PyTorch ट्यूटोरियल
पायटॉर्च ट्यूटोरियल सारांश
इस पाइटोरच ट्यूटोरियल में, आप सभी अवधारणाओं को स्क्रैच से सीखेंगे। यह ट्यूटोरियल बुनियादी से लेकर उन्नत विषयों जैसे कि पाइटोरच की परिभाषा, पाइटोरच के फायदे और नुकसान, तुलना, इंस्टॉलेशन, पाइटोरच फ्रेमवर्क, रिग्रेशन और इमेज वर्गीकरण को कवर करता है। यह पाइटोरच ट्यूटोरियल बिल्कुल मुफ़्त है।
Py क्या है?Torएच?
PyTorch एक खुला स्रोत है Torप्राकृतिक भाषा प्रसंस्करण के लिए ch आधारित मशीन लर्निंग लाइब्रेरी का उपयोग करते हुए Pythonयह NumPy के समान है लेकिन इसमें शक्तिशाली GPU सपोर्ट है। यह डायनामिक कम्प्यूटेशनल ग्राफ प्रदान करता है जिसे आप ऑटोग्रैड की मदद से चलते-फिरते संशोधित कर सकते हैं।Torch कुछ अन्य फ्रेमवर्क की तुलना में तेज़ भी है। इसे 2016 में फेसबुक के एआई रिसर्च ग्रुप द्वारा विकसित किया गया था।
PyTorलाभ और हानि
Py के फायदे और नुकसान निम्नलिखित हैंTorच:
पाय के लाभTorch
- सरल पुस्तकालय
PyTorch कोड सरल है। इसे समझना आसान है, और आप लाइब्रेरी का तुरंत उपयोग कर सकते हैं। उदाहरण के लिए, नीचे दिए गए कोड स्निपेट को देखें:
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.layer = torch.nn.Linear(1, 1)
def forward(self, x):
x = self.layer(x)
return x
जैसा कि ऊपर बताया गया है, आप नेटवर्क मॉडल को आसानी से परिभाषित कर सकते हैं, और आप बिना अधिक प्रशिक्षण के कोड को जल्दी से समझ सकते हैं।
- गतिशील कम्प्यूटेशनल ग्राफ

छवि स्रोत: Py के साथ डीप लर्निंग की खोजTorch
Pytorch डायनेमिक कम्प्यूटेशनल ग्राफ (DAG) प्रदान करता है। कम्प्यूटेशनल ग्राफ ग्राफ मॉडल या नोड्स और एज जैसे सिद्धांतों में गणितीय अभिव्यक्तियों को व्यक्त करने का एक तरीका है। नोड गणितीय ऑपरेशन करेगा, और एज एक टेंसर है जिसे नोड्स में फीड किया जाएगा और टेंसर में नोड का आउटपुट ले जाएगा।
DAG एक ऐसा ग्राफ है जो मनमाना आकार रखता है और विभिन्न इनपुट ग्राफ़ के बीच संचालन करने में सक्षम है। हर पुनरावृत्ति, एक नया ग्राफ़ बनाया जाता है। इसलिए, एक ही ग्राफ़ संरचना रखना या एक अलग ऑपरेशन के साथ एक नया ग्राफ़ बनाना संभव है, या हम इसे एक गतिशील ग्राफ़ कह सकते हैं।
- बेहतर प्रदर्शन
समुदाय और शोधकर्ता, बेंचमार्क करें और फ्रेमवर्क की तुलना करें ताकि पता चल सके कि कौन सा फ्रेमवर्क ज़्यादा तेज़ है। GitHub रेपो डीप लर्निंग फ्रेमवर्क और जीपीयू पर बेंचमार्क रिपोर्ट किया कि पायTorप्रति सेकंड संसाधित की जाने वाली छवियों की संख्या के मामले में ch अन्य फ्रेमवर्क की तुलना में तेज़ है।
जैसा कि आप नीचे देख सकते हैं, vgg16 और resnet152 के साथ तुलना ग्राफ


- नेटिव Python
PyTorch मुख्य रूप से पायथन पर आधारित है। उदाहरण के लिए, यदि आप किसी मॉडल को प्रशिक्षित करना चाहते हैं, तो आप नेटिव कंट्रोल फ्लो जैसे loo का उपयोग कर सकते हैं।ping और इसके लिए अतिरिक्त विशेष वैरिएबल या सेशन जोड़ने की आवश्यकता के बिना ही रिकर्सन किए जा सकते हैं। यह प्रशिक्षण प्रक्रिया के लिए बहुत उपयोगी है।
Pytorch इम्पेरेटिव प्रोग्रामिंग को भी लागू करता है, और यह निश्चित रूप से अधिक लचीला है। इसलिए, गणना प्रक्रिया के बीच में टेंसर मान को प्रिंट करना संभव है।
पाई के नुकसानTorch
PyTorch को विज़ुअलाइज़ेशन के लिए थर्ड-पार्टी एप्लिकेशन की आवश्यकता होती है। उत्पादन के लिए इसे एक API सर्वर की भी आवश्यकता होती है।
इस Py में अगलाTorइस ट्यूटोरियल में, हम Py के बीच अंतर के बारे में जानेंगे।Torch और TensorFlow.
PyTorch बनाम टेन्सरफ्लो
| प्राचल | PyTorch | टेन्सलफ्लो |
|---|---|---|
| मॉडल परिभाषा | मॉडल को एक उपवर्ग में परिभाषित किया गया है और यह उपयोग में आसान पैकेज प्रदान करता है | मॉडल को कई तरीकों से परिभाषित किया गया है, और आपको वाक्यविन्यास को समझने की आवश्यकता है |
| GPU समर्थन | हाँ | हाँ |
| ग्राफ़ प्रकार | गतिशील | स्थिर |
| टूल्स | कोई विज़ुअलाइज़ेशन टूल नहीं | आप Tensorboard विज़ुअलाइज़ेशन टूल का उपयोग कर सकते हैं |
| समुदाय | समुदाय अभी भी बढ़ रहा है | बड़े सक्रिय समुदाय |
Py को इंस्टॉल करनाTorch
Linux
इसे लिनक्स में इंस्टॉल करना बहुत आसान है। आप वर्चुअल एनवायरनमेंट का इस्तेमाल करना चुन सकते हैं या इसे सीधे रूट एक्सेस से इंस्टॉल कर सकते हैं। टर्मिनल में यह कमांड टाइप करें
pip3 install --upgrade torch torchvision
एडब्ल्यूएस सेजमेकर
सेजमेकर उन प्लेटफार्मों में से एक है Amazon वेब सेवा जो डेटा वैज्ञानिकों या डेवलपर्स के लिए किसी भी पैमाने पर मॉडल बनाने, प्रशिक्षित करने और तैनात करने के लिए पूर्व-स्थापित गहन शिक्षण कॉन्फ़िगरेशन के साथ एक शक्तिशाली मशीन लर्निंग इंजन प्रदान करता है।
सबसे पहले खोलें Amazon साधु बनानेवाला कंसोल पर जाएं और क्रिएट नोटबुक इंस्टेंस पर क्लिक करें और अपनी नोटबुक के लिए सभी विवरण भरें।

अगला चरण, अपना नोटबुक इंस्टेंस लॉन्च करने के लिए ओपन पर क्लिक करें।

अंततः, Jupyter, नया पर क्लिक करें और conda_pytorch_p36 चुनें और आप Pytorch स्थापित के साथ अपने नोटबुक इंस्टेंस का उपयोग करने के लिए तैयार हैं।
इस Py में अगलाTorइस ट्यूटोरियल में, हम पायथन के बारे में सीखेंगे।Torch फ्रेमवर्क की मूल बातें।
PyTorch फ्रेमवर्क की मूल बातें
आइए पायथन की बुनियादी अवधारणाओं को सीखते हैं।Torइससे पहले कि हम गहराई में उतरें, ch।Torch प्रत्येक वेरिएबल के लिए numpy के ndarray के समान Tensor का उपयोग करता है, लेकिन GPU कंप्यूटेशन सपोर्ट के साथ। यहाँ हम नेटवर्क मॉडल, लॉस फंक्शन, बैकप्रॉप और ऑप्टिमाइज़र के बारे में विस्तार से बताएंगे।
नेटवर्क मॉडल
नेटवर्क का निर्माण torch.nn को उपवर्गीकृत करके किया जा सकता है। इसके 2 मुख्य भाग हैं,
- पहला भाग उन मापदंडों और परतों को परिभाषित करना है जिनका आप उपयोग करेंगे
- दूसरा भाग मुख्य कार्य है जिसे फॉरवर्ड प्रोसेस कहा जाता है जो इनपुट लेगा और आउटपुट का पूर्वानुमान लगाएगा।
Import torch
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv1 = nn.Conv2d(3, 20, 5)
self.conv2 = nn.Conv2d(20, 40, 5)
self.fc1 = nn.Linear(320, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
return F.log_softmax(x)
net = Model()
जैसा कि आप ऊपर देख सकते हैं, आप मॉडल नामक nn.Module का एक वर्ग बनाते हैं। इसमें 2 Conv2d परतें और एक रैखिक परत होती है। पहली conv2d परत 3 का इनपुट और 20 का आउटपुट आकार लेती है। दूसरी परत 20 का इनपुट लेगी और 40 का आउटपुट आकार तैयार करेगी। अंतिम परत 320 के आकार में एक पूरी तरह से जुड़ी हुई परत है और 10 का आउटपुट तैयार करेगी।
फॉरवर्ड प्रक्रिया X का इनपुट लेगी और इसे conv1 परत पर फीड करेगी और ReLU फ़ंक्शन निष्पादित करेगी,
इसी तरह, यह conv2 लेयर को भी फीड करेगा। उसके बाद, x को (-1, 320) में फिर से आकार दिया जाएगा और अंतिम FC लेयर में फीड किया जाएगा। आउटपुट भेजने से पहले, आप सॉफ्टमैक्स एक्टिवेशन फ़ंक्शन का उपयोग करेंगे।
पिछड़ी प्रक्रिया स्वचालित रूप से ऑटोग्रैड द्वारा परिभाषित की जाती है, इसलिए आपको केवल आगे की प्रक्रिया को परिभाषित करने की आवश्यकता है।
लॉस फंकशन
हानि फ़ंक्शन का उपयोग यह मापने के लिए किया जाता है कि भविष्यवाणी मॉडल अपेक्षित परिणामों की कितनी अच्छी तरह से भविष्यवाणी करने में सक्षम है।Torch के torch.nn मॉड्यूल में पहले से ही कई मानक हानि फ़ंक्शन मौजूद हैं। उदाहरण के लिए, आप क्रॉस-एंट्रोपी हानि का उपयोग करके मल्टी-क्लास Py को हल कर सकते हैं।Torch वर्गीकरण समस्या। हानि फ़ंक्शन को परिभाषित करना और हानियों की गणना करना आसान है:
loss_fn = nn.CrossEntropyLoss() #training process loss = loss_fn(out, target)
Py का उपयोग करके अपने स्वयं के हानि फ़ंक्शन की गणना करना आसान है।Torचैप्टर।
बैकप्रॉप
बैकप्रोपेगेशन करने के लिए, आप बस los.backward() को कॉल करें। त्रुटि की गणना की जाएगी, लेकिन zero_grad() के साथ मौजूदा ग्रेडिएंट को साफ़ करना याद रखें
net.zero_grad() # to clear the existing gradient loss.backward() # to perform backpropragation
अनुकूलक
torch.optim सामान्य अनुकूलन एल्गोरिदम प्रदान करता है। आप एक सरल चरण के साथ एक अनुकूलक को परिभाषित कर सकते हैं:
optimizer = torch.optim.SGD(net.parameters(), lr = 0.01, momentum=0.9)
आपको नेटवर्क मॉडल पैरामीटर और लर्निंग दर को पास करना होगा ताकि प्रत्येक पुनरावृत्ति पर पैरामीटर बैकप्रॉप प्रक्रिया के बाद अपडेट हो जाएं।
Py के साथ सरल प्रतिगमनTorch
आइए Py का उपयोग करके सरल रिग्रेशन सीखते हैं।Torch उदाहरण:
चरण 1) अपना नेटवर्क मॉडल बनाना
हमारा नेटवर्क मॉडल एक सरल रैखिक परत है जिसका इनपुट और आउटपुट आकार 1 है।
from __future__ import print_function
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.layer = torch.nn.Linear(1, 1)
def forward(self, x):
x = self.layer(x)
return x
net = Net()
print(net)
और नेटवर्क आउटपुट इस तरह होना चाहिए
Net( (hidden): Linear(in_features=1, out_features=1, bias=True) )
चरण 2) परीक्षण डेटा
प्रशिक्षण प्रक्रिया शुरू करने से पहले, आपको हमारे डेटा को जानना होगा। आप हमारे मॉडल का परीक्षण करने के लिए एक यादृच्छिक फ़ंक्शन बनाते हैं। Y = x3 sin(x)+ 3x+0.8 रैंड(100)
# Visualize our data import matplotlib.pyplot as plt import numpy as np x = np.random.rand(100) y = np.sin(x) * np.power(x,3) + 3*x + np.random.rand(100)*0.8 plt.scatter(x, y) plt.show()
हमारे फ़ंक्शन का स्कैटर प्लॉट यहां दिया गया है:

प्रशिक्षण प्रक्रिया शुरू करने से पहले, आपको numpy ऐरे को उन वेरिएबल्स में परिवर्तित करना होगा जो समर्थित हैं। Torनीचे दिए गए Py में दिखाए गए अनुसार ch और ऑटोग्रेडTorch प्रतिगमन का उदाहरण।
# convert numpy array to tensor in shape of input size x = torch.from_numpy(x.reshape(-1,1)).float() y = torch.from_numpy(y.reshape(-1,1)).float() print(x, y)
चरण 3) अनुकूलक और हानि
इसके बाद, आपको हमारी प्रशिक्षण प्रक्रिया के लिए ऑप्टिमाइज़र और लॉस फ़ंक्शन को परिभाषित करना चाहिए।
# Define Optimizer and Loss Function optimizer = torch.optim.SGD(net.parameters(), lr=0.2) loss_func = torch.nn.MSELoss()
चरण 4) प्रशिक्षण
अब हम अपनी प्रशिक्षण प्रक्रिया शुरू करते हैं। 250 के युग के साथ, आप हमारे हाइपरपैरामीटर के लिए सर्वोत्तम मान खोजने के लिए हमारे डेटा को दोहराएंगे।
inputs = Variable(x)
outputs = Variable(y)
for i in range(250):
prediction = net(inputs)
loss = loss_func(prediction, outputs)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i % 10 == 0:
# plot and show learning process
plt.cla()
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=2)
plt.text(0.5, 0, 'Loss=%.4f' % loss.data.numpy(), fontdict={'size': 10, 'color': 'red'})
plt.pause(0.1)
plt.show()
चरण 5) परिणाम
जैसा कि आप नीचे देख सकते हैं, आपने Py को सफलतापूर्वक निष्पादित कर लिया है।Torन्यूरल नेटवर्क के साथ ch रिग्रेशन। दरअसल, प्रत्येक पुनरावृति पर, प्लॉट में लाल रेखा अपडेट होगी और डेटा के अनुरूप अपनी स्थिति बदलेगी। लेकिन इस चित्र में, यह केवल अंतिम परिणाम दिखाता है जैसा कि नीचे दिए गए Py में दिखाया गया है।Torch उदाहरण:

Py का उपयोग करके छवि वर्गीकरण का उदाहरणTorch
की मूल बातें सीखने के लिए लोकप्रिय तरीकों में से एक ध्यान लगा के पढ़ना या सीखना MNIST डेटासेट के साथ है। यह डीप लर्निंग में "हैलो वर्ल्ड" है। डेटासेट में 0 से 9 तक हस्तलिखित संख्याएँ हैं, जिनमें कुल 60,000 प्रशिक्षण नमूने और 10,000 परीक्षण नमूने हैं, जो पहले से ही 28x28 पिक्सेल के आकार के साथ लेबल किए गए हैं।

चरण 1) डेटा को प्रीप्रोसेस करें
इस Py के पहले चरण मेंTorch वर्गीकरण उदाहरण के लिए, आप torchvision मॉड्यूल का उपयोग करके डेटासेट लोड करेंगे।
प्रशिक्षण प्रक्रिया शुरू करने से पहले, आपको डेटा को समझना होगा। Torchvision डेटासेट को लोड करेगा और नेटवर्क की उपयुक्त आवश्यकताओं के अनुसार छवियों को रूपांतरित करेगा, जैसे कि छवियों का आकार और सामान्यीकरण।
import torch
import torchvision
import numpy as np
from torchvision import datasets, models, transforms
# This is used to transform the images to Tensor and normalize it
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
training = torchvision.datasets.MNIST(root='./data', train=True,
download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(training, batch_size=4,
shuffle=True, num_workers=2)
testing = torchvision.datasets.MNIST(root='./data', train=False,
download=True, transform=transform)
test_loader = torch.utils.data.DataLoader(testing, batch_size=4,
shuffle=False, num_workers=2)
classes = ('0', '1', '2', '3',
'4', '5', '6', '7', '8', '9')
import matplotlib.pyplot as plt
import numpy as np
#create an iterator for train_loader
# get random training images
data_iterator = iter(train_loader)
images, labels = data_iterator.next()
#plot 4 images to visualize the data
rows = 2
columns = 2
fig=plt.figure()
for i in range(4):
fig.add_subplot(rows, columns, i+1)
plt.title(classes[labels[i]])
img = images[i] / 2 + 0.5 # this is for unnormalize the image
img = torchvision.transforms.ToPILImage()(img)
plt.imshow(img)
plt.show()
ट्रांसफ़ॉर्म फ़ंक्शन छवियों को टेंसर में परिवर्तित करता है और मान को सामान्य करता है। फ़ंक्शन torchvision.transforms.MNIST, निर्देशिका में डेटासेट (यदि यह उपलब्ध नहीं है) डाउनलोड करेगा, यदि आवश्यक हो तो प्रशिक्षण के लिए डेटासेट सेट करेगा और रूपांतरण प्रक्रिया करेगा।
डेटासेट को विज़ुअलाइज़ करने के लिए, आप छवियों और लेबल के अगले बैच को प्राप्त करने के लिए data_iterator का उपयोग करते हैं। आप इन छवियों और उनके उपयुक्त लेबल को प्लॉट करने के लिए matplot का उपयोग करते हैं। जैसा कि आप नीचे हमारी छवियों और उनके लेबल को देख सकते हैं।
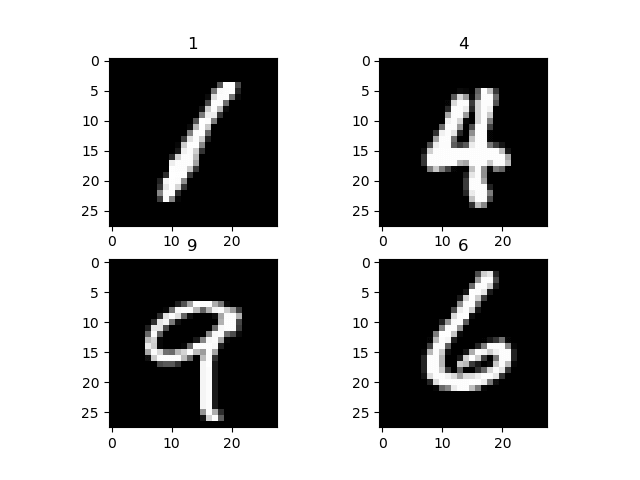
चरण 2) नेटवर्क मॉडल कॉन्फ़िगरेशन
अब इस Py मेंTorउदाहरण के लिए, आप पायथन के लिए एक सरल न्यूरल नेटवर्क बनाएंगे।Torch छवि वर्गीकरण।
यहां हम आपको पायथन में नेटवर्क मॉडल बनाने का एक और तरीका बताते हैं।Torअध्याय: हम nn.Module का सबक्लास बनाने के बजाय nn.Sequential का उपयोग करके एक अनुक्रम मॉडल बनाएंगे।
import torch.nn as nn
# flatten the tensor into
class Flatten(nn.Module):
def forward(self, input):
return input.view(input.size(0), -1)
#sequential based model
seq_model = nn.Sequential(
nn.Conv2d(1, 10, kernel_size=5),
nn.MaxPool2d(2),
nn.ReLU(),
nn.Dropout2d(),
nn.Conv2d(10, 20, kernel_size=5),
nn.MaxPool2d(2),
nn.ReLU(),
Flatten(),
nn.Linear(320, 50),
nn.ReLU(),
nn.Linear(50, 10),
nn.Softmax(),
)
net = seq_model
print(net)
यहाँ हमारे नेटवर्क मॉडल का आउटपुट है
Sequential( (0): Conv2d(1, 10, kernel_size=(5, 5), stride=(1, 1)) (1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (2): ReLU() (3): Dropout2d(p=0.5) (4): Conv2d(10, 20, kernel_size=(5, 5), stride=(1, 1)) (5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (6): ReLU() (7): Flatten() (8): Linear(in_features=320, out_features=50, bias=True) (9): ReLU() (10): Linear(in_features=50, out_features=10, bias=True) (11): Softmax() )
नेटवर्क स्पष्टीकरण
- अनुक्रम यह है कि पहली परत एक Conv2D परत है जिसका इनपुट आकार 1 और आउटपुट आकार 10 है तथा कर्नेल आकार 5 है
- इसके बाद, आपके पास MaxPool2D परत होगी
- ReLU सक्रियण फ़ंक्शन
- कम संभावना वाले मानों को छोड़ने के लिए ड्रॉपआउट परत।
- फिर अंतिम परत से 2 के इनपुट आकार और 10 के कर्नेल आकार के साथ 20 के आउटपुट आकार के साथ एक दूसरा Conv5d
- इसके बाद MaxPool2d परत
- ReLU सक्रियण फ़ंक्शन.
- उसके बाद, आप टेंसर को रैखिक परत में डालने से पहले उसे समतल कर देंगे
- रैखिक परत सॉफ्टमैक्स सक्रियण फ़ंक्शन के साथ दूसरी रैखिक परत पर हमारे आउटपुट को मैप करेगी
चरण 3) मॉडल को प्रशिक्षित करें
प्रशिक्षण प्रक्रिया शुरू करने से पहले, मानदंड और अनुकूलक फ़ंक्शन सेट करना आवश्यक है।
मानदंड के लिए, आप क्रॉसएंट्रोपी लॉस का उपयोग करेंगे। ऑप्टिमाइज़र के लिए, आप 0.001 की लर्निंग रेट और 0.9 के मोमेंटम के साथ एसजीडी का उपयोग करेंगे, जैसा कि नीचे दिए गए Py में दिखाया गया है।Torch उदाहरण।
import torch.optim as optim criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
फॉरवर्ड प्रक्रिया इनपुट शेप लेगी और इसे पहली conv2d लेयर में पास करेगी। फिर वहां से, इसे maxpool2d में फीड किया जाएगा और अंत में ReLU एक्टिवेशन फंक्शन में डाला जाएगा। यही प्रक्रिया दूसरी conv2d लेयर में भी होगी। उसके बाद, इनपुट को (-1,320) में फिर से शेप किया जाएगा और आउटपुट की भविष्यवाणी करने के लिए fc लेयर में फीड किया जाएगा।
अब, आप प्रशिक्षण प्रक्रिया शुरू करेंगे। आप हमारे डेटासेट को 2 बार या 2 के युग के साथ दोहराएंगे और हर 2000 बैच पर वर्तमान हानि का प्रिंट आउट लेंगे।
for epoch in range(2):
#set the running loss at each epoch to zero
running_loss = 0.0
# we will enumerate the train loader with starting index of 0
# for each iteration (i) and the data (tuple of input and labels)
for i, data in enumerate(train_loader, 0):
inputs, labels = data
# clear the gradient
optimizer.zero_grad()
#feed the input and acquire the output from network
outputs = net(inputs)
#calculating the predicted and the expected loss
loss = criterion(outputs, labels)
#compute the gradient
loss.backward()
#update the parameters
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 1000 == 0:
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 1000))
running_loss = 0.0
प्रत्येक युग में, गणनाकर्ता को इनपुट और संबंधित लेबल का अगला टपल मिलेगा। इससे पहले कि हम अपने नेटवर्क मॉडल में इनपुट फीड करें, हमें पिछले ग्रेडिएंट को साफ़ करना होगा। यह इसलिए आवश्यक है क्योंकि पिछड़ी प्रक्रिया (बैकप्रोपेगेशन प्रक्रिया) के बाद, ग्रेडिएंट को प्रतिस्थापित करने के बजाय संचित किया जाएगा। फिर, हम अपेक्षित आउटपुट से अनुमानित आउटपुट से होने वाले नुकसान की गणना करेंगे। उसके बाद, हम ग्रेडिएंट की गणना करने के लिए बैकप्रोपेगेशन करेंगे, और अंत में, हम मापदंडों को अपडेट करेंगे।
प्रशिक्षण प्रक्रिया का परिणाम यहां दिया गया है
[1, 1] loss: 0.002 [1, 1001] loss: 2.302 [1, 2001] loss: 2.295 [1, 3001] loss: 2.204 [1, 4001] loss: 1.930 [1, 5001] loss: 1.791 [1, 6001] loss: 1.756 [1, 7001] loss: 1.744 [1, 8001] loss: 1.696 [1, 9001] loss: 1.650 [1, 10001] loss: 1.640 [1, 11001] loss: 1.631 [1, 12001] loss: 1.631 [1, 13001] loss: 1.624 [1, 14001] loss: 1.616 [2, 1] loss: 0.001 [2, 1001] loss: 1.604 [2, 2001] loss: 1.607 [2, 3001] loss: 1.602 [2, 4001] loss: 1.596 [2, 5001] loss: 1.608 [2, 6001] loss: 1.589 [2, 7001] loss: 1.610 [2, 8001] loss: 1.596 [2, 9001] loss: 1.598 [2, 10001] loss: 1.603 [2, 11001] loss: 1.596 [2, 12001] loss: 1.587 [2, 13001] loss: 1.596 [2, 14001] loss: 1.603
चरण 4) मॉडल का परीक्षण करें
हमारे मॉडल को प्रशिक्षित करने के बाद, आपको छवियों के अन्य सेटों के साथ परीक्षण या मूल्यांकन करना होगा।
हम test_loader के लिए एक इटरेटर का उपयोग करेंगे, और यह छवियों और लेबल का एक बैच तैयार करेगा जिसे प्रशिक्षित मॉडल में पास किया जाएगा। अनुमानित आउटपुट प्रदर्शित किया जाएगा और अपेक्षित आउटपुट के साथ तुलना की जाएगी।
#make an iterator from test_loader
#Get a batch of training images
test_iterator = iter(test_loader)
images, labels = test_iterator.next()
results = net(images)
_, predicted = torch.max(results, 1)
print('Predicted: ', ' '.join('%5s' % classes[predicted[j]] for j in range(4)))
fig2 = plt.figure()
for i in range(4):
fig2.add_subplot(rows, columns, i+1)
plt.title('truth ' + classes[labels[i]] + ': predict ' + classes[predicted[i]])
img = images[i] / 2 + 0.5 # this is to unnormalize the image
img = torchvision.transforms.ToPILImage()(img)
plt.imshow(img)
plt.show()

सारांश
- PyTorch एक ओपन-सोर्स है Torch आधारित मशीन लर्निंग पुस्तकालय के लिए प्राकृतिक भाषा प्रसंस्करण का उपयोग Python.
- पाय के लाभTorअध्याय: 1) सरल लाइब्रेरी, 2) गतिशील कम्प्यूटेशनल ग्राफ, 3) बेहतर प्रदर्शन, 4) नेटिव Python
- PyTorch प्रत्येक वेरिएबल के लिए numpy के ndarray के समान Tensor का उपयोग करता है, लेकिन GPU कंप्यूटेशन सपोर्ट के साथ।
- गहन शिक्षण की मूल बातें सीखने के लिए एक लोकप्रिय तरीका MNIST डेटासेट है।