Py के साथ Seq2seq (अनुक्रम से अनुक्रम) मॉडलTorch
एनएलपी क्या है?
एनएलपी या नेचुरल लैंग्वेज प्रोसेसिंग आर्टिफिशियल इंटेलिजेंस की लोकप्रिय शाखाओं में से एक है जो कंप्यूटर को उनकी प्राकृतिक भाषा में मनुष्य को समझने, हेरफेर करने या प्रतिक्रिया देने में मदद करती है। एनएलपी इसके पीछे का इंजन है Google Translate जो हमें अन्य भाषाओं को समझने में मदद करता है.
Seq2Seq क्या है?
Seq2Seq एनकोडर-डिकोडर आधारित मशीन अनुवाद और भाषा प्रसंस्करण की एक विधि है जो टैग और ध्यान मूल्य के साथ अनुक्रम के आउटपुट के लिए अनुक्रम के इनपुट को मैप करती है। विचार 2 RNN का उपयोग करना है जो एक विशेष टोकन के साथ मिलकर काम करेंगे और पिछले अनुक्रम से अगले राज्य अनुक्रम की भविष्यवाणी करने का प्रयास करेंगे।
पिछले अनुक्रम से अनुक्रम की भविष्यवाणी कैसे करें
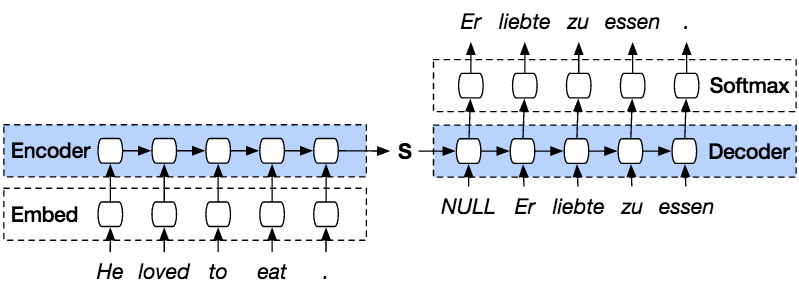
Py का उपयोग करके पिछली अनुक्रम से अनुक्रम का अनुमान लगाने के चरण निम्नलिखित हैं।Torचैप्टर।
चरण 1) हमारा डेटा लोड करना
हमारे डेटासेट के लिए, आप एक डेटासेट का उपयोग करेंगे टैब-सीमांकित द्विभाषी वाक्य युग्म. यहाँ मैं अंग्रेजी से इंडोनेशियाई डेटासेट का उपयोग करूँगा। आप अपनी पसंद का कुछ भी चुन सकते हैं, लेकिन कोड में फ़ाइल नाम और निर्देशिका बदलना न भूलें।
from __future__ import unicode_literals, print_function, division
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import numpy as np
import pandas as pd
import os
import re
import random
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
चरण 2) डेटा तैयारी
आप डेटासेट का सीधे उपयोग नहीं कर सकते। आपको वाक्यों को शब्दों में विभाजित करना होगा और इसे वन-हॉट वेक्टर में बदलना होगा। शब्दकोश बनाने के लिए हर शब्द को लैंग क्लास में विशिष्ट रूप से अनुक्रमित किया जाएगा। लैंग क्लास हर वाक्य को संग्रहीत करेगा और addSentence के साथ इसे शब्द दर शब्द विभाजित करेगा। फिर अनुक्रम से अनुक्रम मॉडल के लिए हर अज्ञात शब्द को अनुक्रमित करके एक शब्दकोश बनाएँ।
SOS_token = 0
EOS_token = 1
MAX_LENGTH = 20
#initialize Lang Class
class Lang:
def __init__(self):
#initialize containers to hold the words and corresponding index
self.word2index = {}
self.word2count = {}
self.index2word = {0: "SOS", 1: "EOS"}
self.n_words = 2 # Count SOS and EOS
#split a sentence into words and add it to the container
def addSentence(self, sentence):
for word in sentence.split(' '):
self.addWord(word)
#If the word is not in the container, the word will be added to it,
#else, update the word counter
def addWord(self, word):
if word not in self.word2index:
self.word2index[word] = self.n_words
self.word2count[word] = 1
self.index2word[self.n_words] = word
self.n_words += 1
else:
self.word2count[word] += 1
लैंग क्लास एक ऐसा क्लास है जो हमें शब्दकोश बनाने में मदद करेगा। प्रत्येक भाषा के लिए, प्रत्येक वाक्य को शब्दों में विभाजित किया जाएगा और फिर कंटेनर में जोड़ा जाएगा। प्रत्येक कंटेनर शब्दों को उचित इंडेक्स में संग्रहीत करेगा, शब्द की गिनती करेगा, और शब्द का इंडेक्स जोड़ेगा ताकि हम इसका उपयोग किसी शब्द का इंडेक्स खोजने या उसके इंडेक्स से कोई शब्द खोजने के लिए कर सकें।
क्योंकि हमारा डेटा TAB द्वारा अलग किया गया है, आपको इसका उपयोग करने की आवश्यकता है पांडा हमारे डेटा लोडर के रूप में। पांडा हमारे डेटा को डेटाफ़्रेम के रूप में पढ़ेगा और इसे हमारे स्रोत और लक्ष्य वाक्य में विभाजित करेगा। आपके पास मौजूद हर वाक्य के लिए,
- आप इसे लोअर केस में सामान्यीकृत करेंगे,
- सभी गैर-चरित्र हटाएँ
- यूनिकोड से ASCII में परिवर्तित करें
- वाक्यों को विभाजित करें, ताकि आपके पास प्रत्येक शब्द हो।
#Normalize every sentence
def normalize_sentence(df, lang):
sentence = df[lang].str.lower()
sentence = sentence.str.replace('[^A-Za-z\s]+', '')
sentence = sentence.str.normalize('NFD')
sentence = sentence.str.encode('ascii', errors='ignore').str.decode('utf-8')
return sentence
def read_sentence(df, lang1, lang2):
sentence1 = normalize_sentence(df, lang1)
sentence2 = normalize_sentence(df, lang2)
return sentence1, sentence2
def read_file(loc, lang1, lang2):
df = pd.read_csv(loc, delimiter='\t', header=None, names=[lang1, lang2])
return df
def process_data(lang1,lang2):
df = read_file('text/%s-%s.txt' % (lang1, lang2), lang1, lang2)
print("Read %s sentence pairs" % len(df))
sentence1, sentence2 = read_sentence(df, lang1, lang2)
source = Lang()
target = Lang()
pairs = []
for i in range(len(df)):
if len(sentence1[i].split(' ')) < MAX_LENGTH and len(sentence2[i].split(' ')) < MAX_LENGTH:
full = [sentence1[i], sentence2[i]]
source.addSentence(sentence1[i])
target.addSentence(sentence2[i])
pairs.append(full)
return source, target, pairs
एक और उपयोगी फ़ंक्शन जिसका आप उपयोग करेंगे वह है जोड़े को टेंसर में बदलना। यह बहुत महत्वपूर्ण है क्योंकि हमारा नेटवर्क केवल टेंसर प्रकार का डेटा पढ़ता है। यह इसलिए भी महत्वपूर्ण है क्योंकि यह वह हिस्सा है जहाँ वाक्य के हर अंत में नेटवर्क को यह बताने के लिए एक टोकन होगा कि इनपुट समाप्त हो गया है। वाक्य के प्रत्येक शब्द के लिए, यह शब्दकोश में उपयुक्त शब्द से इंडेक्स प्राप्त करेगा और वाक्य के अंत में एक टोकन जोड़ेगा।
def indexesFromSentence(lang, sentence):
return [lang.word2index[word] for word in sentence.split(' ')]
def tensorFromSentence(lang, sentence):
indexes = indexesFromSentence(lang, sentence)
indexes.append(EOS_token)
return torch.tensor(indexes, dtype=torch.long, device=device).view(-1, 1)
def tensorsFromPair(input_lang, output_lang, pair):
input_tensor = tensorFromSentence(input_lang, pair[0])
target_tensor = tensorFromSentence(output_lang, pair[1])
return (input_tensor, target_tensor)
Seq2Seq मॉडल

PyTorch Seq2seq मॉडल एक प्रकार का मॉडल है जो Py का उपयोग करता है।Torमॉडल के शीर्ष पर ch एनकोडर डिकोडर लगा हुआ है। एनकोडर वाक्य को शब्द-दर-शब्द, ज्ञात शब्दों की सूची में इंडेक्स के साथ एनकोड करेगा, और डिकोडर इनपुट को क्रम से डिकोड करके आउटपुट का अनुमान लगाएगा और संभव होने पर अंतिम इनपुट को अगले इनपुट के रूप में उपयोग करने का प्रयास करेगा। इस विधि से, वाक्य बनाने के लिए अगले इनपुट का अनुमान लगाना भी संभव है। प्रत्येक वाक्य को अनुक्रम के अंत को चिह्नित करने के लिए एक टोकन दिया जाएगा। अनुमान के अंत में, आउटपुट के अंत को चिह्नित करने के लिए भी एक टोकन होगा। इस प्रकार, एनकोडर से डिकोडर को आउटपुट का अनुमान लगाने के लिए एक स्थिति भेजी जाएगी।

एनकोडर हमारे इनपुट वाक्य को क्रम से शब्द दर शब्द एनकोड करेगा और अंत में वाक्य के अंत को चिह्नित करने के लिए एक टोकन होगा। एनकोडर में एक एम्बेडिंग लेयर और एक GRU लेयर्स शामिल हैं। एम्बेडिंग लेयर एक लुकअप टेबल है जो हमारे इनपुट की एम्बेडिंग को शब्दों के एक निश्चित आकार के शब्दकोश में संग्रहीत करती है। इसे GRU लेयर में पास किया जाएगा। GRU लेयर एक गेटेड रिकरंट यूनिट है जिसमें कई लेयर प्रकार होते हैं RNN जो अनुक्रमित इनपुट की गणना करेगा। यह परत पिछले एक से छिपी हुई स्थिति की गणना करेगी और रीसेट, अपडेट और नए गेट्स को अपडेट करेगी।

डिकोडर एनकोडर आउटपुट से इनपुट को डिकोड करेगा। यह अगले आउटपुट का पूर्वानुमान लगाने की कोशिश करेगा और यदि संभव हो तो इसे अगले इनपुट के रूप में उपयोग करने का प्रयास करेगा। डिकोडर में एक एम्बेडिंग लेयर, GRU लेयर और एक लीनियर लेयर शामिल है। एम्बेडिंग लेयर आउटपुट के लिए एक लुकअप टेबल बनाएगी और अनुमानित आउटपुट स्थिति की गणना करने के लिए इसे GRU लेयर में पास करेगी। उसके बाद, एक लीनियर लेयर अनुमानित आउटपुट के सही मूल्य को निर्धारित करने के लिए एक्टिवेशन फ़ंक्शन की गणना करने में मदद करेगी।
class Encoder(nn.Module):
def __init__(self, input_dim, hidden_dim, embbed_dim, num_layers):
super(Encoder, self).__init__()
#set the encoder input dimesion , embbed dimesion, hidden dimesion, and number of layers
self.input_dim = input_dim
self.embbed_dim = embbed_dim
self.hidden_dim = hidden_dim
self.num_layers = num_layers
#initialize the embedding layer with input and embbed dimention
self.embedding = nn.Embedding(input_dim, self.embbed_dim)
#intialize the GRU to take the input dimetion of embbed, and output dimention of hidden and
#set the number of gru layers
self.gru = nn.GRU(self.embbed_dim, self.hidden_dim, num_layers=self.num_layers)
def forward(self, src):
embedded = self.embedding(src).view(1,1,-1)
outputs, hidden = self.gru(embedded)
return outputs, hidden
class Decoder(nn.Module):
def __init__(self, output_dim, hidden_dim, embbed_dim, num_layers):
super(Decoder, self).__init__()
#set the encoder output dimension, embed dimension, hidden dimension, and number of layers
self.embbed_dim = embbed_dim
self.hidden_dim = hidden_dim
self.output_dim = output_dim
self.num_layers = num_layers
# initialize every layer with the appropriate dimension. For the decoder layer, it will consist of an embedding, GRU, a Linear layer and a Log softmax activation function.
self.embedding = nn.Embedding(output_dim, self.embbed_dim)
self.gru = nn.GRU(self.embbed_dim, self.hidden_dim, num_layers=self.num_layers)
self.out = nn.Linear(self.hidden_dim, output_dim)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, input, hidden):
# reshape the input to (1, batch_size)
input = input.view(1, -1)
embedded = F.relu(self.embedding(input))
output, hidden = self.gru(embedded, hidden)
prediction = self.softmax(self.out(output[0]))
return prediction, hidden
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device, MAX_LENGTH=MAX_LENGTH):
super().__init__()
#initialize the encoder and decoder
self.encoder = encoder
self.decoder = decoder
self.device = device
def forward(self, source, target, teacher_forcing_ratio=0.5):
input_length = source.size(0) #get the input length (number of words in sentence)
batch_size = target.shape[1]
target_length = target.shape[0]
vocab_size = self.decoder.output_dim
#initialize a variable to hold the predicted outputs
outputs = torch.zeros(target_length, batch_size, vocab_size).to(self.device)
#encode every word in a sentence
for i in range(input_length):
encoder_output, encoder_hidden = self.encoder(source[i])
#use the encoder’s hidden layer as the decoder hidden
decoder_hidden = encoder_hidden.to(device)
#add a token before the first predicted word
decoder_input = torch.tensor([SOS_token], device=device) # SOS
#topk is used to get the top K value over a list
#predict the output word from the current target word. If we enable the teaching force, then the #next decoder input is the next word, else, use the decoder output highest value.
for t in range(target_length):
decoder_output, decoder_hidden = self.decoder(decoder_input, decoder_hidden)
outputs[t] = decoder_output
teacher_force = random.random() < teacher_forcing_ratio
topv, topi = decoder_output.topk(1)
input = (target[t] if teacher_force else topi)
if(teacher_force == False and input.item() == EOS_token):
break
return outputs
चरण 3) मॉडल का प्रशिक्षण
Seq2seq मॉडल में प्रशिक्षण प्रक्रिया वाक्यों के प्रत्येक जोड़े को उनके लैंग इंडेक्स से टेंसर में परिवर्तित करने से शुरू होती है। हमारा सीक्वेंस टू सीक्वेंस मॉडल नुकसान की गणना करने के लिए ऑप्टिमाइज़र और NLLLoss फ़ंक्शन के रूप में SGD का उपयोग करेगा। प्रशिक्षण प्रक्रिया सही आउटपुट की भविष्यवाणी करने के लिए मॉडल को वाक्य की जोड़ी खिलाने से शुरू होती है। प्रत्येक चरण में, मॉडल से आउटपुट की गणना नुकसान का पता लगाने और मापदंडों को अपडेट करने के लिए सही शब्दों के साथ की जाएगी। इसलिए क्योंकि आप 75000 पुनरावृत्तियों का उपयोग करेंगे, हमारा सीक्वेंस टू सीक्वेंस मॉडल हमारे डेटासेट से यादृच्छिक 75000 जोड़े उत्पन्न करेगा।
teacher_forcing_ratio = 0.5
def clacModel(model, input_tensor, target_tensor, model_optimizer, criterion):
model_optimizer.zero_grad()
input_length = input_tensor.size(0)
loss = 0
epoch_loss = 0
# print(input_tensor.shape)
output = model(input_tensor, target_tensor)
num_iter = output.size(0)
print(num_iter)
#calculate the loss from a predicted sentence with the expected result
for ot in range(num_iter):
loss += criterion(output[ot], target_tensor[ot])
loss.backward()
model_optimizer.step()
epoch_loss = loss.item() / num_iter
return epoch_loss
def trainModel(model, source, target, pairs, num_iteration=20000):
model.train()
optimizer = optim.SGD(model.parameters(), lr=0.01)
criterion = nn.NLLLoss()
total_loss_iterations = 0
training_pairs = [tensorsFromPair(source, target, random.choice(pairs))
for i in range(num_iteration)]
for iter in range(1, num_iteration+1):
training_pair = training_pairs[iter - 1]
input_tensor = training_pair[0]
target_tensor = training_pair[1]
loss = clacModel(model, input_tensor, target_tensor, optimizer, criterion)
total_loss_iterations += loss
if iter % 5000 == 0:
avarage_loss= total_loss_iterations / 5000
total_loss_iterations = 0
print('%d %.4f' % (iter, avarage_loss))
torch.save(model.state_dict(), 'mytraining.pt')
return model
चरण 4) मॉडल का परीक्षण करें
Seq2seq Py की मूल्यांकन प्रक्रियाTorch का उद्देश्य मॉडल आउटपुट की जाँच करना है। अनुक्रम-से-अनुक्रम मॉडल के प्रत्येक जोड़े को मॉडल में फीड किया जाएगा और अनुमानित शब्द उत्पन्न किए जाएंगे। इसके बाद, सही इंडेक्स खोजने के लिए प्रत्येक आउटपुट में उच्चतम मान देखा जाएगा। अंत में, आप अपने मॉडल के अनुमान की तुलना वास्तविक वाक्य से करेंगे।
def evaluate(model, input_lang, output_lang, sentences, max_length=MAX_LENGTH):
with torch.no_grad():
input_tensor = tensorFromSentence(input_lang, sentences[0])
output_tensor = tensorFromSentence(output_lang, sentences[1])
decoded_words = []
output = model(input_tensor, output_tensor)
# print(output_tensor)
for ot in range(output.size(0)):
topv, topi = output[ot].topk(1)
# print(topi)
if topi[0].item() == EOS_token:
decoded_words.append('<EOS>')
break
else:
decoded_words.append(output_lang.index2word[topi[0].item()])
return decoded_words
def evaluateRandomly(model, source, target, pairs, n=10):
for i in range(n):
pair = random.choice(pairs)
print(‘source {}’.format(pair[0]))
print(‘target {}’.format(pair[1]))
output_words = evaluate(model, source, target, pair)
output_sentence = ' '.join(output_words)
print(‘predicted {}’.format(output_sentence))
अब, आइए Seq to Seq के साथ अपना प्रशिक्षण शुरू करें, जिसमें पुनरावृत्तियों की संख्या 75000 और RNN परत की संख्या 1 तथा छिपा हुआ आकार 512 है।
lang1 = 'eng'
lang2 = 'ind'
source, target, pairs = process_data(lang1, lang2)
randomize = random.choice(pairs)
print('random sentence {}'.format(randomize))
#print number of words
input_size = source.n_words
output_size = target.n_words
print('Input : {} Output : {}'.format(input_size, output_size))
embed_size = 256
hidden_size = 512
num_layers = 1
num_iteration = 100000
#create encoder-decoder model
encoder = Encoder(input_size, hidden_size, embed_size, num_layers)
decoder = Decoder(output_size, hidden_size, embed_size, num_layers)
model = Seq2Seq(encoder, decoder, device).to(device)
#print model
print(encoder)
print(decoder)
model = trainModel(model, source, target, pairs, num_iteration)
evaluateRandomly(model, source, target, pairs)
जैसा कि आप देख सकते हैं, हमारा पूर्वानुमानित वाक्य बहुत अच्छी तरह से मेल नहीं खाता है, इसलिए उच्च सटीकता प्राप्त करने के लिए, आपको बहुत अधिक डेटा के साथ प्रशिक्षण करने की आवश्यकता है और अनुक्रम से अनुक्रम सीखने का उपयोग करके अधिक पुनरावृत्तियों और परतों की संख्या जोड़ने की कोशिश करनी होगी।
random sentence ['tom is finishing his work', 'tom sedang menyelesaikan pekerjaannya']
Input : 3551 Output : 4253
Encoder(
(embedding): Embedding(3551, 256)
(gru): GRU(256, 512)
)
Decoder(
(embedding): Embedding(4253, 256)
(gru): GRU(256, 512)
(out): Linear(in_features=512, out_features=4253, bias=True)
(softmax): LogSoftmax()
)
Seq2Seq(
(encoder): Encoder(
(embedding): Embedding(3551, 256)
(gru): GRU(256, 512)
)
(decoder): Decoder(
(embedding): Embedding(4253, 256)
(gru): GRU(256, 512)
(out): Linear(in_features=512, out_features=4253, bias=True)
(softmax): LogSoftmax()
)
)
5000 4.0906
10000 3.9129
15000 3.8171
20000 3.8369
25000 3.8199
30000 3.7957
35000 3.8037
40000 3.8098
45000 3.7530
50000 3.7119
55000 3.7263
60000 3.6933
65000 3.6840
70000 3.7058
75000 3.7044
> this is worth one million yen
= ini senilai satu juta yen
< tom sangat satu juta yen <EOS>
> she got good grades in english
= dia mendapatkan nilai bagus dalam bahasa inggris
< tom meminta nilai bagus dalam bahasa inggris <EOS>
> put in a little more sugar
= tambahkan sedikit gula
< tom tidak <EOS>
> are you a japanese student
= apakah kamu siswa dari jepang
< tom kamu memiliki yang jepang <EOS>
> i apologize for having to leave
= saya meminta maaf karena harus pergi
< tom tidak maaf karena harus pergi ke
> he isnt here is he
= dia tidak ada di sini kan
< tom tidak <EOS>
> speaking about trips have you ever been to kobe
= berbicara tentang wisata apa kau pernah ke kobe
< tom tidak <EOS>
> tom bought me roses
= tom membelikanku bunga mawar
< tom tidak bunga mawar <EOS>
> no one was more surprised than tom
= tidak ada seorangpun yang lebih terkejut dari tom
< tom ada orang yang lebih terkejut <EOS>
> i thought it was true
= aku kira itu benar adanya
< tom tidak <EOS>