Exemplos de Hadoop e Mapreduce: crie o primeiro programa em Java
Neste tutorial, você aprenderá a usar o Hadoop com exemplos de MapReduce. Os dados de entrada usados são VendasJan2009.csv. Ele contém informações relacionadas a vendas, como nome do produto, preço, forma de pagamento, cidade, país do cliente, etc. Descubra o número de produtos vendidos em cada país.
Primeiro programa Hadoop MapReduce
Agora neste Tutorial MapReduce, criaremos nosso primeiro Java Programa MapReduce:
Certifique-se de ter o Hadoop instalado. Antes de iniciar o processo real, altere o usuário para 'hduser' (id usado durante a configuração do Hadoop, você pode mudar para o ID do usuário usado durante a configuração de programação do Hadoop).
su - hduser_

Passo 1)
Crie um novo diretório com nome Tutorial MapReduce como mostrado no exemplo MapReduce abaixo
sudo mkdir MapReduceTutorial
![]()
Dê permissões
sudo chmod -R 777 MapReduceTutorial
![]()
SalesMapper.java
package SalesCountry;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.*;
public class SalesMapper extends MapReduceBase implements Mapper <LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
public void map(LongWritable key, Text value, OutputCollector <Text, IntWritable> output, Reporter reporter) throws IOException {
String valueString = value.toString();
String[] SingleCountryData = valueString.split(",");
output.collect(new Text(SingleCountryData[7]), one);
}
}
SalesCountryReducer.java
package SalesCountry;
import java.io.IOException;
import java.util.*;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.*;
public class SalesCountryReducer extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text t_key, Iterator<IntWritable> values, OutputCollector<Text,IntWritable> output, Reporter reporter) throws IOException {
Text key = t_key;
int frequencyForCountry = 0;
while (values.hasNext()) {
// replace type of value with the actual type of our value
IntWritable value = (IntWritable) values.next();
frequencyForCountry += value.get();
}
output.collect(key, new IntWritable(frequencyForCountry));
}
}
SalesCountryDriver.java
package SalesCountry;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
public class SalesCountryDriver {
public static void main(String[] args) {
JobClient my_client = new JobClient();
// Create a configuration object for the job
JobConf job_conf = new JobConf(SalesCountryDriver.class);
// Set a name of the Job
job_conf.setJobName("SalePerCountry");
// Specify data type of output key and value
job_conf.setOutputKeyClass(Text.class);
job_conf.setOutputValueClass(IntWritable.class);
// Specify names of Mapper and Reducer Class
job_conf.setMapperClass(SalesCountry.SalesMapper.class);
job_conf.setReducerClass(SalesCountry.SalesCountryReducer.class);
// Specify formats of the data type of Input and output
job_conf.setInputFormat(TextInputFormat.class);
job_conf.setOutputFormat(TextOutputFormat.class);
// Set input and output directories using command line arguments,
//arg[0] = name of input directory on HDFS, and arg[1] = name of output directory to be created to store the output file.
FileInputFormat.setInputPaths(job_conf, new Path(args[0]));
FileOutputFormat.setOutputPath(job_conf, new Path(args[1]));
my_client.setConf(job_conf);
try {
// Run the job
JobClient.runJob(job_conf);
} catch (Exception e) {
e.printStackTrace();
}
}
}
Verifique as permissões de arquivo de todos esses arquivos

e se as permissões de 'leitura' estiverem faltando, conceda o mesmo-
![]()
Passo 2)
Exporte o caminho de classe conforme mostrado no exemplo do Hadoop abaixo
export CLASSPATH="$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.2.0.jar:$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-common-2.2.0.jar:$HADOOP_HOME/share/hadoop/common/hadoop-common-2.2.0.jar:~/MapReduceTutorial/SalesCountry/*:$HADOOP_HOME/lib/*"

Passo 3)
Compilar Java arquivos (esses arquivos estão presentes no diretório Final-MapReduceHandsOn). Seus arquivos de classe serão colocados no diretório do pacote
javac -d . SalesMapper.java SalesCountryReducer.java SalesCountryDriver.java

Este aviso pode ser ignorado com segurança.
Esta compilação criará um diretório em um diretório atual nomeado com o nome do pacote especificado no arquivo fonte java (ou seja, País de Vendas no nosso caso) e coloque todos os arquivos de classe compilados nele.

Passo 4)
Crie um novo arquivo Manifesto.txt
sudo gedit Manifest.txt
adicione as seguintes linhas a ele,
Main-Class: SalesCountry.SalesCountryDriver

SalesCountry.SalesCountryDriver é o nome da classe principal. Observe que você deve pressionar a tecla Enter no final desta linha.
Passo 5)
Crie um arquivo Jar
jar cfm ProductSalePerCountry.jar Manifest.txt SalesCountry/*.class
![]()
Verifique se o arquivo jar foi criado

Passo 6)
Inicie o Hadoop
$HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-yarn.sh
Passo 7)
Copie o arquivo VendasJan2009.csv para dentro ~/inputMapReduce
Agora use o comando abaixo para copiar ~/inputMapReduce para HDFS.
$HADOOP_HOME/bin/hdfs dfs -copyFromLocal ~/inputMapReduce /

Podemos ignorar este aviso com segurança.
Verifique se um arquivo foi realmente copiado ou não.
$HADOOP_HOME/bin/hdfs dfs -ls /inputMapReduce

Passo 8)
Execute o trabalho MapReduce
$HADOOP_HOME/bin/hadoop jar ProductSalePerCountry.jar /inputMapReduce /mapreduce_output_sales

Isto criará um diretório de saída chamado mapreduce_output_sales em HDFS. O conteúdo deste diretório será um arquivo contendo as vendas de produtos por país.
Passo 9)
O resultado pode ser visto através da interface de comando como,
$HADOOP_HOME/bin/hdfs dfs -cat /mapreduce_output_sales/part-00000
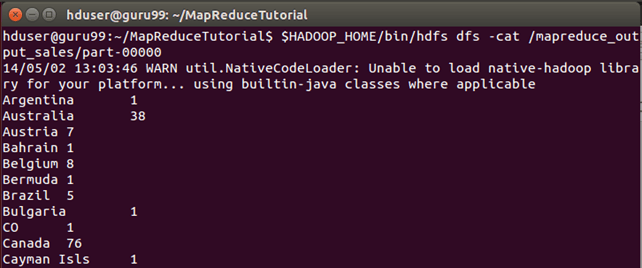
Os resultados também podem ser vistos através de uma interface web como-
Abra r em um navegador da web.

Agora selecione 'Navegar no sistema de arquivos' e navegue até /mapreduce_output_sales

Abra parte-r-00000

Explicação da classe SalesMapper
Nesta seção, entenderemos a implementação de SalesMapper classe.
1. Começamos especificando um nome de pacote para nossa classe. País de Vendas é o nome do nosso pacote. Observe que a saída da compilação, SalesMapper.class irá para um diretório nomeado por este nome de pacote: País de Vendas.
Em seguida, importamos pacotes de biblioteca.
O instantâneo abaixo mostra uma implementação de SalesMapper aula-

Explicação do código de exemplo:
1. Definição de classe SalesMapper-
classe pública SalesMapper estende MapReduceBase implementa Mapper {
Cada classe de mapeador deve ser estendida de MapReduceBase classe e deve implementar Mapper interface.
2. Definindo a função 'mapa'-
public void map(LongWritable key,
Text value,
OutputCollector<Text, IntWritable> output,
Reporter reporter) throws IOException
A parte principal da classe Mapper é um 'mapa()' método que aceita quatro argumentos.
A cada chamada para 'mapa()' método, um valor chave par ('chave' e 'valor' neste código) é passado.
'mapa()' O método começa dividindo o texto de entrada que é recebido como argumento. Ele usa o tokenizer para dividir essas linhas em palavras.
String valueString = value.toString();
String[] SingleCountryData = valueString.split(",");
Aqui, ',' é usado como delimitador.
Depois disso, um par é formado usando um registro no 7º índice do array 'Dados de País Único' e um valor '1'.
output.collect(novo Texto(SingleCountryData[7]), um);
Estamos escolhendo o registro no 7º índice porque precisamos País dados e está localizado no 7º índice da matriz 'Dados de País Único'.
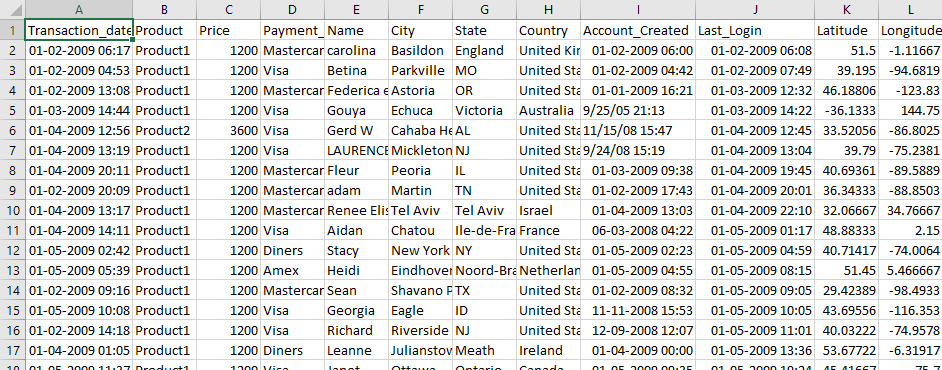
Observe que nossos dados de entrada estão no formato abaixo (onde País é às 7th índice, com 0 como índice inicial)-
Data_da_transação,Produto,Preço,Tipo_de_pagamento,Nome,Cidade,Estado,País,Conta_criada,Último_login,Latitude,Longitude
Uma saída do mapper é novamente um valor chave par que é emitido usando 'coletar ()' método de 'Coletor de saída'.
Explicação da classe SalesCountryReducer
Nesta seção, entenderemos a implementação de SalesCountryReducer classe.
1. Começamos especificando o nome do pacote para nossa classe. País de Vendas é o nome do nosso pacote. Observe que a saída da compilação, SalesCountryReducer.class irá para um diretório nomeado por este nome de pacote: País de Vendas.
Em seguida, importamos pacotes de biblioteca.
O instantâneo abaixo mostra uma implementação de SalesCountryReducer aula-
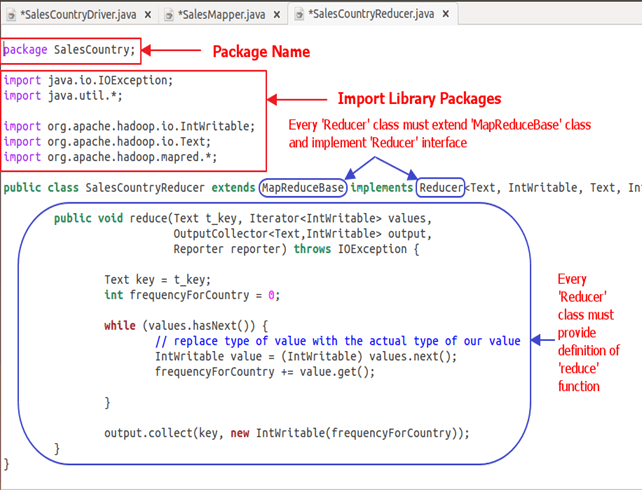
Explicação do código:
1. Definição da classe SalesCountryReducer-
classe pública SalesCountryReducer estende MapReduceBase implementa Redutor {
Aqui, os dois primeiros tipos de dados, 'Texto' e 'Intgravável' são tipos de dados de valor-chave de entrada para o redutor.
A saída do mapeador está na forma de , . Esta saída do mapeador torna-se uma entrada para o redutor. Então, para alinhar com seu tipo de dados, Texto e Intgravável são usados como tipo de dados aqui.
Os dois últimos tipos de dados, 'Texto' e 'IntWritable' são tipos de dados de saída gerados pelo redutor na forma de par chave-valor.
Toda classe redutora deve ser estendida de MapReduceBase classe e deve implementar Redutor interface.
2. Definindo a função 'reduzir'-
public void reduce( Text t_key,
Iterator<IntWritable> values,
OutputCollector<Text,IntWritable> output,
Reporter reporter) throws IOException {
Uma entrada para o reduzir() método é uma chave com uma lista de vários valores.
Por exemplo, no nosso caso, será-
, , , , , .
Isso é dado ao redutor como
Portanto, para aceitar argumentos desta forma, os primeiros dois tipos de dados são usados, a saber, Texto e Iterador. Texto é um tipo de dados de chave e Iterador é um tipo de dados para a lista de valores dessa chave.
O próximo argumento é do tipo Coletor de saída que coleta a saída da fase redutora.
reduzir() O método começa copiando o valor da chave e inicializando a contagem de frequência como 0.
Chave de texto = t_key;
int frequênciaForCountry = 0;
Então, usando 'enquanto' loop, iteramos pela lista de valores associados à chave e calculamos a frequência final somando todos os valores.
while (values.hasNext()) {
// replace type of value with the actual type of our value
IntWritable value = (IntWritable) values.next();
frequencyForCountry += value.get();
}
Agora, enviamos o resultado para o coletor de saída na forma de chave e obtido contagem de freqüência.
O código abaixo faz isso-
output.collect(key, new IntWritable(frequencyForCountry));
Explicação da classe SalesCountryDriver
Nesta seção, entenderemos a implementação de SalesCountryDriver classe
1. Começamos especificando um nome de pacote para nossa classe. País de Vendas é o nome do nosso pacote. Observe que a saída da compilação, SalesCountryDriver.class irá para o diretório nomeado por este nome de pacote: País de Vendas.
Aqui está uma linha especificando o nome do pacote seguido do código para importar pacotes de biblioteca.

2. Defina uma classe de driver que criará um novo trabalho de cliente, objeto de configuração e anunciará classes Mapeadora e Redutora.
A classe driver é responsável por configurar nosso trabalho MapReduce para ser executado em Hadoop. Nesta classe, especificamos nome do trabalho, tipo de dados de entrada/saída e nomes das classes mapeadoras e redutoras.

3. No trecho de código abaixo, definimos diretórios de entrada e saída que são usados para consumir o conjunto de dados de entrada e produzir saída, respectivamente.
arg [0] e arg [1] são os argumentos de linha de comando passados com um comando fornecido no MapReduce prático, ou seja,
$HADOOP_HOME/bin/hadoop jar ProductSalePerCountry.jar /inputMapReduce /mapreduce_output_sales

4. Acione nosso trabalho
Abaixo do código inicia a execução do trabalho MapReduce-
try {
// Run the job
JobClient.runJob(job_conf);
} catch (Exception e) {
e.printStackTrace();
}