SQL Server Archiтектура (объяснение)
⚡ Умное резюме
SQL Server ArchiАрхитектура построена по клиент-серверной модели и состоит из трех основных уровней: протокольного уровня для сетевой связи, реляционного механизма для обработки запросов и механизма хранения данных для управления и извлечения данных.

MS SQL Server — это клиент-серверная архитектура. Процесс работы MS SQL Server начинается с отправки клиентским приложением запроса. SQL Server принимает, обрабатывает запрос и отвечает на него обработанными данными. Давайте подробно рассмотрим всю архитектуру, показанную ниже:
Как показано на приведенной ниже диаграмме, SQL Server состоит из трех основных компонентов. Archiтекстура:
- Уровень протокола
- Реляционный движок
- Механизм хранения
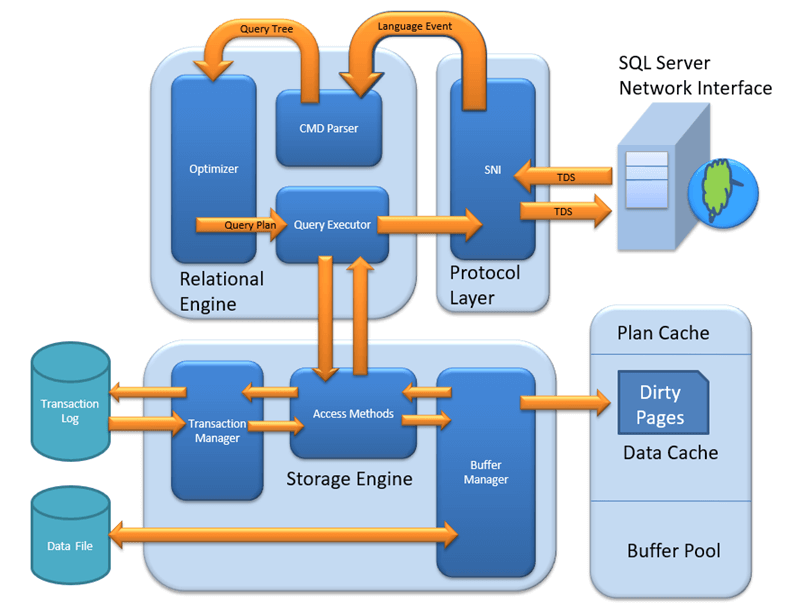
Уровень протокола – SNI
Протокольный уровень SQL Server, также известный как сетевой интерфейс сервера (SNI), поддерживает три типа клиент-серверной архитектуры. Каждый протокол предназначен для различных сетевых сценариев. Понимание этих протоколов необходимо, прежде чем изучать внутреннюю обработку запросов.
Общая память
Рассмотрим сценарий утреннего разговора. Том и его мама находятся в одном и том же логичном месте — у себя дома. Том заказывает кофе, и мама сразу же его приносит. Аналогично, SQL Server предоставляет протокол разделяемой памяти, когда клиент и сервер работают на одной машине. Оба обмениваются данными через разделяемую память без каких-либо сетевых накладных расходов.

Аналогия: Том соответствует клиенту, мама — SQL Server, дом — машине, а устное общение — протоколу разделяемой памяти.

Примечания к конфигурации: In Студия управления SQLВ качестве параметра «Имя сервера» для локального подключения можно использовать «.», «localhost», «127.0.0.1» или «Machine\Instance».
TCP / IP
Теперь представим, что Том хочет купить кофе в магазине, расположенном в 10 км от него. Том дома, а кофейня находится на оживленном рынке. Они общаются через сотовую сеть. Аналогично, SQL Server предоставляет... Протокол TCP / IP когда клиент и SQL Server находятся на разных машинах, соединенных по сети.

Аналогия: Tom соответствует клиенту, кофейня — SQL Server, дом и торговая площадка — удаленным местоположениям, а сотовая сеть — протоколу TCP/IP.

Примечания к конфигурации: В SQL Management Studio параметр «Имя сервера» для TCP/IP-соединения должен быть установлен на «Машина\Экземпляр сервера». SQL Server по умолчанию использует порт 1433 для TCP/IP-соединений.
Именованные трубы
Наконец, Том хочет зеленый чай от своей соседки Сьерры. Они находятся в одном физическом месте, будучи соседями, и общаются через внутрисетевое соединение. Аналогично, SQL Server предоставляет протокол именованных каналов (Named Pipe), когда клиент и сервер соединены через локальную сеть (LAN).

Аналогия: Tom соответствует клиенту, Sierra — SQL Server, соседство — локальной сети, а внутрисетевое взаимодействие — протоколу именованных каналов.
Примечания к конфигурации: Функция «Именованные каналы» по умолчанию отключена и должна быть включена через диспетчер конфигурации SQL.
Что такое TDS?
Теперь, когда три типа клиент-серверной архитектуры стали понятны, давайте рассмотрим TDS:
- TDS означает поток табличных данных.
- Все три протокола используют пакеты TDS.
- Технология TDS инкапсулируется в сетевые пакеты, что позволяет передавать данные с клиентского компьютера на серверный.
- Система TDS была первоначально разработана компанией Sybase, а сейчас принадлежит другой компании. Microsoft.
В следующей таблице приведено сравнение трех протоколов подключения к SQL Server:
| Характеристика | Общая память | TCP / IP | Именованные трубы |
|---|---|---|---|
| Сфера действия сети | Та же машина | Удаленный доступ (WAN/Интернет) | Только LAN |
| Порт по умолчанию | ARCXNUMX | 1433 | 445 |
| Эффективности | Самый быстрый (без сетевых накладных расходов) | Хорошо (оптимизировано для WAN) | Хорошо (оптимизировано для локальной сети) |
| Включено по умолчанию | Да | Да | Нет |
| лучший вариант использования | Локальная разработка и тестирование | Удаленный доступ к производству | Надежные локальные сети |
После того как протокольный уровень обрабатывает сетевую связь, следующим шагом в архитектуре SQL Server является обработка самого запроса. Именно здесь вступает в действие реляционный механизм.
Реляционный движок
Реляционный механизм также известен как обработчик запросов. Он содержит компоненты SQL Server, которые определяют, что должен делать запрос и как его можно выполнить наиболее эффективно. Он отвечает за выполнение пользовательских запросов, запрашивая данные у механизма хранения и обрабатывая возвращаемые результаты.
Как показано на архитектурной схеме, реляционный движок состоит из трех основных компонентов:
CMD-парсер
Данные, полученные с уровня протокола, передаются в реляционный механизм. Парсер CMD является первым компонентом, получающим данные запроса. Его основная задача — проверить запрос на наличие синтаксических и семантических ошибок, а затем построить дерево запроса.

Синтаксическая проверка: Как и в любом другом языке программирования, в SQL Server существует предопределенный набор ключевых слов и грамматических правил. К этому списку относятся SELECT, INSERT, UPDATE и многие другие. Парсер CMD проверяет, соответствует ли ввод этим правилам. Если ввод пользователя отклоняется от ожидаемого синтаксиса, парсер возвращает ошибку.
Пример: Представьте, что русский человек заходит в японский ресторан и делает заказ на русском языке. Официант понимает только японский и не может обработать заказ. Аналогично, если пользователь вводит «SELECR» вместо «SELECT», парсер CMD выдает ошибку, поскольку не распознает ключевое слово.
Семантическая проверка: Это выполняется нормализатором. Он проверяет, существуют ли в схеме имена столбцов, имена таблиц и другие объекты, к которым обращается запрос. Если они существуют, нормализатор привязывает их к запросу. Этот процесс также известен как привязка. Когда пользовательские запросы содержат представление (VIEW), нормализатор заменяет его внутренне хранящимся определением представления.
Пример: Бег SELECT * from USER_ID Если таблица USER_ID не существует в базе данных, парсер выдаст ошибку во время семантической проверки.
Создать дерево запросов: На этом этапе генерируются различные деревья выполнения, представляющие разные способы запуска запроса. Все деревья выдают один и тот же желаемый результат.
Оптимизатор
Оптимизатор создает план выполнения запроса пользователя. Этот план определяет, как будет выполняться запрос. Оптимизация применяется не ко всем запросам. Оптимизация применяется к командам DML (язык модификации данных), таким как SELECT, INSERT, DELETE и UPDATE. Команды DDL, такие как CREATE и ALTER, не оптимизируются, а компилируются во внутреннюю форму.

Стоимость запроса рассчитывается на основе таких факторов, как загрузка ЦП, использование памяти и потребности во вводе/выводе. Роль оптимизатора заключается в поиске наиболее экономичного плана выполнения, а не обязательно самого лучшего.
Пример: Представьте, что вы хотите открыть онлайн-банковский счет. В одном банке это занимает максимум 2 дня. У вас также есть список из 20 других банков, которые могут предложить более быстрый вариант, а могут и нет. Поиск по всем 20 банкам может не дать более быстрого решения, а сам поиск отнимает время. Было бы лучше выбрать первый попавшийся банк. Аналогично, оптимизатор SQL использует исчерпывающие и эвристические алгоритмы для минимизации времени выполнения запросов.
Оптимизатор выполняет поиск в три этапа:
Этап 0: Поиск простого плана
Это этап предварительной оптимизации. Для некоторых запросов существует только один практически осуществимый план, известный как тривиальный план. Дальнейший поиск не требуется, поскольку любой дополнительный поиск приведет к обнаружению того же плана выполнения с дополнительными затратами.
Этап 1: Поиск планов обработки транзакций
Это включает поиск как простых, так и сложных планов. Поиск простых планов использует статистический анализ данных столбцов и индексов, как правило, ограничиваясь одним индексом на таблицу. Если простой план не найден, выполняется более сложный поиск, включающий несколько индексов на таблицу.
Этап 2: Параллельная обработка и оптимизация
Если предыдущие стратегии не позволяют получить адекватный план, оптимизатор ищет возможности параллельной обработки, исходя из вычислительных возможностей машины. Если параллельная обработка невозможна, начинается заключительная фаза оптимизации, в которой используются все оставшиеся варианты для поиска наилучшего возможного плана выполнения.
Исполнитель запросов
Исполнитель запросов вызывает метод доступа в механизме хранения. Он предоставляет план выполнения, содержащий логику получения данных, необходимую для выполнения запроса. После получения данных от механизма хранения результат публикуется на уровне протокола и отправляется конечному пользователю.

После того как реляционный модуль определяет способ выполнения запроса, модуль хранения данных обрабатывает физические операции с данными. Этот уровень управляет хранением, кэшированием и извлечением данных с диска.
Механизм хранения
Модуль хранения данных отвечает за хранение данных в системе хранения, такой как диск или SAN, и за их извлечение при необходимости. Прежде чем рассматривать компоненты модуля хранения данных, важно понять, как физически хранятся данные.

Файлы данных и их содержимое
Физически файлы данных хранят информацию в виде страниц, каждая из которых имеет размер 8 КБ. Это наименьшая единица хранения данных в... SQL ServerСтраницы данных логически сгруппированы в экстенты. Ни одному объекту не назначается отдельная страница напрямую; вместо этого обслуживание осуществляется через экстенты. Каждая страница имеет заголовок страницы (96 байт), содержащий метаданные, такие как тип страницы, номер страницы, используемое пространство, свободное пространство и указатели на следующую и предыдущую страницы.
Типы файлов

Основной файл: Каждая база данных содержит один основной файл. В нем хранятся все важные данные, относящиеся к таблицам, представлениям, триггерам и другим объектам. Расширение файла обычно .mdf, но может быть любым.
Дополнительный файл: База данных может содержать или не содержать несколько дополнительных файлов. Они являются необязательными и содержат данные, специфичные для пользователя. Расширение файла обычно .ndf, но может быть любым.
Журнальный файл: Также известны как журналы предварительной записи. Расширение — .ldf. Файлы журналов используются для управления транзакциями, восстановления после нежелательных событий и выполнения отката незавершенных транзакций.
Механизм хранения данных состоит из трех основных компонентов. Каждый из них играет определенную роль в управлении доступом к данным и обеспечении их целостности.
Метод доступа
Метод доступа выступает в качестве интерфейса между исполнителем запросов и Buffer Менеджер или журналы транзакций. Он сам не выполняет запрос, но определяет его тип:
- Если запрос является Оператор SELECT (DML)оно передается в Buffer Менеджер для дальнейшей обработки.
- Если запрос является Операторы, не являющиеся операторами SELECT (DDL и DML)Затем данные передаются менеджеру транзакций. В основном это операторы UPDATE, INSERT и DELETE.

Buffer Менеджер
Buffer Менеджер управляет основными функциями кэширования планов, анализа данных и обработки измененных страниц.

Кэш плана
Существующий план запроса: Buffer Менеджер проверяет, существует ли план выполнения в сохраненном кэше планов. Если существует, то кэшированный план запроса и связанный с ним кэш данных используются напрямую.
План кэширования для первого использования: Если план выполнения запроса при первом выполнении является сложным, он сохраняется в кэше планов. Это обеспечивает более быструю доступность при следующем получении SQL Server того же запроса.
Анализ данных: Buffer Кэш и хранилище данных
Buffer Менеджер обеспечивает доступ к необходимым данным. В зависимости от наличия данных в кэше возможны два подхода:
Buffer Кэш – Мягкий анализ
Buffer Менеджер ищет данные в Buffer Кэш. Если данные присутствуют, исполнитель запросов использует их напрямую. Это повышает производительность, поскольку получение данных из кэша требует меньше операций ввода-вывода по сравнению с получением данных из дискового хранилища.

Хранение данных – жесткий анализ
Если данные отсутствуют в Buffer Для кэширования необходимые данные ищутся в хранилище данных на диске. Затем эти данные также сохраняются в кэше данных для дальнейшего использования.

Менеджер транзакций
Менеджер транзакций вызывается, когда метод доступа определяет, что запрос не является оператором SELECT. Он обеспечивает согласованность и надежность данных с помощью нескольких подкомпонентов:

Диспетчер журналов
Менеджер журналов отслеживает все обновления, выполненные в системе, посредством журналов, хранящихся в журналах транзакций. Каждая запись в журнале содержит порядковый номер журнала, а также идентификатор транзакции и запись об изменении данных. Этот механизм отслеживает подтвержденные и отмененные транзакции.
Менеджер блокировки
В ходе транзакции связанные данные в хранилище переходят в заблокированное состояние. Менеджер блокировок обрабатывает этот процесс, обеспечивая согласованность и изоляцию данных. Эти свойства также известны как ACID (ACID).Atomледяность, постоянство, изоляция, долговечность).
Процесс исполнения
Процесс выполнения состоит из следующих шагов:
- Менеджер журналов начинает запись данных, а менеджер блокировок блокирует связанные с ними данные.
- Копия данных хранится в Buffer Кэш.
- Копия данных, подлежащих обновлению, хранится в журнале. Bufferи все события обновляют данные в Data Buffer.
- Страницы, хранящие измененные данные, называются Грязные страницы.
Журналирование контрольных точек и предварительной записи
Процесс создания контрольной точки выполняется примерно раз в минуту и помечает все измененные страницы для записи на диск. Однако сначала страница записывается в страницу данных файла журнала. Buffer Журналирование. Этот механизм известен как журналирование с предварительной записью. «Измененные» страницы остаются в кэше даже после записи на диск.
Ленивый писатель
Когда SQL Server обнаруживает высокую нагрузку и требуется буферная память для новых транзакций, он освобождает «грязные» страницы из кэша. Ленивая запись работает по алгоритму LRU (Least Recently Used — наименее недавно использованные), чтобы перемещать страницы из буферного пула на диск.
Как SQL Server обрабатывает запрос от начала до конца
Понимание каждого уровня по отдельности очень важно, но понимание того, как они взаимодействуют друг с другом, позволяет получить полную картину. Когда клиентское приложение отправляет SQL-запрос, происходит следующая последовательность действий:
Уровень протокола Получает запрос через разделяемую память, TCP/IP или именованные каналы и упаковывает его в пакет TDS. Реляционный движок Затем управление переходит к парсеру командной строки (CMD Parser), который проверяет синтаксис и семантику, оптимизатору, который генерирует наиболее экономичный план выполнения, и исполнителю запросов, начинающему извлечение данных.
Исполнитель запросов вызывает Механизмы хранения Метод доступа, который направляет запросы SELECT к Buffer Менеджер и запросы на внесение изменений в Менеджер транзакций. Buffer Менеджер проверяет кэш плана и Buffer Сначала кэшируется (мягкий анализ). Если данные не кэшированы, выполняется чтение с диска (жесткий анализ). Для операций записи менеджер транзакций координирует работу менеджера журналов, менеджера блокировок и процесса контрольных точек для обеспечения соответствия принципам ACID.
После того как механизм хранения возвращает запрошенные данные, механизм реляционного анализа форматирует результирующий набор, а протокольный уровень передает его обратно клиентскому приложению по тому же протоколу TDS.
Как выбрать правильный протокол для подключения к SQL Server
Выбор правильного протокола зависит от физического взаимодействия между клиентом и сервером, а также от требований к производительности.
Использовать общую память Когда клиентское приложение работает на той же машине, что и SQL Server. Это самый быстрый вариант, поскольку он исключает все сетевые накладные расходы. Он идеально подходит для локальной разработки, тестирования и развертывания на одной машине.
Используйте TCP/IP Когда клиент и сервер находятся на разных машинах, соединенных через глобальную сеть или интернет. Это наиболее часто используемый протокол в производственных средах. SQL Server по умолчанию прослушивает порт 1433, и этот протокол поддерживает зашифрованные соединения через TLS.
Используйте именованные каналы Когда клиент и сервер находятся в одной доверенной локальной сети, и приоритет отдается производительности во внутренних сетях, именованные каналы (Named Pipes) по умолчанию отключены и должны быть включены через диспетчер конфигурации SQL Server. В современных развертываниях они встречаются реже, но остаются полезными для устаревших приложений интрасети.