SQL सर्वर Archiटेक्चर (व्याख्या)
⚡ स्मार्ट सारांश
SQL सर्वर Archiयह संरचना क्लाइंट-सर्वर मॉडल का अनुसरण करती है, जिसे तीन मुख्य परतों में व्यवस्थित किया गया है: नेटवर्क संचार के लिए प्रोटोकॉल परत, क्वेरी प्रोसेसिंग के लिए रिलेशनल इंजन और डेटा प्रबंधन और पुनर्प्राप्ति के लिए स्टोरेज इंजन।

एमएस एसक्यूएल सर्वर एक क्लाइंट-सर्वर आर्किटेक्चर है। एमएस एसक्यूएल सर्वर प्रक्रिया क्लाइंट एप्लिकेशन द्वारा अनुरोध भेजने से शुरू होती है। एसक्यूएल सर्वर अनुरोध को स्वीकार करता है, उस पर कार्रवाई करता है और संसाधित डेटा के साथ जवाब देता है। आइए नीचे दिखाए गए संपूर्ण आर्किटेक्चर पर विस्तार से चर्चा करें:
नीचे दिए गए आरेख में दर्शाए अनुसार, SQL सर्वर में तीन प्रमुख घटक होते हैं। Archiटेक्चर:
- प्रोटोकॉल लेयर
- रिलेशनल इंजन
- स्टोरेज इंजन
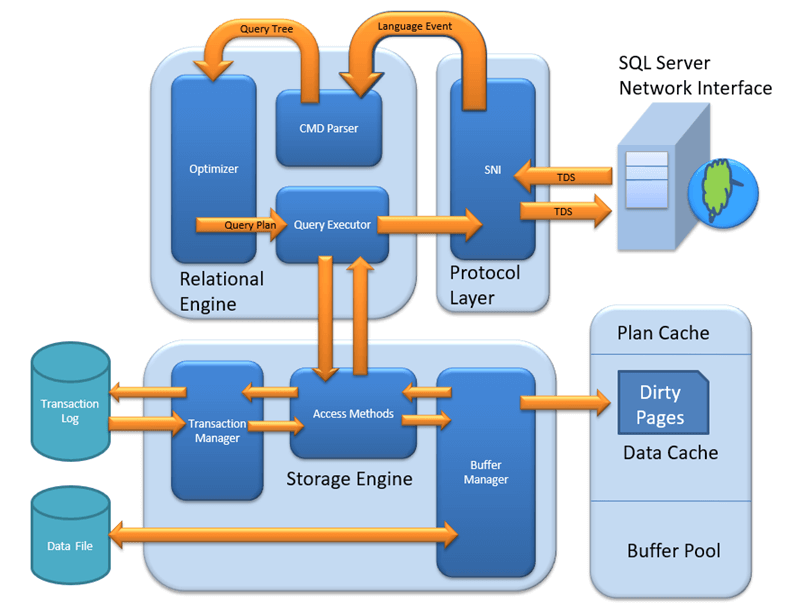
प्रोटोकॉल परत – एसएनआई
SQL सर्वर प्रोटोकॉल लेयर, जिसे सर्वर नेटवर्क इंटरफ़ेस (SNI) भी कहा जाता है, तीन प्रकार के क्लाइंट-सर्वर आर्किटेक्चर को सपोर्ट करता है। प्रत्येक प्रोटोकॉल एक अलग नेटवर्क परिदृश्य के लिए उपयुक्त है। आंतरिक रूप से क्वेरी कैसे प्रोसेस होती हैं, यह समझने से पहले इन प्रोटोकॉल को समझना आवश्यक है।
शेयर्ड मेमोरी
सुबह-सुबह की बातचीत के एक उदाहरण पर विचार करें। टॉम और उसकी माँ एक ही जगह पर हैं, यानी अपने घर पर। टॉम कॉफ़ी माँगता है और माँ उसे सीधे परोस देती है। इसी तरह, जब क्लाइंट और सर्वर एक ही मशीन पर चलते हैं, तो SQL सर्वर साझा मेमोरी प्रोटोकॉल प्रदान करता है। दोनों बिना किसी नेटवर्क बाधा के साझा मेमोरी के माध्यम से संचार करते हैं।

सादृश्य: टॉम क्लाइंट से, मॉम SQL सर्वर से, होम मशीन से और मौखिक संचार शेयर्ड मेमोरी प्रोटोकॉल से संबंधित है।

कॉन्फ़िगरेशन संबंधी नोट्स: In एसक्यूएल प्रबंधन स्टूडियोस्थानीय कनेक्शन के लिए "सर्वर नाम" विकल्प ".", "localhost", "127.0.0.1", या "Machine\Instance" हो सकता है।
टीसीपी / आईपी
अब मान लीजिए कि टॉम को 10 किलोमीटर दूर स्थित एक दुकान से कॉफी चाहिए। टॉम घर पर है और कॉफी की दुकान एक व्यस्त बाज़ार में है। वे सेलुलर नेटवर्क के माध्यम से संवाद करते हैं। इसी प्रकार, SQL सर्वर भी यही सुविधा प्रदान करता है। टीसीपी / आईपी प्रोटोकॉल जब क्लाइंट और SQL सर्वर नेटवर्क के माध्यम से जुड़े अलग-अलग मशीनों पर हों।

सादृश्य: टॉम क्लाइंट से जुड़ा है, कॉफी शॉप SQL सर्वर से जुड़ा है, घर और बाजार दूरस्थ स्थानों से जुड़े हैं, और सेलुलर नेटवर्क TCP/IP प्रोटोकॉल से जुड़ा है।

कॉन्फ़िगरेशन संबंधी नोट्स: SQL मैनेजमेंट स्टूडियो में, TCP/IP कनेक्शन के लिए "सर्वर नाम" विकल्प "सर्वर का मशीन\इंस्टेंस" होना चाहिए। SQL सर्वर डिफ़ॉल्ट रूप से TCP/IP कनेक्शन के लिए पोर्ट 1433 का उपयोग करता है।
नाम दिया पाइप्स
अंत में, टॉम अपनी पड़ोसी सिएरा से हरी चाय लेना चाहता है। वे पड़ोसी होने के नाते एक ही स्थान पर स्थित हैं और एक इंट्रा-नेटवर्क के माध्यम से संवाद करते हैं। इसी प्रकार, SQL सर्वर क्लाइंट और सर्वर के लोकल एरिया नेटवर्क (LAN) के माध्यम से कनेक्ट होने पर नेम्ड पाइप प्रोटोकॉल प्रदान करता है।

सादृश्य: टॉम क्लाइंट से मैप होता है, सिएरा SQL सर्वर से मैप होता है, पड़ोसी होने का मतलब LAN से मैप होता है, और इंट्रा-नेटवर्क का मतलब नेम्ड पाइप प्रोटोकॉल से मैप होता है।
कॉन्फ़िगरेशन संबंधी नोट्स: नेम्ड पाइप्स डिफ़ॉल्ट रूप से अक्षम होता है और इसे SQL कॉन्फ़िगरेशन मैनेजर के माध्यम से सक्षम किया जाना चाहिए।
टीडीएस क्या है?
अब जबकि क्लाइंट-सर्वर आर्किटेक्चर के तीन प्रकार स्पष्ट हो चुके हैं, आइए टीडीएस पर एक नज़र डालते हैं:
- टीडीएस का तात्पर्य टेबुलर डेटा स्ट्रीम से है।
- ये तीनों प्रोटोकॉल टीडीएस पैकेट का उपयोग करते हैं।
- टीडीएस को नेटवर्क पैकेट में समाहित किया जाता है, जिससे क्लाइंट मशीन से सर्वर मशीन तक डेटा का स्थानांतरण संभव हो पाता है।
- टीडीएस को सर्वप्रथम साइबेस द्वारा विकसित किया गया था और अब यह इसके स्वामित्व में है। Microsoft.
निम्नलिखित तालिका तीन SQL सर्वर कनेक्शन प्रोटोकॉल की तुलना करती है:
| Feature | शेयर्ड मेमोरी | टीसीपी / आईपी | नाम दिया पाइप्स |
|---|---|---|---|
| नेटवर्क स्कोप | वही मशीन | रिमोट (WAN/इंटरनेट) | केवल LAN |
| डिफ़ॉल्ट पोर्ट | एन / ए | 1433 | 445 |
| प्रदर्शन | सबसे तेज़ (नेटवर्क ओवरहेड नहीं) | अच्छा (WAN के लिए अनुकूलित) | अच्छा (LAN के लिए अनुकूलित) |
| डिफ़ॉल्ट रूप से सक्षम | हाँ | हाँ | नहीं |
| सबसे अच्छा उपयोग मामला | स्थानीय विकास और परीक्षण | उत्पादन रिमोट एक्सेस | विश्वसनीय लैन वातावरण |
प्रोटोकॉल लेयर नेटवर्क संचार को संभालती है, और SQL सर्वर आर्किटेक्चर में अगला चरण क्वेरी को प्रोसेस करना है। यहीं पर रिलेशनल इंजन का कार्य शुरू होता है।
रिलेशनल इंजन
रिलेशनल इंजन को क्वेरी प्रोसेसर के नाम से भी जाना जाता है। इसमें SQL सर्वर के वे घटक होते हैं जो यह निर्धारित करते हैं कि किसी क्वेरी को क्या करना है और उसे सबसे कुशल तरीके से कैसे निष्पादित किया जा सकता है। यह स्टोरेज इंजन से डेटा का अनुरोध करके और प्राप्त परिणामों को संसाधित करके उपयोगकर्ता की क्वेरी को निष्पादित करने के लिए जिम्मेदार है।
आर्किटेक्चरल डायग्राम में दर्शाए अनुसार, रिलेशनल इंजन के तीन प्रमुख घटक हैं:
सीएमडी पार्सर
प्रोटोकॉल लेयर से प्राप्त डेटा को रिलेशनल इंजन को भेजा जाता है। CMD पार्सर क्वेरी डेटा प्राप्त करने वाला पहला घटक है। इसका मुख्य कार्य क्वेरी में वाक्यविन्यास और अर्थ संबंधी त्रुटियों की जाँच करना और फिर एक क्वेरी ट्री उत्पन्न करना है।

वाक्यविन्यास जांच: अन्य सभी प्रोग्रामिंग भाषाओं की तरह, SQL सर्वर में भी पूर्वनिर्धारित कीवर्ड और व्याकरण नियम होते हैं। SELECT, INSERT, UPDATE और कई अन्य कीवर्ड पूर्वनिर्धारित कीवर्ड सूची में शामिल हैं। CMD पार्सर यह सुनिश्चित करता है कि इनपुट इन नियमों का पालन करता है। यदि उपयोगकर्ता का इनपुट अपेक्षित सिंटैक्स से भिन्न होता है, तो पार्सर त्रुटि लौटाता है।
उदाहरण: मान लीजिए कोई रूसी व्यक्ति किसी जापानी रेस्तरां में जाता है और रूसी भाषा में ऑर्डर देता है। वेटर को केवल जापानी भाषा समझ आती है और वह ऑर्डर प्रोसेस नहीं कर सकता। इसी तरह, यदि कोई उपयोगकर्ता "SELECT" के बजाय "SELECR" टाइप करता है, तो CMD पार्सर त्रुटि देता है क्योंकि वह कीवर्ड को पहचान नहीं पाता है।
अर्थगत जांच: यह प्रक्रिया नॉर्मलाइज़र द्वारा की जाती है। यह जाँचता है कि क्वेरी में शामिल कॉलम नाम, टेबल नाम और अन्य ऑब्जेक्ट स्कीमा में मौजूद हैं या नहीं। यदि वे मौजूद हैं, तो नॉर्मलाइज़र उन्हें क्वेरी से जोड़ देता है। इस प्रक्रिया को बाइंडिंग भी कहा जाता है। जब उपयोगकर्ता क्वेरी में कोई व्यू शामिल होता है, तो नॉर्मलाइज़र उसे आंतरिक रूप से संग्रहीत व्यू परिभाषा से बदल देता है।
उदाहरण: रनिंग SELECT * from USER_ID यदि डेटाबेस में USER_ID टेबल मौजूद नहीं है, तो इससे पार्सर सिमेंटिक जांच के दौरान एक त्रुटि उत्पन्न करेगा।
क्वेरी ट्री बनाएं: यह चरण क्वेरी को चलाने के विभिन्न तरीकों को दर्शाने वाले अलग-अलग निष्पादन ट्री उत्पन्न करता है। सभी ट्री एक ही वांछित आउटपुट उत्पन्न करते हैं।
अनुकूलक
ऑप्टिमाइज़र उपयोगकर्ता की क्वेरी के लिए एक निष्पादन योजना बनाता है। यह योजना निर्धारित करती है कि क्वेरी कैसे निष्पादित होगी। सभी क्वेरी ऑप्टिमाइज़्ड नहीं होती हैं। ऑप्टिमाइज़ेशन SELECT, INSERT, DELETE और UPDATE जैसे DML (डेटा मॉडिफिकेशन लैंग्वेज) कमांड पर लागू होता है। CREATE और ALTER जैसे DDL कमांड ऑप्टिमाइज़्ड नहीं होते हैं, लेकिन उन्हें एक आंतरिक रूप में संकलित किया जाता है।

क्वेरी की लागत सीपीयू उपयोग, मेमोरी उपयोग और इनपुट/आउटपुट आवश्यकताओं जैसे कारकों के आधार पर निर्धारित की जाती है। ऑप्टिमाइज़र का काम सबसे कम लागत में सबसे प्रभावी निष्पादन योजना खोजना है, न कि अनिवार्य रूप से सर्वोत्तम योजना खोजना।
उदाहरण: मान लीजिए आप एक ऑनलाइन बैंक खाता खोलना चाहते हैं। एक बैंक अधिकतम 2 दिन में खाता खोल देता है। आपके पास 20 अन्य बैंकों की सूची भी है, जिनमें से कुछ बैंक कम समय में खाता खोल सकते हैं। सभी 20 बैंकों में खोजने पर शायद आपको कोई तेज़ विकल्प न मिले, और इस खोज में ही समय लगता है। पहले बैंक से ही खाता खोलना बेहतर होता। इसी प्रकार, SQL ऑप्टिमाइज़र क्वेरी के चलने के समय को कम करने के लिए व्यापक और अनुमानित एल्गोरिदम का उपयोग करता है।
ऑप्टिमाइज़र तीन चरणों में खोज करता है:
चरण 0: सरल योजना की खोज
यह प्री-ऑप्टिमाइजेशन चरण है। कुछ क्वेरी के लिए, केवल एक ही व्यावहारिक योजना मौजूद होती है, जिसे ट्रिवियल प्लान कहा जाता है। आगे खोज करने की कोई आवश्यकता नहीं है क्योंकि अतिरिक्त खोज करने पर भी वही निष्पादन योजना अतिरिक्त लागत पर मिल जाएगी।
चरण 1: लेनदेन प्रसंस्करण योजनाओं की खोज करें
इसमें सरल और जटिल दोनों प्रकार की योजनाओं की खोज शामिल है। सरल योजना खोज में कॉलम और इंडेक्स डेटा का सांख्यिकीय विश्लेषण किया जाता है, जो आमतौर पर प्रति टेबल एक इंडेक्स तक सीमित होता है। यदि कोई सरल योजना नहीं मिलती है, तो प्रति टेबल कई इंडेक्स वाली अधिक जटिल खोज की जाती है।
चरण 2: समानांतर प्रसंस्करण और अनुकूलन
यदि पिछली रणनीतियों से कोई उपयुक्त योजना नहीं बन पाती है, तो ऑप्टिमाइज़र मशीन की प्रसंस्करण क्षमताओं के आधार पर समानांतर प्रसंस्करण की संभावनाओं की खोज करता है। यदि समानांतर प्रसंस्करण संभव नहीं है, तो अंतिम अनुकूलन चरण शुरू होता है जो सभी शेष विकल्पों का उपयोग करके सर्वोत्तम संभव निष्पादन योजना का पता लगाता है।
क्वेरी निष्पादक
क्वेरी एक्ज़ीक्यूटर स्टोरेज इंजन में एक्सेस मेथड को कॉल करता है। यह निष्पादन के लिए आवश्यक डेटा-फ़ेचिंग लॉजिक युक्त एक निष्पादन योजना प्रदान करता है। स्टोरेज इंजन से डेटा प्राप्त होने के बाद, परिणाम प्रोटोकॉल लेयर पर प्रकाशित किया जाता है और अंतिम उपयोगकर्ता को भेजा जाता है।

रिलेशनल इंजन द्वारा क्वेरी को निष्पादित करने का तरीका निर्धारित करने के बाद, स्टोरेज इंजन भौतिक डेटा संचालन को संभालता है। यह परत डेटा को डिस्क में संग्रहीत करने, कैश करने और वहां से पुनर्प्राप्त करने का प्रबंधन करती है।
स्टोरेज इंजन
स्टोरेज इंजन डिस्क या एसएएन जैसे स्टोरेज सिस्टम में डेटा को स्टोर करने और आवश्यकता पड़ने पर उसे पुनः प्राप्त करने के लिए जिम्मेदार होता है। स्टोरेज इंजन के घटकों की जांच करने से पहले, यह समझना महत्वपूर्ण है कि डेटा को भौतिक रूप से कैसे संग्रहीत किया जाता है।

डेटा फ़ाइलें और सीमाएँ
डेटा फ़ाइलें भौतिक रूप से डेटा को डेटा पेजों के रूप में संग्रहीत करती हैं, जिसमें प्रत्येक पेज का आकार 8KB होता है। यह सबसे छोटी भंडारण इकाई है। SQL सर्वरडेटा पेजों को तार्किक रूप से एक्सटेंट में समूहीकृत किया जाता है। किसी भी ऑब्जेक्ट को सीधे तौर पर कोई अलग पेज असाइन नहीं किया जाता है; इसके बजाय, रखरखाव एक्सटेंट के माध्यम से किया जाता है। प्रत्येक पेज में एक पेज हेडर (96 बाइट्स) होता है जिसमें पेज प्रकार, पेज संख्या, उपयोग किया गया स्थान, खाली स्थान और अगले और पिछले पेजों के पॉइंटर जैसे मेटाडेटा होते हैं।
फ़ाइल प्रकार

प्राथमिक फ़ाइल: प्रत्येक डेटाबेस में एक प्राथमिक फ़ाइल होती है। इसमें टेबल, व्यू, ट्रिगर और अन्य ऑब्जेक्ट से संबंधित सभी महत्वपूर्ण डेटा संग्रहीत होता है। इसका एक्सटेंशन आमतौर पर .mdf होता है, लेकिन यह कोई भी एक्सटेंशन हो सकता है।
द्वितीयक फ़ाइल: किसी डेटाबेस में एकाधिक द्वितीयक फ़ाइलें हो भी सकती हैं और नहीं भी। ये वैकल्पिक होती हैं और इनमें उपयोगकर्ता-विशिष्ट डेटा होता है। इनका एक्सटेंशन आमतौर पर .ndf होता है, लेकिन कोई भी एक्सटेंशन हो सकता है।
बोटा दस्तावेज: इन्हें राइट-अहेड लॉग्स के नाम से भी जाना जाता है। इनका एक्सटेंशन .ldf होता है। लॉग फाइलों का उपयोग ट्रांजैक्शन मैनेजमेंट, अवांछित इंस्टेंसेस से रिकवरी और अनकमिटेड ट्रांजैक्शन को रोलबैक करने के लिए किया जाता है।
स्टोरेज इंजन के तीन मुख्य घटक हैं। डेटा तक पहुंच और उसकी अखंडता को प्रबंधित करने में प्रत्येक घटक की एक विशिष्ट भूमिका होती है।
पहुंच विधि
एक्सेस मेथड क्वेरी एक्जीक्यूटर और के बीच एक इंटरफ़ेस के रूप में कार्य करता है। Buffer मैनेजर या ट्रांजैक्शन लॉग। यह स्वयं निष्पादन नहीं करता है, बल्कि क्वेरी के प्रकार का निर्धारण करता है:
- यदि क्वेरी एक है SELECT कथन (DML)इसे आगे भेज दिया जाता है Buffer आगे की प्रक्रिया के लिए प्रबंधक से संपर्क करें।
- यदि क्वेरी एक है नॉन-सेलेक्ट स्टेटमेंट (डीडीएल और डीएमएल)इसे ट्रांजैक्शन मैनेजर को भेजा जाता है। इसमें मुख्य रूप से UPDATE, INSERT और DELETE स्टेटमेंट शामिल होते हैं।

Buffer प्रबंधक
RSI Buffer मैनेजर प्लान कैश, डेटा पार्सिंग और डर्टी पेज हैंडलिंग के लिए मुख्य कार्यों का प्रबंधन करता है।

योजना कैश
मौजूदा क्वेरी प्लान: RSI Buffer मैनेजर यह जांचता है कि निष्पादन योजना संग्रहीत प्लान कैश में मौजूद है या नहीं। यदि यह मौजूद है, तो कैश्ड क्वेरी प्लान और उससे संबंधित डेटा कैश का सीधे उपयोग किया जाता है।
पहली बार कैशिंग प्लान: यदि पहली बार क्वेरी निष्पादन योजना जटिल है, तो इसे प्लान कैश में संग्रहीत किया जाता है। इससे यह सुनिश्चित होता है कि अगली बार जब SQL सर्वर को वही क्वेरी प्राप्त हो, तो वह तेजी से उपलब्ध हो।
डेटा पार्सिंग: Buffer कैश और डेटा संग्रहण
RSI Buffer मैनेजर आवश्यक डेटा तक पहुंच प्रदान करता है। डेटा कैश में मौजूद है या नहीं, इसके आधार पर दो तरीके संभव हैं:
Buffer कैश – सॉफ्ट पार्सिंग
RSI Buffer मैनेजर डेटा की तलाश करता है Buffer कैश। यदि डेटा मौजूद है, तो क्वेरी एक्जीक्यूटर इसका सीधे उपयोग करता है। इससे प्रदर्शन बेहतर होता है क्योंकि डिस्क स्टोरेज से डेटा लाने की तुलना में कैश से डेटा लाने में कम I/O ऑपरेशन लगते हैं।

डेटा संग्रहण – हार्ड पार्सिंग
यदि डेटा मौजूद नहीं है Buffer कैश में, डिस्क पर मौजूद डेटा स्टोरेज में आवश्यक डेटा खोजा जाता है। फिर उस डेटा को भविष्य में उपयोग के लिए डेटा कैश में भी संग्रहीत किया जाता है।

लेनदेन प्रबंधक
ट्रांज़ैक्शन मैनेजर तब सक्रिय होता है जब एक्सेस मेथड यह निर्धारित करता है कि क्वेरी एक गैर-SELECT स्टेटमेंट है। यह कई उप-घटकों के माध्यम से डेटा की स्थिरता और स्थायित्व सुनिश्चित करता है:

लॉग मैनेजर
लॉग मैनेजर रखता है tracसिस्टम में किए गए सभी अपडेट की जानकारी ट्रांजैक्शन लॉग में संग्रहीत लॉग के माध्यम से प्राप्त की जाती है। प्रत्येक लॉग एंट्री में लॉग सीक्वेंस नंबर, ट्रांजैक्शन आईडी और डेटा मॉडिफिकेशन रिकॉर्ड शामिल होता है। यह तंत्र tracks ने लेन-देन को प्रतिबद्ध और रोलबैक किया।
लॉक मैनेजर
किसी लेन-देन के दौरान, संग्रहण में मौजूद संबंधित डेटा लॉक अवस्था में चला जाता है। लॉक मैनेजर इस प्रक्रिया को संभालता है, जिससे डेटा की स्थिरता और अलगाव सुनिश्चित होता है। इन गुणों को ACID (एसिडिक एसिडिटी) के नाम से भी जाना जाता है।Atomस्थिरता, एकाकीपन, स्थायित्व)।
निष्पादन प्रक्रिया
निष्पादन प्रक्रिया निम्नलिखित चरणों का अनुसरण करती है:
- लॉग मैनेजर लॉगिंग शुरू करता है और लॉक मैनेजर संबंधित डेटा को लॉक कर देता है।
- डेटा की एक प्रति इसमें रखी जाती है Buffer कैश।
- अपडेट किए जाने वाले डेटा की एक प्रति लॉग में रखी जाती है। Bufferऔर सभी इवेंट डेटा में डेटा को अपडेट करते हैं। Buffer.
- संशोधित डेटा को संग्रहीत करने वाले पृष्ठों को इस प्रकार जाना जाता है: गंदे पन्ने.
चेकपॉइंट और राइट-अहेड लॉगिंग
चेकपॉइंट प्रक्रिया लगभग प्रति मिनट एक बार चलती है और डिस्क पर लिखने के लिए सभी डर्टी पेजों को चिह्नित करती है। हालाँकि, पेज को पहले लॉग फ़ाइल के डेटा पेज पर भेजा जाता है। Buffer लॉग। इस तंत्र को राइट-अहेड लॉगिंग के नाम से जाना जाता है। डिस्क पर लिखे जाने के बाद भी डर्टी पेज कैश में बने रहते हैं।
आलसी Writer
जब SQL सर्वर पर भारी लोड होता है और नए लेनदेन के लिए बफर मेमोरी की आवश्यकता होती है, तो यह कैश से डर्टी पेज को मुक्त कर देता है। Writer यह बफर पूल से डिस्क पर पेजों को साफ करने के लिए LRU (लीस्ट रिसेंटली यूज्ड) एल्गोरिदम पर काम करता है।
SQL सर्वर किसी क्वेरी को शुरू से अंत तक कैसे प्रोसेस करता है
प्रत्येक स्तर को अलग-अलग समझना महत्वपूर्ण है, लेकिन यह देखना कि वे एक साथ कैसे काम करते हैं, पूरी तस्वीर को स्पष्ट करता है। जब कोई क्लाइंट एप्लिकेशन SQL क्वेरी भेजता है, तो निम्नलिखित क्रम घटित होता है:
RSI प्रोटोकॉल लेयर यह साझा मेमोरी, टीसीपी/आईपी या नामित पाइप के माध्यम से अनुरोध प्राप्त करता है और इसे टीडीएस पैकेट में लपेटता है। रिलेशनल इंजन इसके बाद, सीएमडी पार्सर सिंटैक्स और सिमेंटिक्स की जांच करता है, ऑप्टिमाइज़र सबसे सस्ता निष्पादन प्लान तैयार करता है, और क्वेरी एक्जीक्यूटर डेटा पुनर्प्राप्ति शुरू करता है।
क्वेरी एक्जीक्यूटर कॉल करता है स्टोरेज इंजन का एक्सेस मेथड, जो SELECT क्वेरी को रूट करता है Buffer लेनदेन प्रबंधक को प्रबंधक और संशोधन संबंधी प्रश्न। Buffer मैनेजर प्लान कैश की जांच करता है और Buffer पहले डेटा को कैश किया जाता है (सॉफ्ट पार्सिंग)। यदि डेटा कैश में नहीं है, तो डिस्क से डेटा पढ़ा जाता है (हार्ड पार्सिंग)। राइट ऑपरेशन के लिए, ट्रांजैक्शन मैनेजर, लॉग मैनेजर, लॉक मैनेजर और चेकपॉइंट प्रक्रिया के साथ समन्वय स्थापित करता है ताकि एसिडिटी कंप्लायंस सुनिश्चित हो सके।
एक बार जब स्टोरेज इंजन अनुरोधित डेटा लौटा देता है, तो रिलेशनल इंजन परिणाम सेट को फॉर्मेट करता है, और प्रोटोकॉल लेयर उसी टीडीएस प्रोटोकॉल के माध्यम से इसे क्लाइंट एप्लिकेशन को वापस भेज देती है।
SQL सर्वर कनेक्शन के लिए सही प्रोटोकॉल का चुनाव कैसे करें
सही प्रोटोकॉल का चयन क्लाइंट और सर्वर के बीच भौतिक संबंध के साथ-साथ प्रदर्शन संबंधी आवश्यकताओं पर भी निर्भर करता है।
साझा मेमोरी का उपयोग करें जब क्लाइंट एप्लिकेशन SQL सर्वर के समान मशीन पर चलता है, तो यह सबसे तेज़ विकल्प है क्योंकि यह नेटवर्क संबंधी सभी अनावश्यकताओं को दूर करता है। यह स्थानीय विकास, परीक्षण और एकल-मशीन परिनियोजन के लिए आदर्श है।
TCP/IP का उपयोग करें जब क्लाइंट और सर्वर अलग-अलग मशीनों पर हों और WAN या इंटरनेट के माध्यम से जुड़े हों, तब यह प्रोटोकॉल सबसे अधिक उपयोग किया जाता है। SQL सर्वर डिफ़ॉल्ट रूप से पोर्ट 1433 पर सुनता है, और यह प्रोटोकॉल TLS के माध्यम से एन्क्रिप्टेड कनेक्शन का समर्थन करता है।
नामित पाइपों का उपयोग करें जब क्लाइंट और सर्वर एक ही विश्वसनीय LAN पर हों और आंतरिक नेटवर्क पर प्रदर्शन को प्राथमिकता दी जाए, तब Named Pipes डिफ़ॉल्ट रूप से अक्षम होता है और इसे SQL Server कॉन्फ़िगरेशन मैनेजर के माध्यम से सक्षम किया जाना चाहिए। आधुनिक अनुप्रयोगों में इसका उपयोग कम होता है, लेकिन पुराने इंट्रानेट अनुप्रयोगों के लिए यह उपयोगी बना हुआ है।