उदाहरण के साथ वर्ड एम्बेडिंग और वर्ड2वेक मॉडल
वर्ड एम्बेडिंग क्या है?
शब्द एंबेडिंग एक शब्द प्रतिनिधित्व प्रकार है जो मशीन लर्निंग एल्गोरिदम को समान अर्थ वाले शब्दों को समझने की अनुमति देता है। यह एक भाषा मॉडलिंग और फीचर लर्निंग तकनीक है जो तंत्रिका नेटवर्क, संभाव्य मॉडल या शब्द सह-घटना मैट्रिक्स पर आयाम कमी का उपयोग करके शब्दों को वास्तविक संख्याओं के वैक्टर में मैप करती है। कुछ शब्द एम्बेडिंग मॉडल Word2vec (Google), ग्लोव (स्टैनफ़ोर्ड), और सबसे तेज़ (फ़ेसबुक) हैं।
वर्ड एम्बेडिंग को वितरित सिमेंटिक मॉडल या वितरित प्रतिनिधित्व या सिमेंटिक वेक्टर स्पेस या वेक्टर स्पेस मॉडल भी कहा जाता है। जब आप इन नामों को पढ़ते हैं, तो आप सिमेंटिक शब्द से रूबरू होते हैं जिसका अर्थ है समान शब्दों को एक साथ वर्गीकृत करना। उदाहरण के लिए सेब, आम, केला जैसे फलों को पास-पास रखना चाहिए जबकि किताबें इन शब्दों से दूर होंगी। व्यापक अर्थ में, वर्ड एम्बेडिंग फलों का वेक्टर बनाएगी जिसे किताबों के वेक्टर प्रतिनिधित्व से बहुत दूर रखा जाएगा।
वर्ड एम्बेडिंग का उपयोग कहां किया जाता है?
वर्ड एम्बेडिंग फीचर जेनरेशन, डॉक्यूमेंट क्लस्टरिंग, टेक्स्ट क्लासिफिकेशन और नेचुरल लैंग्वेज प्रोसेसिंग कार्यों में मदद करता है। आइए हम उन्हें सूचीबद्ध करें और इनमें से प्रत्येक एप्लिकेशन पर कुछ चर्चा करें।
- समान शब्दों की गणना करें: शब्द एम्बेडिंग का उपयोग भविष्यवाणी मॉडल के अधीन किए जा रहे शब्द के समान शब्दों का सुझाव देने के लिए किया जाता है। इसके साथ ही यह असमान शब्दों के साथ-साथ सबसे आम शब्दों का भी सुझाव देता है।
- संबंधित शब्दों का एक समूह बनाएं: इसका उपयोग सिमेंटिक समूहों के लिए किया जाता है।ping जो समान विशेषताओं वाली चीजों को एक साथ और असमान विशेषताओं वाली चीजों को दूर-दूर समूहित करेगा।
- पाठ वर्गीकरण हेतु सुविधा: टेक्स्ट को वेक्टर की सरणी में मैप किया जाता है जिसे प्रशिक्षण के साथ-साथ भविष्यवाणी के लिए मॉडल में फीड किया जाता है। टेक्स्ट-आधारित क्लासिफायर मॉडल को स्ट्रिंग पर प्रशिक्षित नहीं किया जा सकता है, इसलिए यह टेक्स्ट को मशीन ट्रेनेबल फॉर्म में बदल देगा। इसके अलावा, टेक्स्ट-आधारित वर्गीकरण में अर्थ निर्माण की इसकी विशेषताएं मदद करती हैं।
- दस्तावेज़ क्लस्टरिंग: एक और अनुप्रयोग है जहाँ वर्ड एम्बेडिंग Word2vec का व्यापक रूप से उपयोग किया जाता है
- प्राकृतिक भाषा प्रसंस्करण: ऐसे कई अनुप्रयोग हैं जहां वर्ड एम्बेडिंग उपयोगी है और फीचर एक्सट्रैक्शन से बेहतर साबित होती है।tracइसमें पार्ट्स ऑफ़ स्पीच टैगिंग, सेंटीमेंटल एनालिसिस और सिंटैक्टिक एनालिसिस जैसे चरण शामिल हैं। अब हमें वर्ड एम्बेडिंग का कुछ ज्ञान हो गया है। वर्ड एम्बेडिंग को लागू करने के लिए विभिन्न मॉडलों पर भी कुछ प्रकाश डाला गया है। यह संपूर्ण वर्ड एम्बेडिंग ट्यूटोरियल एक मॉडल (Word2vec) पर केंद्रित है।
वर्ड2वेक क्या है?
Word2vec बेहतर शब्द प्रतिनिधित्व के लिए शब्द एम्बेडिंग का उत्पादन करने के लिए एक तकनीक/मॉडल है। यह एक प्राकृतिक भाषा प्रसंस्करण विधि है जो बड़ी संख्या में सटीक वाक्यविन्यास और अर्थपूर्ण शब्द संबंधों को पकड़ती है। यह एक उथला दो-परत वाला तंत्रिका नेटवर्क है जो समानार्थी शब्दों का पता लगा सकता है और प्रशिक्षित होने के बाद आंशिक वाक्यों के लिए अतिरिक्त शब्द सुझा सकता है।
इस Word2vec ट्यूटोरियल में आगे बढ़ने से पहले, कृपया नीचे दिए गए वर्ड एम्बेडिंग उदाहरण आरेख में दिखाए गए अनुसार उथले और गहरे तंत्रिका नेटवर्क के बीच अंतर देखें:
उथले तंत्रिका नेटवर्क में इनपुट और आउटपुट के बीच केवल एक छिपी हुई परत होती है जबकि गहरे तंत्रिका नेटवर्क में इनपुट और आउटपुट के बीच कई छिपी हुई परतें होती हैं। इनपुट नोड्स के अधीन होता है जबकि छिपी हुई परत, साथ ही आउटपुट परत में न्यूरॉन्स होते हैं।
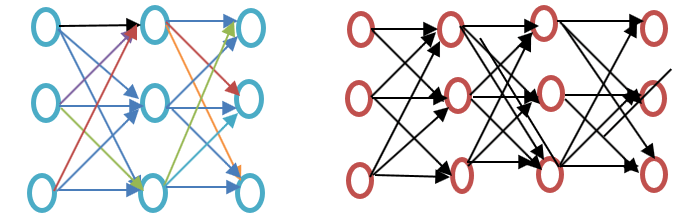
Word2vec एक दो-परत नेटवर्क है जहां एक इनपुट परत (छिपी हुई परत) और एक आउटपुट परत (आउटपुट परत) होती है।
Word2vec को Google में टॉमस मिकोलोव के नेतृत्व में शोधकर्ताओं के एक समूह द्वारा विकसित किया गया था। Word2vec लेटेंट सिमेंटिक विश्लेषण मॉडल से बेहतर और अधिक कुशल है।
Word2vec क्यों?
Word2vec शब्दों को वेक्टर स्पेस रिप्रेजेंटेशन में दर्शाता है। शब्दों को वेक्टर के रूप में दर्शाया जाता है और प्लेसमेंट इस तरह से किया जाता है कि समान अर्थ वाले शब्द एक साथ दिखाई देते हैं और असमान शब्द दूर स्थित होते हैं। इसे सिमेंटिक रिलेशनशिप भी कहा जाता है। न्यूरल नेटवर्क टेक्स्ट को नहीं समझते हैं, बल्कि वे केवल संख्याओं को समझते हैं। वर्ड एम्बेडिंग टेक्स्ट को संख्यात्मक वेक्टर में बदलने का एक तरीका प्रदान करता है।
Word2vec शब्दों के भाषाई संदर्भ का पुनर्निर्माण करता है। आगे बढ़ने से पहले आइए समझते हैं कि भाषाई संदर्भ क्या है? सामान्य जीवन परिदृश्य में जब हम संवाद करने के लिए बोलते या लिखते हैं, तो दूसरे लोग यह पता लगाने की कोशिश करते हैं कि वाक्य का उद्देश्य क्या है। उदाहरण के लिए, “भारत का तापमान कितना है”, यहाँ संदर्भ वह है जो उपयोगकर्ता “भारत का तापमान” जानना चाहता है जो संदर्भ है। संक्षेप में, वाक्य का मुख्य उद्देश्य संदर्भ है। बोली जाने वाली या लिखित भाषा (प्रकटीकरण) के इर्द-गिर्द शब्द या वाक्य संदर्भ का अर्थ निर्धारित करने में मदद करता है। Word2vec संदर्भों के माध्यम से शब्दों के वेक्टर प्रतिनिधित्व को सीखता है।
Word2vec क्या करता है?
शब्द एम्बेडिंग से पहले
यह जानना महत्वपूर्ण है कि वर्ड एम्बेडिंग से पहले किस दृष्टिकोण का उपयोग किया जाता है और इसके क्या नुकसान हैं और फिर हम इस विषय पर आगे बढ़ेंगे कि वर्ड2वेक दृष्टिकोण का उपयोग करके वर्ड एम्बेडिंग द्वारा कैसे नुकसानों को दूर किया जाता है। अंत में, हम आगे बढ़ेंगे कि वर्ड2वेक कैसे काम करता है क्योंकि यह समझना महत्वपूर्ण है कि यह कैसे काम करता है।
अव्यक्त अर्थ विश्लेषण के लिए दृष्टिकोण
यह वह दृष्टिकोण है जिसका उपयोग शब्द एम्बेडिंग से पहले किया गया था। इसमें शब्दों के बैग की अवधारणा का उपयोग किया गया था जहाँ शब्दों को एनकोडेड वेक्टर के रूप में दर्शाया जाता है। यह एक विरल वेक्टर प्रतिनिधित्व है जहाँ आयाम शब्दावली के आकार के बराबर होता है। यदि शब्द शब्दकोश में आता है, तो उसे गिना जाता है, अन्यथा नहीं। अधिक समझने के लिए, कृपया नीचे दिए गए प्रोग्राम को देखें।
Word2vec उदाहरण

from sklearn.feature_extraction.text import CountVectorizer vectorizer = CountVectorizer() data_corpus = ["guru99 is the best site for online tutorials. I love to visit guru99."] vocabulary = vectorizer.fit(data_corpus) X = vectorizer.transform(data_corpus) print(X.toarray()) print(vectorizer.get_feature_names_out())
आउटपुट:
[[1 2 1 1 1 1 1 1 1 1]]
[u'best', u'guru99', u'is', u'love', u'online', u'sitefor', u'the', u'to', u'tutorials', u'visit']
Code व्याख्या
- CountVectorizer वह मॉड्यूल है जिसका उपयोग शब्दों को फिट करने के आधार पर शब्दावली को संग्रहीत करने के लिए किया जाता है। इसे sklearn से आयात किया जाता है।
- CountVectorizer वर्ग का उपयोग करके ऑब्जेक्ट बनाएं।
- सूची में वह डेटा लिखें जिसे CountVectorizer में फिट किया जाना है।
- डेटा को CountVectorizer वर्ग से निर्मित ऑब्जेक्ट में फिट किया जाता है।
- शब्दावली का उपयोग करके डेटा में शब्दों की गणना करने के लिए शब्द का बैग दृष्टिकोण लागू करें। यदि शब्दावली में शब्द या टोकन उपलब्ध नहीं है, तो ऐसी इंडेक्स स्थिति शून्य पर सेट की जाती है।
- लाइन 5 में मौजूद वेरिएबल जो x है, उसे ऐरे में बदल दिया जाता है (x के लिए उपलब्ध विधि)। यह लाइन 3 में दिए गए वाक्य या सूची में प्रत्येक टोकन की गिनती प्रदान करेगा।
- यह उन विशेषताओं को दिखाएगा जो शब्दावली का हिस्सा हैं जब इसे लाइन 4 में डेटा का उपयोग करके फिट किया जाता है।
लेटेंट सिमेंटिक दृष्टिकोण में, पंक्ति अद्वितीय शब्दों का प्रतिनिधित्व करती है जबकि कॉलम उस शब्द के दस्तावेज़ में दिखाई देने की संख्या को दर्शाता है। यह दस्तावेज़ मैट्रिक्स के रूप में शब्दों का प्रतिनिधित्व है। टर्म-फ़्रीक्वेंसी व्युत्क्रम दस्तावेज़ आवृत्ति (TFIDF) का उपयोग दस्तावेज़ में शब्दों की आवृत्ति की गणना करने के लिए किया जाता है जो दस्तावेज़ में शब्द की आवृत्ति / संपूर्ण कॉर्पस में शब्द की आवृत्ति है।
बैग ऑफ वर्ड्स विधि की खामियां
- यह शब्द के क्रम को नजरअंदाज करता है, उदाहरण के लिए, यह बुरा है = यह बुरा है।
- यह शब्दों के संदर्भ को अनदेखा करता है। मान लीजिए अगर मैं वाक्य लिखता हूँ “उसे किताबें बहुत पसंद थीं। शिक्षा किताबों में सबसे अच्छी मिलती है”। यह दो वेक्टर बनाएगा, एक “उसे किताबें बहुत पसंद थीं” और दूसरा “शिक्षा किताबों में सबसे अच्छी मिलती है”। यह उन दोनों को ऑर्थोगोनल मानेगा जो उन्हें स्वतंत्र बनाता है, लेकिन वास्तव में, वे एक दूसरे से संबंधित हैं।
इन सीमाओं को दूर करने के लिए शब्द एम्बेडिंग विकसित की गई और Word2vec इसे कार्यान्वित करने का एक तरीका है।
वर्ड2वेक कैसे काम करता है?
Word2vec शब्द को उसके आस-पास के संदर्भ का अनुमान लगाकर सीखता है। उदाहरण के लिए, आइए हम शब्द "ही" लें प्यार करता है फ़ुटबॉल।"
हम शब्द: loves के लिए Word2vec की गणना करना चाहते हैं।
मान लीजिए
loves = Vin. P(Vout / Vin) is calculated where, Vin is the input word. P is the probability of likelihood. Vout is the output word.
शब्द प्यार करता है कॉर्पस में प्रत्येक शब्द पर चलता है। शब्दों के बीच वाक्यविन्यास और अर्थ संबंधी संबंध को एनकोड किया जाता है। इससे समान और सादृश्य वाले शब्द खोजने में मदद मिलती है।
शब्द की सभी यादृच्छिक विशेषताएँ प्यार करता है गणना की जाती है। इन सुविधाओं को पड़ोसी या संदर्भ शब्दों के संबंध में बदला या अपडेट किया जाता है बैक प्रोपेगेशन विधि.
सीखने का एक अन्य तरीका यह है कि यदि दो शब्दों का संदर्भ समान है या दो शब्दों में समान विशेषताएं हैं, तो ऐसे शब्द संबंधित होते हैं।
Word2vec Archiटेक्चर
Word2vec द्वारा दो आर्किटेक्चर का उपयोग किया जाता है:
- शब्दों का सतत थैला (सीबीओडब्ल्यू)
- ग्राम छोड़ें
इस Word2vec ट्यूटोरियल में आगे बढ़ने से पहले, आइए चर्चा करें कि ये आर्किटेक्चर या मॉडल शब्द प्रतिनिधित्व के दृष्टिकोण से क्यों महत्वपूर्ण हैं। शब्द प्रतिनिधित्व सीखना अनिवार्य रूप से अप्रशिक्षित है, लेकिन मॉडल को प्रशिक्षित करने के लिए लक्ष्य/लेबल की आवश्यकता होती है। स्किप-ग्राम और CBOW मॉडल प्रशिक्षण के लिए अप्रशिक्षित प्रतिनिधित्व को पर्यवेक्षित रूप में परिवर्तित करते हैं।
CBOW में, मौजूदा शब्द का पूर्वानुमान आस-पास के संदर्भ विंडो की विंडो का उपयोग करके लगाया जाता है। उदाहरण के लिए, यदि wमैं 1,wमैं 2,wमैं 1 +,wमैं 2 +यदि किसी को शब्द या संदर्भ दिए गए हों, तो यह मॉडल उन्हें समझने में मदद करेगा।i
स्किप-ग्राम CBOW के विपरीत कार्य करता है जिसका अर्थ है कि यह शब्द से दिए गए अनुक्रम या संदर्भ की भविष्यवाणी करता है। इसे समझने के लिए आप उदाहरण को उलट सकते हैं। यदि wi दिया गया है, यह संदर्भ या w की भविष्यवाणी करेगामैं 1,wमैं 2,wमैं 1 +,wi+2.
Word2vec CBOW (निरंतर शब्दों का बैग) और स्किम-ग्राम के बीच चयन करने का विकल्प प्रदान करता है। मॉडल के प्रशिक्षण के दौरान ऐसे पैरामीटर प्रदान किए जाते हैं। किसी के पास नेगेटिव सैंपलिंग या पदानुक्रमित सॉफ्टमैक्स परत का उपयोग करने का विकल्प हो सकता है।
शब्दों का सतत थैला
आइए हम वर्ड आर्किटेक्चर के सतत बैग को समझने के लिए एक सरल Word2vec उदाहरण आरेख बनाएं।

आइए गणितीय रूप से समीकरणों की गणना करें। मान लीजिए V शब्दावली आकार है और N छिपी परत आकार है। इनपुट को {xमैं 1, एक्सआई-2, xi+1, xमैं 2 +}. हम V * N को गुणा करके वेट मैट्रिक्स प्राप्त करते हैं। इनपुट वेक्टर को वेट मैट्रिक्स से गुणा करके एक और मैट्रिक्स प्राप्त किया जाता है। इसे निम्न समीकरण द्वारा भी समझा जा सकता है।
एच=एक्सआईtW
जहाँ xit? W क्रमशः इनपुट वेक्टर और वेट मैट्रिक्स हैं,
संदर्भ और अगले शब्द के बीच मिलान की गणना करने के लिए, कृपया नीचे दिए गए समीकरण को देखें
u=पूर्वानुमानित प्रतिनिधित्व*h
जहाँ उपरोक्त समीकरण में अनुमानित प्रतिनिधित्व मॉडल?h से प्राप्त किया जाता है।
स्किप-ग्राम मॉडल
स्किप-ग्राम दृष्टिकोण का उपयोग किसी इनपुट शब्द के आधार पर वाक्य की भविष्यवाणी करने के लिए किया जाता है। इसे बेहतर ढंग से समझने के लिए आइए नीचे दिए गए Word2vec उदाहरण में दिखाए अनुसार आरेख बनाएं।

इसे निरंतर बैग ऑफ वर्ड मॉडल के विपरीत माना जा सकता है जहां इनपुट शब्द है और मॉडल संदर्भ या अनुक्रम प्रदान करता है। हम यह भी निष्कर्ष निकाल सकते हैं कि लक्ष्य को इनपुट में फीड किया जाता है और आउटपुट लेयर को संदर्भ शब्दों की चुनी गई संख्या को समायोजित करने के लिए कई बार दोहराया जाता है। बैकप्रोपेगेशन विधि के माध्यम से भार को समायोजित करने के लिए सभी आउटपुट लेयर से त्रुटि वेक्टर को जोड़ा जाता है।
कौन सा मॉडल चुनना है?
सीबीओडब्ल्यू स्किप ग्राम से कई गुना तेज है और लगातार आने वाले शब्दों के लिए बेहतर आवृत्ति प्रदान करता है, जबकि स्किप ग्राम को कम मात्रा में प्रशिक्षण डेटा की आवश्यकता होती है और यह दुर्लभ शब्दों या वाक्यांशों का भी प्रतिनिधित्व करता है।
Word2vec और NLTK के बीच संबंध
एनएलटीके यह प्राकृतिक भाषा टूलकिट है। इसका उपयोग टेक्स्ट के प्रीप्रोसेसिंग के लिए किया जाता है। कोई व्यक्ति स्पीच टैगिंग, लेमेटाइज़िंग, स्टेमिंग, स्टॉप वर्ड्स रिमूवल, दुर्लभ शब्दों या कम इस्तेमाल किए गए शब्दों को हटाने जैसे विभिन्न ऑपरेशन कर सकता है। यह टेक्स्ट को साफ करने के साथ-साथ प्रभावी शब्दों से फीचर तैयार करने में भी मदद करता है। दूसरी तरफ, Word2vec का उपयोग सिमेंटिक (एक साथ निकट से संबंधित आइटम) और वाक्यविन्यास (अनुक्रम) मिलान के लिए किया जाता है। Word2vec का उपयोग करके, कोई समान शब्द, असमान शब्द, आयामी कमी और कई अन्य चीजें पा सकता है। Word2vec की एक और महत्वपूर्ण विशेषता टेक्स्ट के उच्च आयामी प्रतिनिधित्व को वेक्टर के निचले आयामी में बदलना है।
NLTK और Word2vec का उपयोग कहां करें?
यदि किसी को ऊपर बताए गए कुछ सामान्य प्रयोजन के कार्यों को पूरा करना है जैसे कि टोकेनाइजेशन, पीओएस टैगिंग और पार्सिंग, तो उसे एनएलटीके का उपयोग करना चाहिए, जबकि कुछ संदर्भ, विषय मॉडलिंग या दस्तावेज़ समानता के अनुसार शब्दों की भविष्यवाणी करने के लिए उसे वर्ड2वेक का उपयोग करना चाहिए।
कोड की सहायता से NLTK और Word2vec का संबंध
NLTK और Word2vec का उपयोग समान शब्दों के प्रतिनिधित्व या वाक्यविन्यास मिलान को खोजने के लिए एक साथ किया जा सकता है। NLTK टूलकिट का उपयोग NLTK के साथ आने वाले कई पैकेजों को लोड करने के लिए किया जा सकता है और Word2vec का उपयोग करके मॉडल बनाया जा सकता है। फिर इसे वास्तविक समय के शब्दों पर परखा जा सकता है। आइए निम्नलिखित कोड में दोनों का संयोजन देखें। आगे की प्रक्रिया से पहले, कृपया NLTK द्वारा प्रदान किए जाने वाले कॉर्पोरा पर एक नज़र डालें। आप कमांड का उपयोग करके डाउनलोड कर सकते हैं
nltk(nltk.download('all'))

कृपया कोड के लिए स्क्रीनशॉट देखें।
import nltk
import gensim
from nltk.corpus import abc
model= gensim.models.Word2Vec(abc.sents())
X= list(model.wv.vocab)
data=model.most_similar('science')
print(data)

आउटपुट:
[('law', 0.9415997266769409), ('practice', 0.9276568293571472), ('discussion', 0.9259148836135864), ('agriculture', 0.9257254004478455), ('media', 0.9232194423675537), ('policy', 0.922248125076294), ('general', 0.9166069030761719), ('undertaking', 0.916458249092102), ('tight', 0.9129181504249573), ('board', 0.9107444286346436)]
का स्पष्टीकरण Code
- nltk लाइब्रेरी आयात की गई है, जहां से आप abc कॉर्पस डाउनलोड कर सकते हैं जिसका उपयोग हम अगले चरण में करेंगे।
- Gensim आयातित है। यदि Gensim Word2vec स्थापित नहीं है, तो कृपया इसे "pip3 install gensim" कमांड का उपयोग करके स्थापित करें। कृपया नीचे स्क्रीनशॉट देखें।

- कॉर्पस abc को आयात करें जिसे nltk.download('abc') का उपयोग करके डाउनलोड किया गया है।
- फ़ाइलों को मॉडल Word2vec में पास करें जिसे वाक्यों के रूप में Gensim का उपयोग करके आयात किया जाता है।
- शब्दावली को चर के रूप में संग्रहीत किया जाता है।
- मॉडल का परीक्षण नमूना शब्द विज्ञान पर किया गया है क्योंकि ये फ़ाइलें विज्ञान से संबंधित हैं।
- यहाँ मॉडल द्वारा “विज्ञान” शब्द के समानार्थी शब्द की भविष्यवाणी की गई है।
एक्टिवेटर्स और वर्ड2वेक
न्यूरॉन का सक्रियण कार्य इनपुट के एक सेट के आधार पर उस न्यूरॉन के आउटपुट को परिभाषित करता है। जैविक रूप से हमारे मस्तिष्क में एक गतिविधि से प्रेरित है जहाँ विभिन्न न्यूरॉन्स को विभिन्न उत्तेजनाओं का उपयोग करके सक्रिय किया जाता है। आइए निम्नलिखित आरेख के माध्यम से सक्रियण कार्य को समझें।

यहाँ x1,x2,..x4 तंत्रिका नेटवर्क का नोड है।
w1, w2, w3 नोड का भार है,
? सभी भार और नोड मान का योग है जो सक्रियण फ़ंक्शन के रूप में काम करता है।
सक्रियण फ़ंक्शन क्यों?
यदि किसी सक्रियण फ़ंक्शन का उपयोग नहीं किया जाता है, तो आउटपुट रैखिक होगा, लेकिन रैखिक फ़ंक्शन की कार्यक्षमता सीमित है। ऑब्जेक्ट डिटेक्शन, इमेज क्लासिफिकेशन, आदि जैसी जटिल कार्यक्षमताओं को प्राप्त करने के लिए, रैखिक फ़ंक्शन की कार्यक्षमता सीमित होती है।ping आवाज और कई अन्य गैर-रेखीय आउटपुट का उपयोग करके टेक्स्ट की आवश्यकता होती है, जिसे एक्टिवेशन फ़ंक्शन का उपयोग करके प्राप्त किया जाता है।
वर्ड एम्बेडिंग में सक्रियण परत की गणना कैसे की जाती है (Word2vec)
सॉफ्टमैक्स लेयर (सामान्यीकृत घातांकीय फ़ंक्शन) आउटपुट लेयर फ़ंक्शन है जो प्रत्येक नोड को सक्रिय या सक्रिय करता है। उपयोग किया जाने वाला एक अन्य तरीका पदानुक्रमित सॉफ्टमैक्स है जहाँ जटिलता की गणना O(log2V) जिसमें सॉफ्टमैक्स O(V) है, जहाँ V शब्दावली का आकार है। इनके बीच का अंतर पदानुक्रमित सॉफ्टमैक्स परत में जटिलता में कमी है। इसकी (पदानुक्रमित सॉफ्टमैक्स) कार्यक्षमता को समझने के लिए, कृपया नीचे दिए गए वर्ड एम्बेडिंग उदाहरण को देखें:

मान लीजिए हम शब्द के अवलोकन की प्रायिकता की गणना करना चाहते हैं मोहब्बत एक निश्चित संदर्भ दिया गया है। रूट से लीफ नोड तक का प्रवाह नोड 2 और फिर नोड 5 की ओर पहला कदम होगा। इसलिए यदि हमारे पास 8 का शब्दावली आकार है, तो केवल तीन गणनाओं की आवश्यकता है। इसलिए यह विघटन की अनुमति देता है, एक शब्द की संभावना की गणना (मोहब्बत).
हाइरार्किकल सॉफ्टमैक्स के अलावा अन्य कौन से विकल्प उपलब्ध हैं?
यदि सामान्य अर्थ में बात करें तो शब्द एम्बेडिंग के लिए उपलब्ध विकल्प हैं विभेदित सॉफ्टमैक्स, सीएनएन-सॉफ्टमैक्स, महत्व नमूनाकरण, अनुकूली महत्व नमूनाकरण, शोर विरोधाभासी अनुमान, नकारात्मक नमूनाकरण, स्व-सामान्यीकरण, और अनियमित सामान्यीकरण।
वर्ड2वेक के बारे में विशेष रूप से बात करें तो हमारे पास नकारात्मक नमूनाकरण उपलब्ध है।
नेगेटिव सैंपलिंग प्रशिक्षण डेटा का नमूना लेने का एक तरीका है। यह कुछ हद तक स्टोकेस्टिक ग्रेडिएंट डिसेंट जैसा है, लेकिन कुछ अंतर के साथ। नेगेटिव सैंपलिंग केवल नेगेटिव प्रशिक्षण उदाहरणों को देखता है। यह शोर विपरीत अनुमान पर आधारित है और संदर्भ में नहीं, बल्कि यादृच्छिक रूप से शब्दों का नमूना लेता है। यह एक तेज़ प्रशिक्षण पद्धति है और संदर्भ को यादृच्छिक रूप से चुनती है। यदि पूर्वानुमानित शब्द यादृच्छिक रूप से चुने गए संदर्भ में दिखाई देता है तो दोनों वेक्टर एक दूसरे के करीब होते हैं।
क्या निष्कर्ष निकाला जा सकता है?
एक्टिवेटर न्यूरॉन्स को उसी तरह फायर कर रहे हैं जैसे हमारे न्यूरॉन्स बाहरी उत्तेजनाओं का उपयोग करके फायर किए जाते हैं। सॉफ्टमैक्स लेयर आउटपुट लेयर फ़ंक्शन में से एक है जो वर्ड एम्बेडिंग के मामले में न्यूरॉन्स को फायर करता है। Word2vec में हमारे पास हाइरार्किकल सॉफ्टमैक्स और नेगेटिव सैंपलिंग जैसे विकल्प हैं। एक्टिवेटर का उपयोग करके, कोई रैखिक फ़ंक्शन को नॉनलाइनियर फ़ंक्शन में बदल सकता है, और इस तरह के उपयोग से एक जटिल मशीन लर्निंग एल्गोरिदम को लागू किया जा सकता है।
जेनसिम क्या है?
जेनसिम एक ओपन-सोर्स विषय मॉडलिंग और प्राकृतिक भाषा प्रसंस्करण टूलकिट है जिसे कार्यान्वित किया गया है Python और साइथॉन। जेनसिम टूलकिट उपयोगकर्ताओं को टेक्स्ट बॉडी में छिपी संरचना की खोज करने के लिए टॉपिक मॉडलिंग के लिए Word2vec आयात करने की अनुमति देता है। जेनसिम न केवल Word2vec का कार्यान्वयन प्रदान करता है, बल्कि Doc2vec और FastText के लिए भी कार्यान्वयन प्रदान करता है।
यह ट्यूटोरियल पूरी तरह से Word2vec के बारे में है इसलिए हम वर्तमान विषय पर ही बने रहेंगे।
Gensim का उपयोग करके Word2vec को कैसे कार्यान्वित करें
अब तक हमने चर्चा की है कि Word2vec क्या है, इसकी विभिन्न आर्किटेक्चर क्या हैं, शब्दों के एक बैग से Word2vec में बदलाव क्यों हुआ है, लाइव कोड और सक्रियण कार्यों के साथ Word2vec और NLTK के बीच संबंध।
नीचे Gensim का उपयोग करके Word2vec को कार्यान्वित करने की चरण-दर-चरण विधि दी गई है:
चरण 1) डेटा संग्रहण
किसी भी मशीन लर्निंग मॉडल को लागू करने या प्राकृतिक भाषा प्रसंस्करण को लागू करने का पहला कदम डेटा संग्रह है
कृपया नीचे दिए गए Gensim Word2vec उदाहरण में दिखाए अनुसार एक बुद्धिमान चैटबॉट बनाने के लिए डेटा का अवलोकन करें।
[{"tag": "welcome",
"patterns": ["Hi", "How are you", "Is any one to talk?", "Hello", "hi are you available"],
"responses": ["Hello, thanks for contacting us", "Good to see you here"," Hi there, how may I assist you?"]
},
{"tag": "goodbye",
"patterns": ["Bye", "See you later", "Goodbye", "I will come back soon"],
"responses": ["See you later, thanks for visiting", "have a great day ahead", "Wish you Come back again soon."]
},
{"tag": "thankful",
"patterns": ["Thanks for helping me", "Thank your guidance", "That's helpful and kind from you"],
"responses": ["Happy to help!", "Any time!", "My pleasure", "It is my duty to help you"]
},
{"tag": "hoursopening",
"patterns": ["What hours are you open?", "Tell your opening time?", "When are you open?", "Just your timing please"],
"responses": ["We're open every day 8am-7pm", "Our office hours are 8am-7pm every day", "We open office at 8 am and close at 7 pm"]
},
{"tag": "payments",
"patterns": ["Can I pay using credit card?", " Can I pay using Mastercard?", " Can I pay using cash only?" ],
"responses": ["We accept VISA, Mastercard and credit card", "We accept credit card, debit cards and cash. Please don’t worry"]
}
]
आंकड़ों से हमें जो समझ आया वह यह है
- इस डेटा में तीन चीज़ें शामिल हैं - टैग, पैटर्न और प्रतिक्रियाएँ। टैग का मतलब है इरादा (चर्चा का विषय क्या है)।
- डेटा JSON प्रारूप में है.
- पैटर्न एक प्रश्न है जो उपयोगकर्ता बॉट से पूछेंगे
- प्रतिक्रिया वह उत्तर है जो चैटबॉट संबंधित प्रश्न/पैटर्न के लिए प्रदान करेगा।
चरण 2) डेटा प्रीप्रोसेसिंग
कच्चे डेटा को प्रोसेस करना बहुत ज़रूरी है। अगर साफ़ किया गया डेटा मशीन में डाला जाए, तो मॉडल ज़्यादा सटीक तरीके से प्रतिक्रिया देगा और डेटा को ज़्यादा कुशलता से सीखेगा।
इस चरण में स्टॉप वर्ड, स्टेमिंग, अनावश्यक शब्द आदि को हटाना शामिल है। आगे बढ़ने से पहले, डेटा लोड करना और उसे डेटा फ़्रेम में बदलना महत्वपूर्ण है। कृपया ऐसे कोड के लिए नीचे देखें
import json
json_file =’intents.json'
with open('intents.json','r') as f:
data = json.load(f)
का स्पष्टीकरण Code:
- चूंकि डेटा json प्रारूप में है इसलिए json आयात किया जाता है
- फ़ाइल वेरिएबल में संग्रहीत है
- फ़ाइल खुली है और डेटा वेरिएबल में लोड की गई है
अब डेटा आयात हो चुका है और अब डेटा को डेटा फ़्रेम में बदलने का समय है। अगला चरण देखने के लिए कृपया नीचे दिया गया कोड देखें
import pandas as pd
df = pd.DataFrame(data)
df['patterns'] = df['patterns'].apply(', '.join)
का स्पष्टीकरण Code:
1. डेटा को पांडा का उपयोग करके डेटा फ्रेम में परिवर्तित किया जाता है जिसे ऊपर आयात किया गया था।
2. यह कॉलम पैटर्न में सूची को स्ट्रिंग में परिवर्तित कर देगा।
from nltk.corpus import stopwords
from textblob import Word
stop = stopwords.words('english')
df['patterns'] = df['patterns'].apply(lambda x:' '.join(x.lower() for x in x.split()))
df['patterns't']= df['patterns''].apply(lambda x: ' '.join(x for x in x.split() if x not in string.punctuation)
df['patterns']= df['patterns'].str.replace('[^\w\s]','')
df['patterns']= df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if not x.isdigit()))
df['patterns'] = df['patterns'].apply(lambda x:' '.join(x for x in x.split() if not x in stop))
df['patterns'] = df['patterns'].apply(lambda x: " ".join([Word(word).lemmatize() for word in x.split()]))
Code स्पष्टीकरण:
1. अंग्रेजी स्टॉप शब्दों को nltk टूलकिट से स्टॉप वर्ड मॉड्यूल का उपयोग करके आयात किया जाता है
2. पाठ के सभी शब्दों को फॉर कंडीशन और लैम्ब्डा फ़ंक्शन का उपयोग करके लोअर केस में परिवर्तित किया जाता है। लैम्ब्डा फ़ंक्शन एक अनाम फ़ंक्शन है.
3. डेटा फ़्रेम में पाठ की सभी पंक्तियों की स्ट्रिंग विराम चिह्नों के लिए जाँच की जाती है, और इन्हें फ़िल्टर किया जाता है।
4. संख्या या बिंदु जैसे वर्णों को नियमित अभिव्यक्ति का उपयोग करके हटाया जाता है।
5. Digits को पाठ से हटा दिया गया है.
6. इस स्तर पर विराम शब्द हटा दिए जाते हैं।
7. अब शब्दों को फ़िल्टर किया जाता है, और लेमेटाइज़ेशन का उपयोग करके एक ही शब्द के विभिन्न रूपों को हटा दिया जाता है। इनके साथ, हमने डेटा प्रीप्रोसेसिंग पूरी कर ली है।
आउटपुट:
, patterns, responses, tag 0,hi one talk hello hi available,"['Hello, thanks for contacting us', 'Good to see you here', ' Hi there, how may I assist you?']",welcome 1,bye see later goodbye come back soon,"['See you later, thanks for visiting', 'have a great day ahead', 'Wish you Come back again soon.']",goodbye 2,thanks helping thank guidance thats helpful kind,"['Happy to help!', 'Any time!', 'My pleasure', 'It is my duty to help you']",thankful 3,hour open tell opening time open timing please,"[""We're open every day 8am-7pm"", 'Our office hours are 8am-7pm every day', 'We open office at 8 am and close at 7 pm']",hoursopening 4,pay using credit card pay using mastercard pay using cash,"['We accept VISA, Mastercard and credit card', 'We accept credit card, debit cards and cash. Please don’t worry']",payments
चरण 3) Word2vec का उपयोग करके न्यूरल नेटवर्क का निर्माण
अब Gensim Word2vec मॉड्यूल का उपयोग करके मॉडल बनाने का समय आ गया है। हमें Gensim से Word2vec आयात करना होगा। आइए हम ऐसा करते हैं, और फिर हम निर्माण करेंगे और अंतिम चरण में हम वास्तविक समय डेटा पर मॉडल की जाँच करेंगे।
from gensim.models import Word2Vec
अब इस Gensim Word2vec ट्यूटोरियल में, हम Word2Vec का उपयोग करके सफलतापूर्वक मॉडल बना सकते हैं। Word2Vec का उपयोग करके मॉडल बनाने का तरीका जानने के लिए कृपया कोड की अगली पंक्ति देखें। मॉडल को टेक्स्ट सूची के रूप में प्रदान किया जाता है, इसलिए हम नीचे दिए गए कोड का उपयोग करके डेटा फ़्रेम से टेक्स्ट को सूची में बदल देंगे
Bigger_list=[]
for i in df['patterns']
li = list(i.split(""))
Bigger_list.append(li)
Model= Word2Vec(Bigger_list,min_count=1,size=300,workers=4)
का स्पष्टीकरण Code:
1. bigger_list बनाया गया जहाँ आंतरिक सूची संलग्न है। यह वह प्रारूप है जिसे मॉडल Word2Vec में फीड किया जाता है।
2. लूप को क्रियान्वित किया जाता है, तथा डेटा फ्रेम के पैटर्न कॉलम की प्रत्येक प्रविष्टि को दोहराया जाता है।
3. कॉलम पैटर्न के प्रत्येक तत्व को विभाजित किया जाता है और आंतरिक सूची li में संग्रहीत किया जाता है
4. आंतरिक सूची को बाहरी सूची के साथ जोड़ दिया जाता है।
5. यह सूची Word2Vec मॉडल को प्रदान की गई है। आइए यहाँ दिए गए कुछ मापदंडों को समझें
न्यूनतम_गणना: यह इससे कम कुल आवृत्ति वाले सभी शब्दों को नजरअंदाज कर देगा।
आकार: यह शब्द सदिशों की विमाशीलता बताता है।
कर्मी: ये मॉडल को प्रशिक्षित करने के लिए सूत्र हैं
अन्य विकल्प भी उपलब्ध हैं, और कुछ महत्वपूर्ण विकल्प नीचे बताए गए हैं
खिड़की: एक वाक्य में वर्तमान और अनुमानित शब्द के बीच अधिकतम दूरी।
एसजी: यह एक प्रशिक्षण एल्गोरिथ्म है और स्किप-ग्राम के लिए 1 और शब्दों के निरंतर बैग के लिए 0 है। हमने ऊपर विस्तार से इन पर चर्चा की है।
एचएस: यदि यह 1 है तो हम प्रशिक्षण के लिए पदानुक्रमित सॉफ्टमैक्स का उपयोग कर रहे हैं और यदि यह 0 है तो नकारात्मक नमूनाकरण का उपयोग किया जाता है।
अल्फा: प्रारंभिक सीखने की दर
आइये नीचे अंतिम कोड प्रदर्शित करें:
#list of libraries used by the code
import string
from gensim.models import Word2Vec
import logging
from nltk.corpus import stopwords
from textblob import Word
import json
import pandas as pd
#data in json format
json_file = 'intents.json'
with open('intents.json','r') as f:
data = json.load(f)
#displaying the list of stopwords
stop = stopwords.words('english')
#dataframe
df = pd.DataFrame(data)
df['patterns'] = df['patterns'].apply(', '.join)
# print(df['patterns'])
#print(df['patterns'])
#cleaning the data using the NLP approach
print(df)
df['patterns'] = df['patterns'].apply(lambda x:' '.join(x.lower() for x in x.split()))
df['patterns']= df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in string.punctuation))
df['patterns']= df['patterns'].str.replace('[^\w\s]','')
df['patterns']= df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if not x.isdigit()))
df['patterns'] = df['patterns'].apply(lambda x:' '.join(x for x in x.split() if not x in stop))
df['patterns'] = df['patterns'].apply(lambda x: " ".join([Word(word).lemmatize() for word in x.split()]))
#taking the outer list
bigger_list=[]
for i in df['patterns']:
li = list(i.split(" "))
bigger_list.append(li)
#structure of data to be taken by the model.word2vec
print("Data format for the overall list:",bigger_list)
#custom data is fed to machine for further processing
model = Word2Vec(bigger_list, min_count=1,size=300,workers=4)
#print(model)
चरण 4) मॉडल सेव करना
मॉडल को बिन और मॉडल फॉर्म के रूप में सहेजा जा सकता है। बिन बाइनरी फॉर्मेट है। मॉडल को सहेजने के लिए कृपया नीचे दी गई पंक्तियों को देखें
model.save("word2vec.model")
model.save("model.bin")
उपरोक्त कोड की व्याख्या
1. मॉडल को .model फ़ाइल के रूप में सहेजा जाता है।
2. मॉडल .bin फ़ाइल के रूप में सहेजा गया है
हम इस मॉडल का उपयोग वास्तविक समय परीक्षण करने के लिए करेंगे जैसे समान शब्द, असमान शब्द और सबसे सामान्य शब्द।
चरण 5) मॉडल लोड करना और वास्तविक समय परीक्षण करना
मॉडल नीचे दिए गए कोड का उपयोग करके लोड किया गया है:
model = Word2Vec.load('model.bin')
यदि आप शब्दावली को प्रिंट करना चाहते हैं तो यह नीचे दिए गए कमांड का उपयोग करके किया जाता है:
vocab = list(model.wv.vocab)
कृपया परिणाम देखें:
['see', 'thank', 'back', 'thanks', 'soon', 'open', 'mastercard', 'card', 'time', 'pay', 'talk', 'cash', 'one', 'please', 'goodbye', 'thats', 'helpful', 'hour', 'credit', 'hi', 'later', 'guidance', 'opening', 'timing', 'hello', 'helping', 'bye', 'tell', 'come', 'using', 'kind', 'available']
चरण 6) सर्वाधिक समान शब्दों की जाँच
आइये इन बातों को व्यावहारिक रूप से लागू करें:
similar_words = model.most_similar('thanks')
print(similar_words)
कृपया परिणाम देखें:
[('kind', 0.16104359924793243), ('using', 0.1352398842573166), ('come', 0.11500970274209976), ('later', 0.09989878535270691), ('helping', 0.04855936020612717), ('credit', 0.04659383371472359), ('pay', 0.0329081267118454), ('thank', 0.02484947443008423), ('hour', 0.0202352125197649), ('opening', 0.018177658319473267)]
चरण 7) दिए गए शब्दों से शब्द मेल नहीं खाता
dissimlar_words = model.doesnt_match('See you later, thanks for visiting'.split())
print(dissimlar_words)
हमने शब्द उपलब्ध कराये हैं 'बाद में मिलते हैं, आने के लिए धन्यवाद'। यह होगा इन शब्दों से सबसे भिन्न शब्दों को प्रिंट करें। आइए इस कोड को चलाएँ और परिणाम पाएँ
उपरोक्त कोड के निष्पादन के बाद परिणाम:
Thanks
चरण 8) दो शब्दों के बीच समानता ढूँढना
इससे दो शब्दों के बीच समानता की संभावना का परिणाम पता चलेगा। कृपया इस अनुभाग को निष्पादित करने के लिए नीचे दिए गए कोड को देखें।
similarity_two_words = model.similarity('please','see')
print("Please provide the similarity between these two words:")
print(similarity_two_words)
उपरोक्त कोड का परिणाम नीचे दिया गया है
0.13706
आप नीचे दिए गए कोड को निष्पादित करके समान शब्द ढूंढ सकते हैं
similar = model.similar_by_word('kind')
print(similar)
उपरोक्त कोड का आउटपुट:
[('credit', 0.11764447391033173), ('cash', 0.11440904438495636), ('one', 0.11151769757270813), ('hour', 0.0944807156920433), ('using', 0.0705675333738327), ('thats', 0.05206916481256485), ('later', 0.04502468928694725), ('bye', 0.03960943967103958), ('back', 0.03837274760007858), ('thank', 0.0380823090672493)]
निष्कर्ष
- वर्ड एम्बेडिंग एक प्रकार का शब्द प्रतिनिधित्व है जो समान अर्थ वाले शब्दों को मशीन लर्निंग एल्गोरिदम द्वारा समझने की अनुमति देता है
- शब्द एम्बेडिंग का उपयोग समान शब्दों की गणना करने, संबंधित शब्दों का समूह बनाने, पाठ वर्गीकरण के लिए सुविधा, दस्तावेज़ क्लस्टरिंग, प्राकृतिक भाषा प्रसंस्करण के लिए किया जाता है
- Word2vec की व्याख्या: Word2vec एक उथला दो-स्तरीय तंत्रिका नेटवर्क मॉडल है जो बेहतर शब्द प्रतिनिधित्व के लिए शब्द एम्बेडिंग का उत्पादन करता है
- Word2vec शब्दों को वेक्टर स्पेस में प्रदर्शित करता है। शब्दों को वेक्टर के रूप में प्रदर्शित किया जाता है और उन्हें इस तरह से रखा जाता है कि समान अर्थ वाले शब्द एक साथ दिखाई दें और असमान शब्द दूर-दूर स्थित हों
- Word2vec एल्गोरिथ्म 2 आर्किटेक्चर का उपयोग करता है निरंतर शब्दों का बैग (CBOW) और स्किप ग्राम
- सीबीओडब्ल्यू स्किप ग्राम से कई गुना तेज है और लगातार आने वाले शब्दों के लिए बेहतर आवृत्ति प्रदान करता है, जबकि स्किप ग्राम को कम मात्रा में प्रशिक्षण डेटा की आवश्यकता होती है और यह दुर्लभ शब्दों या वाक्यांशों का भी प्रतिनिधित्व करता है।
- NLTK और Word2vec का एक साथ उपयोग करके शक्तिशाली अनुप्रयोग बनाये जा सकते हैं
- न्यूरॉन का सक्रियण फ़ंक्शन इनपुट के एक सेट को देखते हुए उस न्यूरॉन के आउटपुट को परिभाषित करता है। Word2vec में। सॉफ्टमैक्स लेयर (सामान्यीकृत घातीय फ़ंक्शन) आउटपुट लेयर फ़ंक्शन है जो प्रत्येक नोड को सक्रिय या सक्रिय करता है। Word2vec में नेगेटिव सैंपलिंग भी उपलब्ध है
- जेनसिम एक विषय मॉडलिंग टूलकिट है जिसे पायथन में कार्यान्वित किया गया है