स्टेमिंग और लेमेटाइजेशन Python उदाहरण सहित NLTK
स्टेमिंग और लेमेटाइजेशन क्या है? Python एनएलटीके?
स्टेमिंग और लेमेटाइजेशन in Python NLTK प्राकृतिक भाषा प्रसंस्करण के लिए पाठ सामान्यीकरण तकनीकें हैं। इन तकनीकों का व्यापक रूप से पाठ प्रीप्रोसेसिंग के लिए उपयोग किया जाता है। स्टेमिंग और लेमेटाइज़ेशन के बीच अंतर यह है कि स्टेमिंग तेज़ है क्योंकि यह संदर्भ को जाने बिना शब्दों को काटता है, जबकि लेमेटाइज़ेशन धीमा है क्योंकि यह प्रसंस्करण से पहले शब्दों के संदर्भ को जानता है।
स्टेमिंग क्या है?
स्टेमिंग शब्दों के सामान्यीकरण की एक विधि है प्राकृतिक भाषा संसाधनयह एक ऐसी तकनीक है जिसमें वाक्य में शब्दों के एक समूह को उसके लुकअप को छोटा करने के लिए अनुक्रम में परिवर्तित किया जाता है। इस पद्धति में, समान अर्थ वाले लेकिन संदर्भ या वाक्य के अनुसार कुछ भिन्नता वाले शब्दों को सामान्यीकृत किया जाता है।
दूसरे शब्दों में, एक मूल शब्द होता है, लेकिन उसी शब्द के कई रूप होते हैं। उदाहरण के लिए, मूल शब्द है “खाना” और इसके रूप हैं “खाता है, खाना, खाया और इसी तरह”। इसी तरह, स्टेमिंग की मदद से Python, हम किसी भी भिन्नता का मूल शब्द पा सकते हैं।
उदाहरण के लिये
He was riding. He was taking the ride.
ऊपर दिए गए दोनों वाक्यों में अर्थ एक ही है, यानी अतीत में की गई गतिविधि। मनुष्य आसानी से समझ सकता है कि दोनों अर्थ एक जैसे हैं। लेकिन मशीनों के लिए दोनों वाक्य अलग-अलग हैं। इस प्रकार इसे एक ही डेटा पंक्ति में बदलना कठिन हो गया। यदि हम समान डेटा-सेट प्रदान नहीं करते हैं, तो मशीन भविष्यवाणी करने में विफल हो जाती है। इसलिए मशीन लर्निंग के लिए डेटासेट तैयार करने के लिए प्रत्येक शब्द के अर्थ को अलग करना आवश्यक है। और यहाँ स्टेमिंग का उपयोग एक ही प्रकार के डेटा को उसके मूल शब्द को प्राप्त करके वर्गीकृत करने के लिए किया जाता है।
आइये इसे कार्यान्वित करें Python प्रोग्राम.NLTK में एक एल्गोरिथ्म है जिसका नाम "पोर्टरस्टेमर" है। यह एल्गोरिथ्म टोकनयुक्त शब्द की सूची को स्वीकार करता है और इसे मूल शब्द में जोड़ता है।
स्टेमिंग को समझने के लिए कार्यक्रम
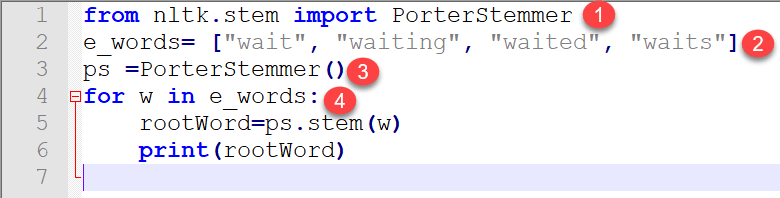
from nltk.stem import PorterStemmer
e_words= ["wait", "waiting", "waited", "waits"]
ps =PorterStemmer()
for w in e_words:
rootWord=ps.stem(w)
print(rootWord)
उत्पादन:
wait wait wait wait
Code स्पष्टीकरण:
- NLTk में एक स्टेम मॉड्यूल है जिसे आयात किया जाता है। यदि आप पूरा मॉड्यूल आयात करते हैं, तो प्रोग्राम भारी हो जाता है क्योंकि इसमें कोड की हज़ारों लाइनें होती हैं। इसलिए पूरे स्टेम मॉड्यूल से, हमने केवल "पोर्टर स्टेमर" आयात किया।
- हमने एक ही शब्द के भिन्नता डेटा की एक डमी सूची तैयार की।
- एक ऑब्जेक्ट बनाया गया है जो nltk.stem.porter.PorterStemmer वर्ग से संबंधित है।
- इसके अलावा, हमने इसे “for” लूप का उपयोग करके एक-एक करके PorterStemmer को पास किया। अंत में, हमें सूची में उल्लिखित प्रत्येक शब्द का आउटपुट मूल शब्द मिला।
उपरोक्त स्पष्टीकरण से यह भी निष्कर्ष निकाला जा सकता है कि स्टेमिंग को एक महत्वपूर्ण प्रीप्रोसेसिंग चरण माना जाता है क्योंकि यह डेटा में अतिरेक और एक ही शब्द में भिन्नता को हटा देता है। नतीजतन, डेटा फ़िल्टर किया जाता है जो बेहतर मशीन प्रशिक्षण में मदद करेगा।
अब हम एक पूर्ण वाक्य पास करते हैं और आउटपुट के रूप में उसके व्यवहार की जांच करते हैं।
कार्यक्रम:
from nltk.stem import PorterStemmer from nltk.tokenize import sent_tokenize, word_tokenize sentence="Hello Guru99, You have to build a very good site and I love visiting your site." words = word_tokenize(sentence) ps = PorterStemmer() for w in words: rootWord=ps.stem(w) print(rootWord)
आउटपुट:
hello guru99 , you have build a veri good site and I love visit your site

Code स्पष्टीकरण:
- पैकेज पोर्टरस्टेमर को मॉड्यूल स्टेम से आयात किया गया है
- वाक्य के साथ-साथ शब्दों के टोकनीकरण के लिए पैकेज आयात किए जाते हैं
- एक वाक्य लिखा जाता है जिसे अगले चरण में टोकनाइज़ किया जाना है।
- इस चरण में वर्ड टोकेनाइजेशन स्टेमिंग लेमेटाइजेशन को क्रियान्वित किया जाता है।
- पोर्टरस्टेमर के लिए एक ऑब्जेक्ट यहां बनाया गया है।
- लूप चलाया जाता है और कोड लाइन 5 में बनाए गए ऑब्जेक्ट का उपयोग करके प्रत्येक शब्द की स्टेमिंग की जाती है
निष्कर्ष:
स्टेमिंग एक डेटा-प्रीप्रोसेसिंग मॉड्यूल है। अंग्रेजी भाषा में एक ही शब्द के कई रूप होते हैं। ये रूपांतर मशीन लर्निंग प्रशिक्षण और भविष्यवाणी में अस्पष्टता पैदा करते हैं। एक सफल मॉडल बनाने के लिए, ऐसे शब्दों को फ़िल्टर करना और स्टेमिंग का उपयोग करके उसी प्रकार के अनुक्रमित डेटा में परिवर्तित करना महत्वपूर्ण है। साथ ही, यह वाक्य के एक सेट से पंक्ति डेटा प्राप्त करने और अनावश्यक डेटा को हटाने के लिए एक महत्वपूर्ण तकनीक है जिसे सामान्यीकरण भी कहा जाता है।
लेमेटाइजेशन क्या है?
lemmatization एनएलटीके में किसी शब्द के अर्थ और संदर्भ के आधार पर उसके लेम्मा को खोजने की एल्गोरिथम प्रक्रिया है। लेमेटाइजेशन आमतौर पर शब्दों के रूपात्मक विश्लेषण को संदर्भित करता है, जिसका उद्देश्य विभक्ति अंत को हटाना है। यह लेम्मा के रूप में जाने जाने वाले शब्द के आधार या शब्दकोश रूप को वापस करने में मदद करता है।
NLTK लेमेटाइजेशन विधि WorldNet के बिल्ट-इन मॉर्फ फ़ंक्शन पर आधारित है। टेक्स्ट प्रीप्रोसेसिंग में स्टेमिंग और लेमेटाइजेशन दोनों शामिल हैं। कई लोगों को ये दोनों शब्द भ्रमित करने वाले लगते हैं। कुछ लोग इन्हें एक ही मानते हैं, लेकिन स्टेमिंग और लेमेटाइजेशन में अंतर है। नीचे दिए गए कारण से लेमेटाइजेशन को पहले वाले से ज़्यादा प्राथमिकता दी जाती है।
लेमेटाइजेशन स्टेमिंग से बेहतर क्यों है?
स्टेमिंग एल्गोरिदम शब्द से प्रत्यय को काटकर काम करता है। व्यापक अर्थ में यह शब्द के आरंभ या अंत को काटता है।
इसके विपरीत, लेमेटाइजेशन एक अधिक शक्तिशाली ऑपरेशन है, और यह शब्दों के रूपात्मक विश्लेषण को ध्यान में रखता है। यह लेम्मा लौटाता है जो इसके सभी विभक्ति रूपों का आधार रूप है। शब्दकोश बनाने और शब्द के उचित रूप की तलाश करने के लिए गहन भाषाई ज्ञान की आवश्यकता होती है। स्टेमिंग एक सामान्य ऑपरेशन है जबकि लेमेटाइजेशन एक बुद्धिमान ऑपरेशन है जहां शब्दकोश में उचित रूप देखा जाएगा। इसलिए, लेमेटाइजेशन बेहतर बनाने में मदद करता है यंत्र अधिगम विशेषताएं।
Code लेम्माटाइजेशन और स्टेमिंग के बीच अंतर करना
स्टेमिंग Code:
import nltk
from nltk.stem.porter import PorterStemmer
porter_stemmer = PorterStemmer()
text = "studies studying cries cry"
tokenization = nltk.word_tokenize(text)
for w in tokenization:
print("Stemming for {} is {}".format(w,porter_stemmer.stem(w)))
आउटपुट::
Stemming for studies is studi Stemming for studying is studi Stemming for cries is cri Stemming for cry is cri
lemmatization Code:
import nltk
from nltk.stem import WordNetLemmatizer
wordnet_lemmatizer = WordNetLemmatizer()
text = "studies studying cries cry"
tokenization = nltk.word_tokenize(text)
for w in tokenization:
print("Lemma for {} is {}".format(w, wordnet_lemmatizer.lemmatize(w)))
आउटपुट:
Lemma for studies is study Lemma for studying is studying Lemma for cries is cry Lemma for cry is cry
आउटपुट की चर्चा
यदि आप स्टडीज़ और स्टडीज़ के लिए स्टेमिंग देखते हैं, तो आउटपुट एक ही है (स्टडी) लेकिन NLTK लेममैटाइज़र दोनों टोकन स्टडी फॉर स्टडीज़ और स्टडीज़ फॉर स्टडीज़ के लिए अलग-अलग लेम्मा प्रदान करता है। इसलिए जब हमें मशीन को प्रशिक्षित करने के लिए फीचर सेट बनाने की आवश्यकता होती है, तो यह बहुत अच्छा होगा यदि लेममैटाइज़ेशन को प्राथमिकता दी जाए।
लेम्माटाइजर का उपयोग मामला
लेमेटाइज़र टेक्स्ट की अस्पष्टता को कम करता है। उदाहरण के लिए साइकिल या साइकिल जैसे शब्दों को बेस शब्द साइकिल में बदल दिया जाता है। मूल रूप से, यह समान अर्थ वाले लेकिन अलग-अलग प्रतिनिधित्व वाले सभी शब्दों को उनके बेस फॉर्म में बदल देगा। यह दिए गए टेक्स्ट में शब्द घनत्व को कम करता है और मशीन को प्रशिक्षित करने के लिए सटीक सुविधाएँ तैयार करने में मदद करता है। डेटा जितना साफ होगा, आपका मशीन लर्निंग मॉडल उतना ही अधिक बुद्धिमान और सटीक होगा। NLTK लेमेटाइज़र मेमोरी के साथ-साथ कम्प्यूटेशनल लागत भी बचाएगा।
वर्डनेट लेमेटाइजेशन और पीओएस टैगिंग के उपयोग को दर्शाने वाला वास्तविक समय उदाहरण Python
from nltk.corpus import wordnet as wn from nltk.stem.wordnet import WordNetLemmatizer from nltk import word_tokenize, pos_tag from collections import defaultdict tag_map = defaultdict(lambda : wn.NOUN) tag_map['J'] = wn.ADJ tag_map['V'] = wn.VERB tag_map['R'] = wn.ADV text = "guru99 is a totally new kind of learning experience." tokens = word_tokenize(text) lemma_function = WordNetLemmatizer() for token, tag in pos_tag(tokens): lemma = lemma_function.lemmatize(token, tag_map[tag[0]]) print(token, "=>", lemma)

Code व्याख्या
- सबसे पहले, कॉर्पस रीडर वर्डनेट को आयात किया जाता है।
- WordNetLemmatizer को wordnet से आयात किया गया है।
- शब्द टोकनाइज़ के साथ-साथ पार्ट्स ऑफ़ स्पीच टैग को nltk से आयात किया जाता है।
- डिफ़ॉल्ट शब्दकोश संग्रह से आयात किया जाता है.
- शब्दकोश बनाया जाता है जहाँ pos_tag (पहला अक्षर) कुंजी मान होते हैं जिनके मान वर्डनेट शब्दकोश से मान के साथ मैप किए जाते हैं। हमने केवल पहला अक्षर लिया है क्योंकि हम इसे बाद में लूप में उपयोग करेंगे।
- पाठ लिखा जाता है और उसे टोकनकृत किया जाता है।
- ऑब्जेक्ट lemma_function बनाया गया है जिसका उपयोग लूप के अंदर किया जाएगा।
- लूप चलता है और लेम्माटाइज़ दो आर्गुमेंट लेगा, एक टोकन और दूसरा मैप।ping वर्डनेट मान के साथ pos_tag का।
उत्पादन:
guru99 => guru99 is => be totally => totally new => new kind => kind of => of learning => learn experience => experience . => .
Python लेमेटाइजेशन का निकट संबंध है वर्डनेट शब्दकोषइसलिए इस विषय का अध्ययन करना आवश्यक है, इसलिए हम इसे अगले विषय के रूप में रखते हैं।