मेनफ्रेम जैसे पुराने एप्लिकेशन, अनुकूलित एप्लिकेशन, एटीएम जैसे संपर्क उपकरण, कॉल स्विच, टेक्स्ट फाइलें, स्प्रेडशीट, ईआरपी, विक्रेताओं और भागीदारों से प्राप्त डेटा आदि शामिल हो सकते हैं।
इसलिए, डेटा को एक्सपोर्ट करने से पहले एक लॉजिकल डेटा मैप की आवश्यकता होती है।tracडेटा को भौतिक रूप से लोड और लोड किया जाता है। यह डेटा मैप स्रोतों और लक्ष्य डेटा के बीच संबंध का वर्णन करता है।
तीन डेटा एक्सtracविधियाँ:
- पूर्ण पूर्वtracउत्पादन
- आंशिक पूर्वtracबिना अपडेट नोटिफिकेशन के।
- आंशिक पूर्वtracअपडेट नोटिफिकेशन के साथ
उपयोग की गई विधि के बावजूद,tracइस प्रक्रिया से स्रोत प्रणालियों के प्रदर्शन और प्रतिक्रिया समय पर कोई प्रभाव नहीं पड़ना चाहिए। ये स्रोत प्रणालियाँ लाइव प्रोडक्शन डेटाबेस हैं। किसी भी प्रकार की धीमी गति या रुकावट कंपनी के मुनाफे पर असर डाल सकती है।
एक्स के दौरान कुछ सत्यापन किए जाते हैंtracमोर्चे:
- स्रोत डेटा के साथ रिकॉर्ड का मिलान करें
- सुनिश्चित करें कि कोई स्पैम/अवांछित डेटा लोड न हो।
- डेटा प्रकार की जांच
- सभी प्रकार के डुप्लिकेट/खंडित डेटा को हटाएँ
- जांच लें कि सभी चाबियां सही जगह पर हैं या नहीं।
चरण 2) परिवर्तन
डेटा पूर्वtracस्रोत सर्वर से प्राप्त डेटा कच्चा होता है और अपने मूल रूप में उपयोग करने योग्य नहीं होता। इसलिए, इसे शुद्ध करना, मैप करना और रूपांतरित करना आवश्यक है। वास्तव में, यही वह महत्वपूर्ण चरण है जहाँ ETL प्रक्रिया मूल्य जोड़ती है और डेटा को इस प्रकार परिवर्तित करती है जिससे उपयोगी BI रिपोर्ट तैयार की जा सकें।
यह महत्वपूर्ण ईटीएल अवधारणाओं में से एक है जहां आप पूर्व डेटा पर कार्यों का एक सेट लागू करते हैं।tracऐसा डेटा जिसे किसी रूपांतरण की आवश्यकता नहीं होती, उसे कहा जाता है। प्रत्यक्ष चाल or पास-थ्रू डेटा.
रूपांतरण चरण में, आप डेटा पर अनुकूलित संक्रियाएँ कर सकते हैं। उदाहरण के लिए, यदि उपयोगकर्ता बिक्री राजस्व का योग चाहता है जो डेटाबेस में मौजूद नहीं है। या यदि किसी तालिका में पहला नाम और अंतिम नाम अलग-अलग कॉलम में हैं, तो उन्हें लोड करने से पहले संयोजित करना संभव है।

निम्नलिखित डेटा हैं Integrity समस्याएं:
- एक ही व्यक्ति के नाम की अलग-अलग वर्तनी, जैसे जॉन, जॉन आदि।
- किसी कंपनी के नाम को दर्शाने के कई तरीके हैं, जैसे Google, Google Inc.
- क्लीवलैंड और क्लीवलैंड जैसे अलग-अलग नामों का प्रयोग।
- ऐसा भी हो सकता है कि एक ही ग्राहक के लिए विभिन्न एप्लिकेशन द्वारा अलग-अलग खाता संख्याएँ उत्पन्न की जाएँ।
- कुछ मामलों में, आवश्यक डेटा वाली फाइलें खाली रह जाती हैं।
- गलत उत्पाद को पीओएस पर एकत्र किया गया, क्योंकि मैन्युअल प्रविष्टि से गलतियाँ हो सकती हैं।
इस चरण के दौरान सत्यापन किया जाता है
- फ़िल्टरिंग – लोड करने के लिए केवल कुछ कॉलम चुनें
- डेटा मानकीकरण के लिए नियमों और लुकअप तालिकाओं का उपयोग करना
- वर्ण सेट रूपांतरण और एनकोडिंग प्रबंधन
- माप की इकाइयों का रूपांतरण, जैसे दिनांक और समय का रूपांतरण, मुद्रा का रूपांतरण, संख्यात्मक रूपांतरण आदि।
- डेटा सीमा सत्यापन जांच। उदाहरण के लिए, आयु दो अंकों से अधिक नहीं हो सकती।
- स्टेजिंग क्षेत्र से मध्यवर्ती तालिकाओं तक डेटा प्रवाह सत्यापन।
- आवश्यक फ़ील्ड को रिक्त नहीं छोड़ा जाना चाहिए.
- सफाई (उदाहरण के लिए, मानचित्र)ping (NULL को 0 पर सेट करें या लिंग (पुरुष को "M" और महिला को "F" पर सेट करें, इत्यादि)
- एक कॉलम को कई कॉलम में विभाजित करें और कई कॉलम को एक कॉलम में मर्ज करें।
- पंक्तियों और स्तंभों को स्थानांतरित करना,
- डेटा मर्ज करने के लिए लुकअप का उपयोग करें
- किसी भी जटिल डेटा सत्यापन का उपयोग करना (उदाहरण के लिए, यदि किसी पंक्ति में पहले दो कॉलम खाली हैं, तो यह स्वचालित रूप से उस पंक्ति को प्रसंस्करण से अस्वीकार कर देता है)
चरण 3) लोड हो रहा है
लक्ष्य डेटा वेयरहाउस डेटाबेस में डेटा लोड करना ईटीएल प्रक्रिया का अंतिम चरण है। एक सामान्य डेटा वेयरहाउस में, अपेक्षाकृत कम समय (रातों) में भारी मात्रा में डेटा लोड करना होता है। इसलिए, प्रदर्शन के लिहाज़ से लोड प्रक्रिया को अनुकूलित किया जाना चाहिए।
लोड विफल होने की स्थिति में, डेटा अखंडता को खोए बिना विफलता के बिंदु से पुनः आरंभ करने के लिए पुनर्प्राप्ति तंत्र को कॉन्फ़िगर किया जाना चाहिए। डेटा वेयरहाउस प्रशासकों को सर्वर के मौजूदा प्रदर्शन के अनुसार लोड की निगरानी, पुनः आरंभ और रद्द करने की आवश्यकता होती है।
लोडिंग के प्रकार:
- प्रारंभिक भार — डेटा वेयरहाउस की सभी तालिकाओं को भरना
- वृद्धिशील भार — आवश्यकतानुसार समय-समय पर निरंतर परिवर्तन लागू करना।
- पूर्ण ताज़ा करें - एक या अधिक तालिकाओं की सामग्री को मिटाना और नए डेटा के साथ पुनः लोड करना।
लोड सत्यापन
- सुनिश्चित करें कि कुंजी फ़ील्ड डेटा न तो गायब है और न ही शून्य है.
- लक्ष्य तालिकाओं के आधार पर मॉडलिंग दृश्यों का परीक्षण करें.
- संयुक्त मानों और परिकलित मापों की जाँच करें।
- डेटा की जांच डाइमेंशन टेबल के साथ-साथ हिस्ट्री टेबल में भी की जाती है।
- लोड किए गए तथ्य और आयाम तालिका पर BI रिपोर्ट की जाँच करें।
ईटीएल पाइपलाइनिंग और समानांतर प्रसंस्करण
ईटीएल पाइपलाइनिंग पूर्व की अनुमति देती हैtracपरिवर्तन, रूपांतरण और लोडिंग होने के लिए एक साथ क्रमिक रूप से करने के बजाय। जैसे ही डेटा का एक हिस्सा समाप्त हो जाता हैtracटेड, यह रूपांतरित और लोड हो गया है जबकि नया डेटा एक्सtracयह सिलसिला जारी है। समानांतर प्रसंस्करण इससे प्रदर्शन में काफी सुधार होता है, डाउनटाइम कम होता है और सिस्टम संसाधनों का अधिकतम उपयोग सुनिश्चित होता है।
यह समानांतर प्रसंस्करण इसके लिए आवश्यक है वास्तविक समय विश्लेषिकीबड़े पैमाने पर डेटा एकीकरण और क्लाउड-आधारित ईटीएल सिस्टम। ओवरलैप के कारणping कार्यों के लिए पाइपलाइन आधारित ईटीएल आधुनिक उद्यमों के लिए तेज़ डेटा प्रवाह, उच्च दक्षता और अधिक सुसंगत डेटा वितरण सुनिश्चित करता है।
एआई आधुनिक ईटीएल पाइपलाइनों को कैसे बेहतर बनाता है?
Artificial Intelligence revolutयह तकनीक डेटा पाइपलाइनों को अनुकूलनीय, बुद्धिमान और स्व-अनुकूलित बनाकर ईटीएल को उन्नत बनाती है। एआई एल्गोरिदम मैन्युअल कॉन्फ़िगरेशन के बिना स्वचालित रूप से स्कीमा मैप कर सकते हैं, विसंगतियों का पता लगा सकते हैं और रूपांतरण नियमों की भविष्यवाणी कर सकते हैं। इससे ईटीएल वर्कफ़्लो डेटा गुणवत्ता बनाए रखते हुए विकसित हो रही डेटा संरचनाओं को आसानी से संभाल सकते हैं।
आधुनिक एआई-संवर्धित ईटीएल प्लेटफॉर्म स्वचालित फीचर इंजीनियरिंग के लिए ऑटोएमएल जैसी तकनीकों और एनएलपी-संचालित स्कीमा मैप का लाभ उठाते हैं।ping यह फ़ील्ड्स के बीच अर्थ संबंधी संबंधों को समझता है, और इसमें ऐसे विसंगति पहचान एल्गोरिदम शामिल हैं जो वास्तविक समय में डेटा गुणवत्ता संबंधी समस्याओं की पहचान करते हैं। ये क्षमताएं ईटीएल विकास और रखरखाव में पारंपरिक रूप से आवश्यक मैन्युअल प्रयास को काफी हद तक कम कर देती हैं।
मशीन लर्निंग यह परफॉर्मेंस ट्यूनिंग को बेहतर बनाता है, जिससे तेज़ और अधिक सटीक डेटा इंटीग्रेशन सुनिश्चित होता है। ऑटोमेशन और प्रेडिक्टिव इंटेलिजेंस को शामिल करके, AI-संचालित ETL वास्तविक समय की जानकारी प्रदान करता है और क्लाउड और हाइब्रिड डेटा इकोसिस्टम में अधिक दक्षता लाता है।
ऊपर बताए गए सिद्धांतों को लागू करने के लिए, संगठन विशेषीकृत ईटीएल टूल्स पर निर्भर करते हैं। बाजार में उपलब्ध कुछ प्रमुख विकल्प यहां दिए गए हैं।
ईटीएल उपकरण
कई हैं ETL उपकरण बाजार में उपलब्ध हैं। इनमें से कुछ प्रमुख हैं:
1. मार्कलॉजिक:
MarkLogic एक डेटा वेयरहाउसिंग समाधान है जो कई एंटरप्राइज़ सुविधाओं का उपयोग करके डेटा एकीकरण को आसान और तेज़ बनाता है। यह दस्तावेज़, संबंध और मेटाडेटा जैसे विभिन्न प्रकार के डेटा पर क्वेरी कर सकता है।
https://www.marklogic.com/product/getting-started/
2. Oracle:
Oracle यह उद्योग जगत का अग्रणी डेटाबेस है। यह ऑन-प्रिमाइसेस और क्लाउड दोनों के लिए डेटा वेयरहाउस समाधानों की एक विस्तृत श्रृंखला प्रदान करता है। यह परिचालन दक्षता बढ़ाकर ग्राहक अनुभव को बेहतर बनाने में मदद करता है।
https://www.oracle.com/index.html
3. Amazon लालShift:
Amazon रेडशिफ्ट एक डेटा वेयरहाउस टूल है। यह मानक प्रक्रियाओं का उपयोग करके सभी प्रकार के डेटा का विश्लेषण करने के लिए एक सरल और किफायती उपकरण है। एसक्यूएल और मौजूदा BI उपकरण। यह संरचित डेटा के पेटाबाइट्स के खिलाफ जटिल क्वेरी चलाने की भी अनुमति देता है।
https://aws.amazon.com/redshift/?nc2=h_m1
यहाँ उपयोगी की एक पूरी सूची है डेटा वेयरहाउस टूल्स।
ईटीएल प्रक्रिया के लिए सर्वोत्तम अभ्यास
ईटीएल प्रक्रिया के चरणों के लिए निम्नलिखित सर्वोत्तम अभ्यास हैं:
- कभी भी सारा डेटा साफ़ करने का प्रयास न करें:
हर संगठन अपना सारा डेटा साफ-सुथरा रखना चाहता है, लेकिन उनमें से अधिकतर लोग इसके लिए भुगतान करने को तैयार नहीं होते या इंतजार करने को तैयार नहीं होते। सारा डेटा साफ करने में बहुत समय लग जाता है, इसलिए बेहतर यही है कि सारा डेटा साफ करने की कोशिश न की जाए। - सफाई और व्यावसायिक प्राथमिकताओं के बीच संतुलन बनाए रखें:
हालांकि आपको सभी डेटा को ज़रूरत से ज़्यादा साफ़ करने से बचना चाहिए, लेकिन विश्वसनीयता के लिए महत्वपूर्ण और उच्च प्रभाव वाले फ़ील्ड को साफ़ करना सुनिश्चित करें। डेटा को साफ़ करने के प्रयासों को उन डेटा तत्वों पर केंद्रित करें जो व्यावसायिक निर्णयों और रिपोर्टिंग की सटीकता को सीधे प्रभावित करते हैं। - डेटा को साफ़ करने की लागत निर्धारित करें:
सभी गंदे डेटा को साफ करने से पहले, आपके लिए प्रत्येक गंदे डेटा तत्व के लिए सफाई लागत निर्धारित करना महत्वपूर्ण है। - क्वेरी प्रसंस्करण में तेजी लाने के लिए, सहायक दृश्य और अनुक्रमणिका रखें:
भंडारण लागत को कम करने के लिए, डिस्क टेप में सारांशित डेटा को स्टोर करें। साथ ही, संग्रहीत किए जाने वाले डेटा की मात्रा और उसके विस्तृत उपयोग के बीच व्यापार-बंद की आवश्यकता है। भंडारण लागत को कम करने के लिए डेटा की ग्रैन्युलैरिटी के स्तर पर व्यापार-बंद।