Локаторы в Selenium
⚡ Умное резюме
Локаторы в Selenium Это команды, которые указывают механизму автоматизации идентифицировать элементы графического интерфейса пользователя, такие как текстовые поля, кнопки и флажки. В этом справочнике объясняются типы локаторов ID, Name, Link Text, DOM и XPath с практическими примерами, правилами синтаксиса и стратегиями выбора для создания надежных сценариев веб-автоматизации.

Что такое локаторы в Selenium?
Локатор — это команда, которая направляет Selenium IDE или Selenium WebDriver направляет запрос к нужному элементу графического интерфейса пользователя, например, текстовому полю, кнопке, ссылке или флажку, на котором необходимо выполнить действие. Идентификация правильного элемента графического интерфейса является необходимым условием для создания любого надежного скрипта автоматизации. Однако точная идентификация сложнее, чем кажется. Иногда вы можете взаимодействовать не с тем элементом или вообще ни с каким элементом. Чтобы решить эту проблему, Selenium Предлагает различные стратегии определения местоположения, позволяющие точно нацеливаться на элементы графического интерфейса пользователя.
Хотя некоторые команды, например команда «открыть», не требуют указания местоположения, большинство из них Selenium Команды зависят от указателей элементов. Выбор локатора во многом зависит от тестируемого приложения (AUT). В этом уроке мы будем поочередно использовать Facebook и Mercury Демонстрационный сайт туров (newtours.demoaut) зависит от того, какие локации поддерживает каждое приложение. Аналогично и в вашем собственном приложении. тестов В рамках проекта вы выберете локатор элементов. Selenium WebDriver, основанный на структуре вашего приложения.
Поиск по идентификатору
Это наиболее распространенный метод поиска элементов, поскольку идентификаторы (ID) должны быть уникальными для каждого элемента на странице. Если атрибут ID существует, его следует использовать в первую очередь для создания быстрых, стабильных и читаемых тестовых скриптов.
Target Формат: id=id элемента
В этом примере мы будем использовать демонстрационную страницу Facebook, потому что Mercury В основной форме Tours не используются атрибуты ID.
Шаг 1) Используйте эту демонстрационную страницу https://demo.guru99.com/test/facebook.html Для тестирования проверьте текстовое поле «Электронная почта или телефон» с помощью встроенных инструментов разработчика вашего браузера (нажмите F12 в Chrome, Edge или...). Firefox) и запишите его идентификатор. В данном случае идентификатор — «email».

Шаг 2) Запуск Selenium IDE и введите «id=email» в Target поле. Нажмите кнопку «Найти» и обратите внимание, что текстовое поле «Электронная почта или телефон» выделено желтым цветом с зеленой рамкой, что указывает на то, что Selenium IDE правильно обнаружила элемент.

Поиск по имени
Поиск элементов по имени аналогичен поиску по идентификатору, за исключением того, что мы используем... «имя =» Вместо этого используйте префикс. Такой подход полезен, когда у элементов отсутствует идентификатор, но определен атрибут имени.
Target Формат: name=имя элемента
Для следующей демонстрации мы будем использовать Mercury Туры, потому что все значимые элементы дизайна на сайте имеют атрибут имени.
Шаг 1) Перейдите в https://demo.guru99.com/test/newtours/ Используйте инструменты разработчика браузера, чтобы проверить текстовое поле «Имя пользователя». Обратите внимание на его атрибут name.

Здесь имя элемента — «userName».
Шаг 2) In Selenium IDE, введите «name=userName» в поле Target и нажмите кнопку Найти. Selenium IDE должна найти текстовое поле «Имя пользователя», выделив его.

Как найти элемент по имени с помощью фильтров
Фильтры полезны, когда несколько элементов имеют одинаковое имя. Фильтры — это дополнительные атрибуты, используемые для различения элементов с одинаковым именем. Без фильтров, Selenium По умолчанию будет выбран только первый совпадающий элемент.
Target Формат: name=name_of_the_element filter=value_of_filter
Давайте рассмотрим пример.
Шаг 1) Войти на Mercury Туры.
Войдите в Mercury Для начала, используйте слово «tutorial» в качестве имени пользователя и пароля. Должна отобразиться страница поиска рейсов, как показано ниже.

Шаг 2) Используйте инструменты разработчика для просмотра атрибутов VALUE.
Обратите внимание, что переключатели «Везде» и «В одну сторону» имеют одинаковое имя «tripType». Однако у них разные атрибуты VALUE, поэтому мы можем использовать каждое значение в качестве фильтра.

Шаг 3) Щёлкните по первой строке в редакторе.
- Сначала мы выберем переключатель «Одностороннее движение». Нажмите на первую строку в... Selenium IDE-редактор.
- В поле «Команда» введите команду «клик».
- В Target В поле введите “name=tripType value=oneway”. Часть “value=oneway” служит фильтром.

Шаг 4) Щелкните кнопку "Найти".
Заметить, что Selenium IDE выделяет переключатель One Way зелёным цветом, подтверждая, что доступ к элементу через его атрибут VALUE был успешно получен.

Шаг 5) Выберите переключатель «Одностороннее движение».
Нажмите клавишу «X» на клавиатуре, чтобы выполнить команду щелчка. Теперь выбран переключатель «Одностороннее движение».

Аналогичное действие можно выполнить и с переключателем "Верхний путь", на этот раз указав в качестве цели "name=tripType value=roundtrip".
Поиск по тексту ссылки
Эта стратегия поиска применяется только к текстам гиперссылок. Мы получаем доступ к ссылке, добавляя перед целевым элементом префикс «link=», за которым следует видимый текст гиперссылки. Этот метод очень удобен для чтения и хорошо подходит для тестирования навигации.
Target Формат: ссылка=link_text
В следующем примере мы перейдем по ссылке «ЗАРЕГИСТРИРОВАТЬСЯ», расположенной на Mercury Домашняя страница туров.
Шаг 1)
- Во-первых, убедитесь, что вы вышли из своей учетной записи. Mercury Туры.
- Перейдите в Mercury Домашняя страница туров.
Шаг 2)
- Используйте инструменты разработчика, чтобы проверить ссылку «REGISTER». Текст ссылки отображается между открывающим и закрывающим тегами привязки.
- В данном случае текст ссылки — «ЗАРЕГИСТРИРОВАТЬСЯ». Скопируйте текст ссылки.
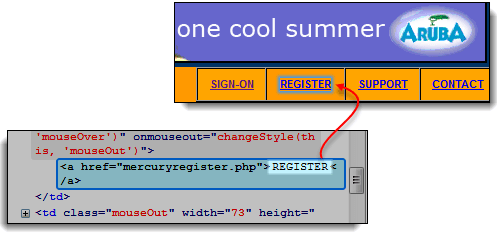
Шаг 3) Скопируйте текст ссылки и вставьте его в... Selenium IDE Target box. Добавьте к нему префикс «link=».

Шаг 4) Щелкните кнопку "Найти". Selenium IDE корректно выделит ссылку REGISTER.

Шаг 5) Для дальнейшей проверки введите «clickAndWait» в поле «Команда» и выполните ее. Selenium IDE успешно нажмет на ссылку «РЕГИСТРАЦИЯ» и перенаправит вас на страницу регистрации, показанную ниже.

Поиск по DOM (объектная модель документа)
Объектная модель документа (DOM)Проще говоря, это описывает структуру HTML-элементов в виде дерева узлов. Selenium IDE может перемещаться по этому дереву для доступа к элементам страницы. При использовании этого метода... Target Блок всегда начинается с «dom=document…». Префикс «dom=» обычно опускается, потому что Selenium IDE автоматически интерпретирует любое значение, начинающееся с «document», как путь к элементу DOM.
Существует четыре основных способа определения местоположения элемента в DOM. Selenium:
- getElementById
- getElementsByName
- dom:name (применяется только к элементам внутри именованной формы)
- дом:индекс
Поиск по DOM – getElementById
Давайте сначала рассмотрим метод getElementById в DOM. SeleniumЭтот метод возвращает один элемент, сопоставляя его с атрибутом ID.
Синтаксис
document.getElementById("id of the element")
- Идентификатор элемента = значение атрибута ID элемента, к которому осуществляется доступ. Это значение всегда должно быть заключено в кавычки.
Шаг 1) Используйте эту демонстрационную страницу https://demo.guru99.com/test/facebook.htmlПерейдите к нему и с помощью инструментов разработчика проверьте флажок «Оставаться авторизованным». Запишите его идентификатор.

Идентификатор, который нам следует использовать, — «persist_box».
Шаг 2) Открыто Selenium IDE и в Target Введите в поле document.getElementById(“persist_box”), затем нажмите «Найти». Selenium IDE обнаружит флажок «Оставаться авторизованным». Хотя она не может выделить внутреннюю часть флажка, она окружит элемент ярко-зеленой рамкой, как показано ниже.

Поиск по DOM – getElementsByName
Метод getElementById обращается только к одному элементу за раз, а именно к элементу с указанным ID. Метод getElementsByName работает иначе. Он возвращает массив элементов, имеющих одинаковое имя. Доступ к отдельным элементам осуществляется с помощью числового индекса, начинающегося с 0.
 |
getElementById Функция возвращает только один элемент. Этот элемент имеет идентификатор, указанный в скобках функции getElementById(). |
 |
getElementsByName Функция возвращает коллекцию элементов с одинаковыми именами. Каждый элемент индексируется числом, начиная с 0, как в массиве. Выбрать конкретный элемент можно, поместив его индекс в квадратные скобки в синтаксисе ниже. |
Синтаксис
document.getElementsByName("name")[index]
- name = имя элемента, определенное его атрибутом name.
- index = целое число, указывающее, какой элемент массива getElementsByName будет использоваться.
Шаг 1) Перейдите в Mercury На главной странице сайта Tours войдите в систему, используя имя пользователя и пароль «tutorial». После этого в браузере загрузится экран поиска рейсов.
Шаг 2) Используйте инструменты разработчика, чтобы проверить три переключателя внизу страницы (эконом-класс, бизнес-класс и первый класс). Обратите внимание, что у всех них одно и то же имя — «servClass».

Шаг 3) Для начала давайте получим доступ к переключателю «Эконом-класс». Из трех переключателей этот элемент отображается первым, поэтому его индекс равен 0. Selenium В IDE введите document.getElementsByName(“servClass”)[0] и нажмите кнопку «Найти». Selenium IDE правильно распознает переключатель "Эконом-класс".

Шаг 4) Измените порядковый номер на 1, чтобы ваш Target становится document.getElementsByName(“servClass”)[1]. Нажмите кнопку «Найти», и Selenium IDE выделит переключатель «Бизнес-класс», как показано ниже.

Поиск по DOM – dom:name
Как упоминалось ранее, этот метод применим только в том случае, если элемент, к которому вы обращаетесь, находится внутри именованной формы. Путь локатора начинается с формы, а затем переходит к целевому элементу по имени.
Синтаксис
document.forms["name of the form"].elements["name of the element"]
- имя формы = значение атрибута name тега формы, содержащего элемент, к которому вы хотите получить доступ
- имя элемента = значение атрибута имени элемента, к которому вы хотите получить доступ.
Шаг 1) Перейдите в Mercury Домашняя страница туров https://demo.guru99.com/test/newtours/ Используйте инструменты разработчика, чтобы проверить текстовое поле «Имя пользователя». Обратите внимание, что оно находится в форме с именем «home».

Шаг 2) In Selenium В IDE введите document.forms[“home”].elements[“userName”] и нажмите кнопку «Найти». Selenium IDE успешно получит доступ к элементу.

Поиск по DOM – dom:index
Этот метод применяется даже тогда, когда элемент не находится внутри именованной формы, поскольку он использует индекс формы вместо её имени. Это полезно для устаревших страниц или автоматически генерируемых форм, где присвоение имен недоступно.
Синтаксис
document.forms[index of the form].elements[index of the element]
- Индекс формы = порядковый номер формы (начиная с 0) относительно всей страницы.
- Индекс элемента = порядковый номер элемента (начиная с 0) относительно формы, в которой он находится.
Мы откроем текстовое поле «Телефон» на Mercury Страница регистрации на туры. Форма на этой странице не содержит ни имени, ни идентификатора, поэтому она хорошо подходит в качестве примера.
Шаг 1) Перейдите в Mercury На странице регистрации на экскурсии обратите внимание на текстовое поле «Телефон». Заметьте, что в окружающей форме отсутствуют поля «ID» и «Имя».

Шаг 2) Введите document.forms[0].elements[3] в Selenium IDE Target и нажмите кнопку Найти. Selenium IDE корректно обработает текстовое поле "Телефон".

Шаг 3) В качестве альтернативы, для достижения того же результата можно использовать имя элемента вместо его индекса. Введите document.forms[0].elements[“phone”] в Target Поле. Текстовое поле «Телефон» останется выделенным.

Поиск по XPath
XPath — это язык запросов, используемый для навигации по узлам XML (расширяемого языка разметки). Поскольку HTML можно считать реализацией XML, XPath Также может определять местоположение HTML-элементов. Это одна из самых мощных стратегий поиска. Selenium.
- Преимущество: Он может получить доступ практически к любому элементу, включая те, которые не имеют атрибутов класса, имени или идентификатора.
- Недостаток: Это наиболее сложная стратегия поиска из-за множества правил и вариантов синтаксиса.
Современные инструменты разработчика браузеров могут автоматически генерировать выражения XPath. В Chrome, Edge или FirefoxЩелкните правой кнопкой мыши по элементу на панели «Элементы» и выберите «Копировать» > «Копировать XPath». В следующем примере мы получим доступ к изображению, которое не удалось найти с помощью методов, описанных ранее.
Шаг 1) Перейдите в Mercury Просмотрите главную страницу веб-тура и воспользуйтесь инструментами разработчика, чтобы изучить оранжевый прямоугольник справа от желтого блока «Ссылки», как показано ниже.

Шаг 2) Щелкните правой кнопкой мыши по HTML-коду элемента, затем выберите опцию «Скопировать XPath».

Шаг 3) In Selenium IDEВведите одинарную косую черту «/» в поле Target Затем вставьте в поле XPath, скопированный на предыдущем шаге. Запись в Target Теперь поле должно начинаться с двух косых черт «//».

Шаг 4) Щелкните кнопку "Найти". Selenium IDE выделит оранжевый прямоугольник, как показано ниже.

Почему важно выбрать правильный локатор
Выбор правильной стратегии поиска — одно из наиболее важных решений. Selenium Автоматизация важна, поскольку она напрямую влияет на стабильность скриптов, скорость выполнения и долгосрочные затраты на обслуживание. Неправильно выбранный локатор может привести к нестабильным тестам, ложным сбоям и частой переработке при каждом изменении пользовательского интерфейса приложения. Опытные инженеры по автоматизации рекомендуют следующий порядок приоритетов: сначала ID, затем Name, затем CSS Selector, Link Text и, наконец, XPath.
Локаторы на основе идентификаторов являются самыми быстрыми, поскольку поиск в браузере оптимизирован для уникальных идентификаторов. Локаторы на основе имен почти так же эффективны, когда имена уникальны. Селекторы CSS и XPath обеспечивают гибкость, но, как правило, работают медленнее и более ненадежны при рефакторинге DOM. Текст ссылки отлично подходит для навигационных ссылок, но имеет ограниченные возможности повторного использования.
Стабильная автоматизация также зависит от сотрудничества с разработчиками. Когда тестировщики запрашивают согласованные и содержательные идентификаторы или атрибуты data-* во время проверки кода, надежность локаторов значительно повышается. Избегайте использования автоматически генерируемых идентификаторов (например, создаваемых фреймворками), поскольку они могут меняться между сборками. Отдавая приоритет читаемым, ориентированным на намерения локаторам, команды могут поддерживать работоспособность тестовых наборов и сокращать технический долг по мере развития приложения.
Рекомендации по написанию надежных локаторов
Надежные локаторы — это основа для ремонтопригодной системы. Selenium Набор тестов. Следующие методы помогают уменьшить количество ошибок в скриптах, улучшить читаемость и сделать тесты устойчивыми к изменениям пользовательского интерфейса.
- Предпочтительные уникальные идентификаторы: Всегда проверяйте наличие атрибута ID в первую очередь. Идентификаторы предназначены для уникальности в пределах одной страницы и являются наиболее эффективным вариантом с точки зрения производительности.
- Используйте семантические атрибуты Name и data-*: Поощряйте разработчиков добавлять стабильные атрибуты для тестирования, такие как data-testid или data-qa. Они остаются неизменными даже при изменении классов CSS.
- Избегайте использования абсолютных XPath: Абсолютные пути, такие как /html/body/div[2]/div[3]/span, легко ломаются. Используйте относительные выражения XPath с атрибутами, например, //input[@name='userName'].
- Для повышения точности объедините атрибуты: Если один атрибут не является уникальным, объедините несколько атрибутов (например, //button[@type='submit' и @name='login']), чтобы выбрать нужный элемент.
- Используйте текст с умом: Поисковые запросы, зависящие от видимого текста, могут некорректно работать при разных языковых локализациях. Используйте текстовые поисковые запросы только в том случае, если контент стабилен и одноязычен.
- Централизация локаторов: Храните локаторы в классе Page Object Model (POM), чтобы обновления можно было вносить в одном месте, а не во многих тестовых скриптах.
- Проверить в инструментах разработчика: Прежде чем добавлять локатор в скрипт, проверьте его в консоли браузера, используя $x(“//xpath”) для XPath или document.querySelector для CSS, чтобы убедиться, что он возвращает ровно один элемент.
- По возможности избегайте использования локаторов на основе индексов: Позиции индексов, такие как [3], зависят от порядка элементов. Даже незначительные изменения в макете могут сместить индекс и нарушить работу скрипта.
Последовательно применяя эти методы, инженеры по автоматизации создают наборы тестов, которые масштабируются в разных командах и выдерживают частые обновления пользовательского интерфейса с минимальным обслуживанием.