लोकेटर इन Selenium
⚡ स्मार्ट सारांश
लोकेटर इन Selenium ये वे कमांड हैं जो ऑटोमेशन इंजन को टेक्स्ट बॉक्स, बटन और चेकबॉक्स जैसे GUI तत्वों की पहचान करने का निर्देश देते हैं। यह संदर्भ ID, Name, Link Text, DOM और XPath लोकेटर प्रकारों को व्यावहारिक उदाहरणों, सिंटैक्स नियमों और विश्वसनीय वेब ऑटोमेशन स्क्रिप्ट के लिए चयन रणनीतियों के साथ समझाता है।

लोकेटर क्या होते हैं? Selenium?
लोकेटर एक कमांड है जो निर्देशित करता है Selenium आईईडी या Selenium वेबड्राइवर का उपयोग करके सही जीयूआई एलिमेंट, जैसे कि टेक्स्ट बॉक्स, बटन, लिंक या चेकबॉक्स, पर कार्रवाई की जानी चाहिए। किसी भी विश्वसनीय ऑटोमेशन स्क्रिप्ट के निर्माण के लिए सही जीयूआई एलिमेंट की पहचान करना एक पूर्व शर्त है। हालांकि, सटीक पहचान करना जितना लगता है उससे कहीं अधिक चुनौतीपूर्ण है। कभी-कभी, आप गलत एलिमेंट के साथ या किसी भी एलिमेंट के साथ इंटरैक्ट नहीं कर पाते हैं। इस समस्या को दूर करने के लिए, Selenium यह कई तरह की लोकेटर रणनीतियाँ प्रदान करता है जो GUI तत्वों को सटीक रूप से लक्षित करने की अनुमति देती हैं।
हालांकि कुछ कमांड, जैसे कि "ओपन" कमांड, के लिए लोकेटर की आवश्यकता नहीं होती है, लेकिन अधिकांश कमांड के लिए लोकेटर की आवश्यकता नहीं होती है। Selenium कमांड एलिमेंट लोकेटर पर निर्भर करते हैं। लोकेटर का चयन काफी हद तक आपके परीक्षण के तहत अनुप्रयोग (AUT) पर निर्भर करता है। इस ट्यूटोरियल में, हम फेसबुक और इंटरनेट के बीच बारी-बारी से उपयोग करेंगे। Mercury टूर डेमो साइट (newtours.demoaut) पर, यह देखा जा सकता है कि प्रत्येक एप्लिकेशन किन लोकेटरों का समर्थन करता है। इसी प्रकार, आपके अपने परीक्षण प्रोजेक्ट में, आप एक एलिमेंट लोकेटर का चयन करेंगे Selenium वेबड्राइवर आपके एप्लिकेशन की संरचना पर आधारित है।
आईडी द्वारा पता लगाना
पेज पर मौजूद प्रत्येक एलिमेंट के लिए ID अद्वितीय होने के कारण, एलिमेंट्स का पता लगाने का यह सबसे आम तरीका है। जब भी ID एट्रिब्यूट मौजूद हो, तेज़, स्थिर और पठनीय टेस्ट स्क्रिप्ट के लिए यह आपकी पहली पसंद होनी चाहिए।
Target प्रारूप: id=तत्व की आईडी
इस उदाहरण के लिए, हम एक फेसबुक डेमो पेज का उपयोग करेंगे क्योंकि Mercury टूर्स अपने मुख्य फॉर्म फ़ील्ड के लिए आईडी एट्रिब्यूट का उपयोग नहीं करता है।
चरण 1) इस डेमो पेज का उपयोग करें https://demo.guru99.com/test/facebook.html परीक्षण के लिए। अपने ब्राउज़र के बिल्ट-इन डेवलपर टूल्स का उपयोग करके "ईमेल या फ़ोन" टेक्स्ट बॉक्स की जांच करें (क्रोम, एज या ब्राउज़र में F12 दबाएं)। Firefox) और इसकी आईडी नोट कर लें। इस मामले में, आईडी "ईमेल" है।

चरण 2) लांच Selenium IDE खोलें और “id=email” दर्ज करें Target बॉक्स। फाइंड बटन पर क्लिक करें और ध्यान दें कि "ईमेल या फ़ोन" टेक्स्ट बॉक्स पीले रंग में हाइलाइट किया गया है और उसके चारों ओर हरा बॉर्डर है, जो दर्शाता है कि Selenium IDE ने एलिमेंट को सही ढंग से पहचान लिया है।

नाम से पता लगाना
नाम से तत्वों का पता लगाना आईडी द्वारा पता लगाने के समान है, सिवाय इसके कि हम इसका उपयोग करते हैं “नाम=" इसके बजाय उपसर्ग का प्रयोग करें। यह तरीका तब उपयोगी होता है जब तत्वों में आईडी न हो लेकिन नाम विशेषता परिभाषित हो।
Target प्रारूप: नाम=तत्व का नाम
निम्नलिखित प्रदर्शन के लिए, हम उपयोग करेंगे Mercury टूर इसलिए क्योंकि साइट पर मौजूद सभी महत्वपूर्ण फॉर्म तत्वों में एक नाम विशेषता होती है।
चरण 1) पर जाए https://demo.guru99.com/test/newtours/ और ब्राउज़र के डेवलपर टूल्स का उपयोग करके "यूज़र नेम" टेक्स्ट बॉक्स की जांच करें। इसके नाम एट्रिब्यूट पर ध्यान दें।

यहां, एलिमेंट का नाम “userName” है।
चरण 2) In Selenium आईडीई में, “name=userName” दर्ज करें Target बॉक्स पर जाएं और खोजें बटन पर क्लिक करें। Selenium IDE को यूजर नेम टेक्स्ट बॉक्स को हाईलाइट करके उसे ढूंढना चाहिए।

फ़िल्टर का उपयोग करके नाम से तत्व का पता कैसे लगाएं
फ़िल्टर तब उपयोगी होते हैं जब कई तत्व एक ही नाम विशेषता साझा करते हैं। फ़िल्टर अतिरिक्त विशेषताएँ हैं जिनका उपयोग समान नाम वाले तत्वों को अलग करने के लिए किया जाता है। बिना फिल्टर के, Selenium यह डिफ़ॉल्ट रूप से केवल पहले मेल खाने वाले तत्व को ही चुनेगा।
Target प्रारूप: नाम=तत्व_का_नाम फ़िल्टर=फ़िल्टर_का_मूल्य
आइए एक उदाहरण के माध्यम से समझते हैं।
चरण 1) पर लॉग इन करें Mercury भ्रमण।
साइन इन करें Mercury टूर के लिए यूज़रनेम और पासवर्ड दोनों के रूप में "ट्यूटोरियल" का उपयोग करें। फ्लाइट फाइंडर पेज नीचे दिखाए अनुसार दिखाई देना चाहिए।

चरण 2) VALUE एट्रिब्यूट की जांच करने के लिए डेवलपर टूल्स का उपयोग करें।
ध्यान दें कि राउंड ट्रिप और वन वे रेडियो बटन का नाम "tripType" समान है। हालांकि, उनके VALUE एट्रिब्यूट अलग-अलग हैं, इसलिए हम प्रत्येक मान को फ़िल्टर के रूप में उपयोग कर सकते हैं।

चरण 3) एडिटर में पहली पंक्ति पर क्लिक करें।
- हम सबसे पहले वन वे रेडियो बटन पर क्लिक करेंगे। पहली पंक्ति पर क्लिक करें। Selenium आईईडी संपादक।
- कमांड बॉक्स में, "क्लिक" कमांड दर्ज करें।
- में Target बॉक्स में, “name=tripType value=oneway” दर्ज करें। “value=oneway” वाला हिस्सा हमारे फ़िल्टर के रूप में काम करेगा।

चरण 4) खोजें बटन पर क्लिक करें.
सूचना है कि Selenium IDE वन वे रेडियो बटन को हरे रंग में हाइलाइट करता है, जिससे यह पुष्टि होती है कि एलिमेंट को उसके VALUE एट्रीब्यूट के माध्यम से सफलतापूर्वक एक्सेस किया गया है।

चरण 5) वन वे रेडियो बटन का चयन करें।
क्लिक कमांड को निष्पादित करने के लिए अपने कीबोर्ड पर "X" कुंजी दबाएँ। अब वन वे रेडियो बटन चयनित हो गया है।

आप राउंड ट्रिप रेडियो बटन पर भी यही क्रिया कर सकते हैं, इस बार अपने लक्ष्य के रूप में "name=tripType value=roundtrip" का उपयोग करें।
लिंक टेक्स्ट द्वारा पता लगाना
यह लोकेटर रणनीति केवल हाइपरलिंक टेक्स्ट पर लागू होती है। हम लक्ष्य से पहले “link=” लगाकर और उसके बाद दिखाई देने वाले हाइपरलिंक टेक्स्ट को लिखकर लिंक तक पहुँचते हैं। यह विधि अत्यधिक पठनीय है और नेविगेशन परीक्षण के लिए अच्छी तरह काम करती है।
Target प्रारूप: लिंक=link_text
निम्नलिखित उदाहरण में, हम वेबसाइट पर मौजूद "रजिस्टर" लिंक पर क्लिक करेंगे। Mercury पर्यटन मुखपृष्ठ.
चरण 1)
- सबसे पहले, सुनिश्चित करें कि आप लॉग आउट हो चुके हैं। Mercury भ्रमण।
- पर नेविगेट करें Mercury पर्यटन मुखपृष्ठ.
चरण 2)
- डेवलपर टूल्स का उपयोग करके "रजिस्टर" लिंक की जांच करें। लिंक का टेक्स्ट ओपनिंग और क्लोजिंग एंकर टैग के बीच दिखाई देता है।
- इस मामले में, लिंक का टेक्स्ट “रजिस्टर” है। लिंक टेक्स्ट को कॉपी करें।
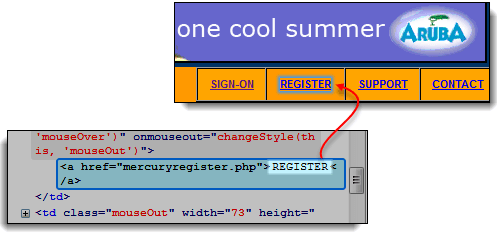
चरण 3) लिंक का टेक्स्ट कॉपी करें और उसे पेस्ट करें Selenium आईडीई Target बॉक्स में “link=" उपसर्ग लगाएं.

चरण 4) खोजें बटन पर क्लिक करें. Selenium IDE रजिस्टर लिंक को सही ढंग से हाईलाइट करेगा।

चरण 5) आगे सत्यापन के लिए, कमांड बॉक्स में “clickAndWait” दर्ज करें और इसे निष्पादित करें। Selenium IDE सफलतापूर्वक REGISTER लिंक पर क्लिक करेगा और आपको नीचे दिखाए गए पंजीकरण पृष्ठ पर ले जाएगा।

DOM (दस्तावेज़ ऑब्जेक्ट मॉडल) द्वारा स्थान निर्धारण
RSI दस्तावेज़ ऑब्जेक्ट मॉडल (DOM)सरल शब्दों में कहें तो, यह वर्णन करता है कि एचटीएमएल तत्व नोड्स के एक वृक्ष के रूप में कैसे संरचित होते हैं। Selenium IDE पृष्ठ तत्वों तक पहुँचने के लिए इस ट्री को नेविगेट कर सकता है। इस विधि का उपयोग करते समय, Target बॉक्स हमेशा “dom=document…” से शुरू होता है। “dom=” उपसर्ग को आमतौर पर छोड़ दिया जाता है क्योंकि Selenium IDE स्वचालित रूप से "document" से शुरू होने वाले किसी भी मान को DOM पथ के रूप में व्याख्या करता है।
DOM में किसी तत्व का पता लगाने के चार बुनियादी तरीके हैं। Selenium:
- getElementById
- getElementsByName
- डोम:नाम (केवल नामित फॉर्म के भीतर तत्वों पर लागू होता है)
- डोम:सूचकांक
DOM द्वारा पता लगाना – getElementById
आइए सबसे पहले DOM के getElementById मेथड को समझते हैं। Seleniumयह विधि आईडी विशेषता का मिलान करके एक एकल तत्व लौटाती है।
वाक्य - विन्यास
document.getElementById("id of the element")
- एलिमेंट की आईडी = एक्सेस किए जाने वाले एलिमेंट के आईडी एट्रिब्यूट का मान। यह मान हमेशा उद्धरण चिह्नों के जोड़े में होना चाहिए।
चरण 1) इस डेमो पेज का उपयोग करें https://demo.guru99.com/test/facebook.htmlउस पेज पर जाएं और डेवलपर टूल्स का उपयोग करके "मुझे लॉग इन रखें" चेकबॉक्स की जांच करें। इसकी आईडी नोट कर लें।

हमें जिस आईडी का उपयोग करना चाहिए वह है "persist_box"।
चरण 2) प्रारंभिक Selenium आईडीई और Target बॉक्स में document.getElementById(“persist_box”) दर्ज करें, फिर खोजें पर क्लिक करें। Selenium IDE "मुझे लॉग इन रखें" चेकबॉक्स का पता लगाएगा। हालाँकि यह चेकबॉक्स के अंदरूनी हिस्से को हाईलाइट नहीं कर सकता, लेकिन यह एलिमेंट को चमकीले हरे रंग के बॉर्डर से घेर देता है, जैसा कि नीचे दिखाया गया है।

DOM द्वारा पता लगाना – getElementsByName
getElementById विधि एक समय में केवल एक ही तत्व को एक्सेस करती है, अर्थात् निर्दिष्ट ID वाले तत्व को। getElementsByName विधि अलग तरह से काम करती है। यह निर्दिष्ट नाम वाले तत्वों का एक ऐरे लौटाती है। प्रत्येक तत्व को 0 से शुरू होने वाले संख्यात्मक इंडेक्स का उपयोग करके एक्सेस किया जाता है।
 |
getElementById यह केवल एक ही तत्व लौटाता है। उस तत्व में getElementById() के कोष्ठकों के अंदर निर्दिष्ट ID होती है। |
 |
getElementsByName यह समान नामों वाले तत्वों का एक संग्रह लौटाता है। प्रत्येक तत्व को 0 से शुरू होने वाली संख्या द्वारा अनुक्रमित किया जाता है, जैसे कि एक ऐरे। नीचे दिए गए सिंटैक्स में वर्ग कोष्ठक के अंदर उसका अनुक्रमणिका रखकर आप एक विशिष्ट तत्व का चयन कर सकते हैं। |
वाक्य - विन्यास
document.getElementsByName("name")[index]
- नाम = तत्व का नाम जैसा कि उसके 'नाम' विशेषता द्वारा परिभाषित किया गया है
- index = एक पूर्णांक जो इंगित करता है कि getElementsByName की सरणी में कौन सा तत्व उपयोग किया जाएगा।
चरण 1) पर नेविगेट करें Mercury टूर होमपेज पर जाएं और यूजरनेम और पासवर्ड के रूप में "ट्यूटोरियल" का उपयोग करके लॉग इन करें। ब्राउज़र फ्लाइट फाइंडर स्क्रीन लोड करेगा।
चरण 2) पेज के निचले भाग में मौजूद तीन रेडियो बटन (इकोनॉमी क्लास, बिजनेस क्लास और फर्स्ट क्लास) की जांच करने के लिए डेवलपर टूल्स का उपयोग करें। ध्यान दें कि इन सभी का नाम "servClass" है।

चरण 3) सबसे पहले, आइए "इकोनॉमी क्लास" रेडियो बटन को एक्सेस करें। तीनों रेडियो बटनों में से, यह एलिमेंट सबसे पहले आता है, इसलिए इसका इंडेक्स 0 है। Selenium IDE में, document.getElementsByName(“servClass”)[0] टाइप करें और फाइंड बटन पर क्लिक करें। Selenium IDE इकोनॉमी क्लास के रेडियो बटन को सही ढंग से पहचान लेगा।

चरण 4) इंडेक्स नंबर को 1 में बदलें, ताकि आपका Target document.getElementsByName(“servClass”)[1] बन जाता है। फाइंड बटन पर क्लिक करें, और Selenium IDE नीचे दिखाए अनुसार "बिजनेस क्लास" रेडियो बटन को हाइलाइट करेगा।

DOM द्वारा पता लगाना – dom:name
जैसा कि पहले बताया गया है, यह विधि केवल तभी लागू होती है जब आप जिस एलिमेंट तक पहुँच रहे हैं वह किसी नाम वाले फॉर्म के अंदर मौजूद हो। लोकेटर पाथ फॉर्म से शुरू होता है, फिर नाम के आधार पर लक्ष्य एलिमेंट तक पहुँचता है।
वाक्य - विन्यास
document.forms["name of the form"].elements["name of the element"]
- फॉर्म का नाम = उस फॉर्म टैग के नाम एट्रिब्यूट का मान जिसमें वह एलिमेंट शामिल है जिसे आप एक्सेस करना चाहते हैं
- तत्व का नाम = उस तत्व के नाम विशेषता का मान जिसे आप एक्सेस करना चाहते हैं
चरण 1) पर जाए Mercury टूर्स होमपेज https://demo.guru99.com/test/newtours/ और डेवलपर टूल्स का उपयोग करके यूजर नेम टेक्स्ट बॉक्स की जांच करें। ध्यान दें कि यह "होम" नामक एक फॉर्म में मौजूद है।

चरण 2) In Selenium IDE में, document.forms[“home”].elements[“userName”] टाइप करें और Find बटन पर क्लिक करें। Selenium IDE इस एलिमेंट को सफलतापूर्वक एक्सेस कर लेगा।

DOM द्वारा पता लगाना – dom:index
यह विधि तब भी लागू होती है जब तत्व किसी नाम वाले फ़ॉर्म के भीतर न हो, क्योंकि यह उसके नाम के बजाय फ़ॉर्म के इंडेक्स का उपयोग करती है। यह उन पुराने पृष्ठों या स्वतः उत्पन्न फ़ॉर्मों के लिए उपयोगी है जहाँ नामकरण उपलब्ध नहीं है।
वाक्य - विन्यास
document.forms[index of the form].elements[index of the element]
- फॉर्म का इंडेक्स = पूरे पेज के संबंध में फॉर्म का इंडेक्स नंबर (0 से शुरू होकर)
- तत्व का सूचकांक = उस फ़ॉर्म के सापेक्ष तत्व की सूचकांक संख्या (0 से शुरू होकर) जिसमें वह तत्व समाहित है।
हम फ़ोन पर मौजूद "फ़ोन" टेक्स्ट बॉक्स का उपयोग करेंगे। Mercury टूर पंजीकरण पृष्ठ। इस पृष्ठ पर मौजूद फॉर्म में न तो नाम है और न ही आईडी विशेषता, इसलिए यह एक अच्छा उदाहरण है।
चरण 1) पर नेविगेट करें Mercury टूर पंजीकरण पृष्ठ पर जाएं और फ़ोन टेक्स्ट बॉक्स की जांच करें। ध्यान दें कि आस-पास के फ़ॉर्म में न तो आईडी और न ही नाम विशेषताएँ हैं।

चरण 2) document.forms[0].elements[3] दर्ज करें Selenium आईडीई Target बॉक्स पर जाएं और खोजें बटन पर क्लिक करें। Selenium IDE फ़ोन टेक्स्ट बॉक्स को सही ढंग से एक्सेस करेगा।

चरण 3) वैकल्पिक रूप से, आप समान परिणाम के लिए इंडेक्स के स्थान पर एलिमेंट के नाम का उपयोग कर सकते हैं। document.forms[0].elements[“phone”] दर्ज करें Target बॉक्स। फ़ोन टेक्स्ट बॉक्स अभी भी हाइलाइटेड रहेगा।

XPath द्वारा पता लगाना
एक्सपाथ XML (एक्सटेंसिबल मार्कअप लैंग्वेज) नोड्स को नेविगेट करने के लिए उपयोग की जाने वाली क्वेरी भाषा है। चूंकि HTML को XML का एक कार्यान्वयन माना जा सकता है, एक्सपाथ यह एचटीएमएल तत्वों का पता भी लगा सकता है। यह सबसे शक्तिशाली लोकेटर रणनीतियों में से एक है। Selenium.
- लाभ: यह लगभग किसी भी तत्व तक पहुंच सकता है, जिसमें वे तत्व भी शामिल हैं जिनमें क्लास, नाम या आईडी विशेषताएँ नहीं होती हैं।
- हानि: यह अपने अनेक नियमों और वाक्य संरचना में विभिन्नताओं के कारण सबसे जटिल लोकेटर रणनीति है।
आधुनिक ब्राउज़र डेवलपर टूल्स स्वचालित रूप से XPath एक्सप्रेशन उत्पन्न कर सकते हैं। Chrome, Edge, या Firefoxएलिमेंट्स पैनल में किसी एलिमेंट पर राइट-क्लिक करें और कॉपी > कॉपी XPath चुनें। निम्नलिखित उदाहरण में, हम एक ऐसी छवि तक पहुंच प्राप्त करेंगे जिसे पहले बताए गए तरीकों से नहीं खोजा जा सकता है।
चरण 1) पर नेविगेट करें Mercury टूर होमपेज पर जाएं और डेवलपर टूल्स का उपयोग करके पीले "लिंक्स" बॉक्स के दाईं ओर स्थित नारंगी आयत का निरीक्षण करें, जैसा कि नीचे दिखाया गया है।

चरण 2) एलिमेंट के HTML कोड पर राइट-क्लिक करें, फिर "कॉपी XPath" विकल्प चुनें।

चरण 3) In Selenium आईडीई, एक सिंगल फॉरवर्ड स्लैश “/” टाइप करें Target बॉक्स में, फिर पिछले चरण में कॉपी किए गए XPath को पेस्ट करें। प्रविष्टि Target बॉक्स अब दो फॉरवर्ड स्लैश “//” से शुरू होना चाहिए।

चरण 4) खोजें बटन पर क्लिक करें. Selenium IDE नीचे दिखाए गए अनुसार नारंगी बॉक्स को हाईलाइट करेगा।

सही लोकेटर चुनना क्यों महत्वपूर्ण है
सही लोकेटर रणनीति का चयन करना सबसे महत्वपूर्ण निर्णयों में से एक है। Selenium स्वचालन महत्वपूर्ण है क्योंकि यह स्क्रिप्ट की स्थिरता, निष्पादन गति और दीर्घकालिक रखरखाव लागत को सीधे प्रभावित करता है। गलत तरीके से चुना गया लोकेटर अस्थिर परीक्षणों, गलत विफलताओं और एप्लिकेशन के UI में बदलाव होने पर बार-बार पुनर्कार्य करने का कारण बन सकता है। अनुभवी स्वचालन इंजीनियरों द्वारा अनुशंसित वरीयता क्रम पहले ID, फिर नाम, उसके बाद CSS चयनकर्ता, लिंक टेक्स्ट और अंत में XPath है।
आईडी-आधारित लोकेटर सबसे तेज़ होते हैं क्योंकि ब्राउज़र की खोज अद्वितीय पहचानकर्ताओं के लिए अनुकूलित होती है। नाम-आधारित लोकेटर लगभग उतने ही कुशल होते हैं जब नाम अद्वितीय होते हैं। सीएसएस सिलेक्टर्स और एक्सपाथ लचीलापन प्रदान करते हैं लेकिन डेवलपर्स द्वारा डीओएम को रिफैक्टर करने पर धीमे और अधिक अस्थिर हो जाते हैं। लिंक टेक्स्ट नेविगेशन लिंक के लिए उत्कृष्ट है लेकिन इसका पुन: उपयोग सीमित है।
स्थिर स्वचालन डेवलपर्स के सहयोग पर भी निर्भर करता है। जब परीक्षक कोड समीक्षा के दौरान सुसंगत और सार्थक आईडी या डेटा-* एट्रिब्यूट का अनुरोध करते हैं, तो लोकेटर की स्थिरता में काफी सुधार होता है। स्वचालित रूप से उत्पन्न आईडी (जैसे कि फ्रेमवर्क द्वारा निर्मित) पर निर्भर रहने से बचें क्योंकि वे बिल्ड के बीच बदल सकती हैं। पठनीय, उद्देश्य-आधारित लोकेटरों को प्राथमिकता देकर, टीमें परीक्षण सूट को रखरखाव योग्य बनाए रख सकती हैं और एप्लिकेशन के विकास के साथ तकनीकी ऋण को कम कर सकती हैं।
विश्वसनीय लोकेटर लिखने के लिए सर्वोत्तम अभ्यास
विश्वसनीय लोकेटर एक रखरखाव योग्य प्रणाली की नींव हैं। Selenium टेस्ट सूट। निम्नलिखित पद्धतियाँ स्क्रिप्ट विफलताओं को कम करने, पठनीयता में सुधार करने और UI परिवर्तनों के प्रति परीक्षणों को लचीला बनाने में मदद करती हैं।
- अद्वितीय आईडी को प्राथमिकता दें: सबसे पहले हमेशा आईडी एट्रिब्यूट की जांच करें। आईडी का उद्देश्य पेज के भीतर अद्वितीय होना है और यह सबसे बेहतर प्रदर्शन वाला विकल्प है।
- सिमेंटिक नाम और डेटा-* एट्रिब्यूट का उपयोग करें: डेवलपर्स को data-testid या data-qa जैसे स्थिर परीक्षण एट्रिब्यूट जोड़ने के लिए प्रोत्साहित करें। ये CSS क्लास में बदलाव होने पर भी स्थिर रहते हैं।
- पूर्ण XPath से बचें: /html/body/div[2]/div[3]/span जैसे निरपेक्ष पथ आसानी से टूट जाते हैं। //input[@name='userName'] जैसे एट्रिब्यूट के साथ सापेक्ष XPath अभिव्यक्तियों का उपयोग करें।
- सटीकता के लिए विशेषताओं को संयोजित करें: जब कोई एक विशेषता अद्वितीय न हो, तो सही तत्व को लक्षित करने के लिए कई विशेषताओं को संयोजित करें (उदाहरण के लिए, //button[@type='submit' and @name='login'])।
- पाठ का विवेकपूर्ण प्रयोग करें: दृश्य पाठ पर निर्भर लोकेटर भाषा के अनुसार काम करना बंद कर सकते हैं। पाठ-आधारित लोकेटर का उपयोग केवल तभी करें जब सामग्री स्थिर और एकभाषी हो।
- लोकेटरों को केंद्रीकृत करें: पेज ऑब्जेक्ट मॉडल (POM) क्लास में लोकेटर स्टोर करें ताकि अपडेट कई टेस्ट स्क्रिप्ट में करने के बजाय एक ही जगह पर किए जा सकें।
- डेवलपर टूल्स में सत्यापन करें: किसी स्क्रिप्ट में लोकेटर जोड़ने से पहले, ब्राउज़र कंसोल में XPath के लिए $x(“//xpath”) या CSS के लिए document.querySelector का उपयोग करके इसका परीक्षण करें ताकि यह पुष्टि हो सके कि यह ठीक एक ही तत्व लौटाता है।
- जहां तक संभव हो, इंडेक्स-आधारित लोकेटरों से बचें: [3] जैसी अनुक्रमणिका स्थितियाँ तत्व क्रम पर निर्भर करती हैं। मामूली लेआउट परिवर्तन भी अनुक्रमणिका को स्थानांतरित कर सकते हैं और स्क्रिप्ट को बाधित कर सकते हैं।
इन प्रक्रियाओं को लगातार लागू करके, ऑटोमेशन इंजीनियर ऐसे टेस्ट सूट बनाते हैं जो टीमों में व्यापक रूप से काम करते हैं और न्यूनतम रखरखाव के साथ बार-बार होने वाले यूआई अपडेट से बचे रहते हैं।