Seq2seq (Sequence to Sequence) mudel PyTorchiga
Mis on NLP?
NLP ehk loomuliku keele töötlemine on üks populaarsemaid tehisintellekti harusid, mis aitab arvutitel mõista, manipuleerida või reageerida inimesele tema loomulikus keeles. NLP on mootor taga Google Translate mis aitab meil mõista teisi keeli.
Mis on Seq2Seq?
Seq2Seq on kodeerijal-dekoodril põhineva masintõlke ja keeletöötluse meetod, mis kaardistab jada sisendi jada väljundiks koos sildi ja tähelepanuväärtusega. Idee on kasutada 2 RNN-i, mis töötavad koos spetsiaalse märgiga ja proovivad ennustada eelmise jada järgmist olekujada.
Kuidas ennustada jada eelmisest jadast
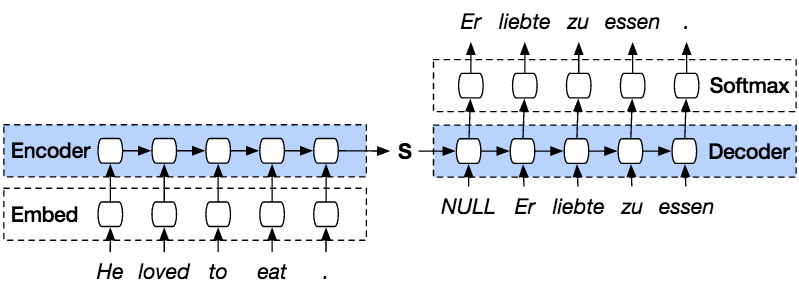
Järgmised sammud PyTorchiga eelmise järjestuse ennustamiseks.
1. samm) meie andmete laadimine
Meie andmestiku jaoks kasutate andmestikku alates Tabulaatoriga eraldatud kakskeelsed lausepaarid. Siin kasutan andmestikku inglise-indoneesia keelest. Saate valida kõike, mis teile meeldib, kuid ärge unustage koodis failinime ja kataloogi muuta.
from __future__ import unicode_literals, print_function, division
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import numpy as np
import pandas as pd
import os
import re
import random
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
2. etapp) andmete ettevalmistamine
Te ei saa andmestikku otse kasutada. Peate laused sõnadeks jagama ja teisendama One-Hot Vectoriks. Sõnastiku koostamiseks indekseeritakse iga sõna Lang-klassis ainulaadselt. Lang klass salvestab iga lause ja jagab selle sõna-sõnalt koos lisalausega. Seejärel looge sõnastik, indekseerides järjestuse mudelite jaoks kõik tundmatud sõnad.
SOS_token = 0
EOS_token = 1
MAX_LENGTH = 20
#initialize Lang Class
class Lang:
def __init__(self):
#initialize containers to hold the words and corresponding index
self.word2index = {}
self.word2count = {}
self.index2word = {0: "SOS", 1: "EOS"}
self.n_words = 2 # Count SOS and EOS
#split a sentence into words and add it to the container
def addSentence(self, sentence):
for word in sentence.split(' '):
self.addWord(word)
#If the word is not in the container, the word will be added to it,
#else, update the word counter
def addWord(self, word):
if word not in self.word2index:
self.word2index[word] = self.n_words
self.word2count[word] = 1
self.index2word[self.n_words] = word
self.n_words += 1
else:
self.word2count[word] += 1
Langi klass on klass, mis aitab meil sõnaraamatut koostada. Iga keele puhul jagatakse iga lause sõnadeks ja lisatakse seejärel konteinerisse. Iga konteiner salvestab sõnad vastavasse registrisse, loendab sõna ja lisab sõna indeksi, et saaksime seda kasutada sõna indeksi või selle registrist sõna leidmiseks.
Kuna meie andmed on eraldatud TAB-ga, peate kasutama pandas meie andmelaadijana. Pandas loeb meie andmeid dataFrame'ina ja jagab need lähte- ja sihtlauseks. Iga lause eest, mis sul on,
- normaliseerite selle väiketähtedega,
- eemalda kõik mittetähemärgid
- teisendada Unicode'ist ASCII-ks
- poolitage laused, nii et teil on selles iga sõna.
#Normalize every sentence
def normalize_sentence(df, lang):
sentence = df[lang].str.lower()
sentence = sentence.str.replace('[^A-Za-z\s]+', '')
sentence = sentence.str.normalize('NFD')
sentence = sentence.str.encode('ascii', errors='ignore').str.decode('utf-8')
return sentence
def read_sentence(df, lang1, lang2):
sentence1 = normalize_sentence(df, lang1)
sentence2 = normalize_sentence(df, lang2)
return sentence1, sentence2
def read_file(loc, lang1, lang2):
df = pd.read_csv(loc, delimiter='\t', header=None, names=[lang1, lang2])
return df
def process_data(lang1,lang2):
df = read_file('text/%s-%s.txt' % (lang1, lang2), lang1, lang2)
print("Read %s sentence pairs" % len(df))
sentence1, sentence2 = read_sentence(df, lang1, lang2)
source = Lang()
target = Lang()
pairs = []
for i in range(len(df)):
if len(sentence1[i].split(' ')) < MAX_LENGTH and len(sentence2[i].split(' ')) < MAX_LENGTH:
full = [sentence1[i], sentence2[i]]
source.addSentence(sentence1[i])
target.addSentence(sentence2[i])
pairs.append(full)
return source, target, pairs
Veel üks kasulik funktsioon, mida kasutate, on paaride teisendamine Tensoriks. See on väga oluline, sest meie võrk loeb ainult tensori tüüpi andmeid. See on oluline ka seetõttu, et selles osas on lause igas lõpus märk, mis annab võrgule teada, et sisend on lõppenud. Lause iga sõna kohta saab ta indeksi sõnastikus olevast sobivast sõnast ja lisab lause lõppu märgi.
def indexesFromSentence(lang, sentence):
return [lang.word2index[word] for word in sentence.split(' ')]
def tensorFromSentence(lang, sentence):
indexes = indexesFromSentence(lang, sentence)
indexes.append(EOS_token)
return torch.tensor(indexes, dtype=torch.long, device=device).view(-1, 1)
def tensorsFromPair(input_lang, output_lang, pair):
input_tensor = tensorFromSentence(input_lang, pair[0])
target_tensor = tensorFromSentence(output_lang, pair[1])
return (input_tensor, target_tensor)
Seq2Seq mudel

PyTorch Seq2seq mudel on omamoodi mudel, mis kasutab PyTorchi kodeerija dekoodrit mudeli peal. Kodeerija kodeerib lause sõna-sõna haaval indekseeritud sõnavarasse või tuntud sõnadesse koos indeksiga ja dekooder ennustab kodeeritud sisendi väljundit, dekodeerides sisendi järjestikku ja proovib kasutada viimast sisendit järgmise sisestusena, kui selle võimalik. Selle meetodi abil on võimalik ennustada ka järgmist sisendit lause loomiseks. Igale lausele määratakse jada lõppu tähistav märk. Ennustuse lõpus on ka väljundi lõppu tähistav märk. Seega edastab see kodeerijalt oleku dekoodrile, et ennustada väljundit.

Kodeerija kodeerib meie sisendlause sõna-sõnalt järjestikku ja lõpuks on lause lõppu tähistav märk. Kodeerija koosneb manustamiskihist ja GRU kihtidest. Manustuskiht on otsingutabel, mis salvestab meie sisendi manustamise kindla suurusega sõnade sõnastikku. See edastatakse GRU kihti. GRU kiht on piiratud korduv üksus, mis koosneb mitmest kihitüübist RNN mis arvutab järjestatud sisendi. See kiht arvutab peidetud oleku eelmisest ja värskendab lähtestamist, värskendamist ja uusi väravaid.

Dekooder dekodeerib sisendi kodeerija väljundist. See proovib ennustada järgmist väljundit ja kasutada seda võimaluse korral järgmise sisendina. Dekooder koosneb manustamiskihist, GRU kihist ja lineaarsest kihist. Manuskiht koostab väljundi jaoks otsingutabeli ja edastab selle GRU kihti, et arvutada prognoositav väljundi olek. Pärast seda aitab lineaarne kiht arvutada aktiveerimisfunktsiooni, et määrata prognoositava väljundi tegelik väärtus.
class Encoder(nn.Module):
def __init__(self, input_dim, hidden_dim, embbed_dim, num_layers):
super(Encoder, self).__init__()
#set the encoder input dimesion , embbed dimesion, hidden dimesion, and number of layers
self.input_dim = input_dim
self.embbed_dim = embbed_dim
self.hidden_dim = hidden_dim
self.num_layers = num_layers
#initialize the embedding layer with input and embbed dimention
self.embedding = nn.Embedding(input_dim, self.embbed_dim)
#intialize the GRU to take the input dimetion of embbed, and output dimention of hidden and
#set the number of gru layers
self.gru = nn.GRU(self.embbed_dim, self.hidden_dim, num_layers=self.num_layers)
def forward(self, src):
embedded = self.embedding(src).view(1,1,-1)
outputs, hidden = self.gru(embedded)
return outputs, hidden
class Decoder(nn.Module):
def __init__(self, output_dim, hidden_dim, embbed_dim, num_layers):
super(Decoder, self).__init__()
#set the encoder output dimension, embed dimension, hidden dimension, and number of layers
self.embbed_dim = embbed_dim
self.hidden_dim = hidden_dim
self.output_dim = output_dim
self.num_layers = num_layers
# initialize every layer with the appropriate dimension. For the decoder layer, it will consist of an embedding, GRU, a Linear layer and a Log softmax activation function.
self.embedding = nn.Embedding(output_dim, self.embbed_dim)
self.gru = nn.GRU(self.embbed_dim, self.hidden_dim, num_layers=self.num_layers)
self.out = nn.Linear(self.hidden_dim, output_dim)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, input, hidden):
# reshape the input to (1, batch_size)
input = input.view(1, -1)
embedded = F.relu(self.embedding(input))
output, hidden = self.gru(embedded, hidden)
prediction = self.softmax(self.out(output[0]))
return prediction, hidden
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device, MAX_LENGTH=MAX_LENGTH):
super().__init__()
#initialize the encoder and decoder
self.encoder = encoder
self.decoder = decoder
self.device = device
def forward(self, source, target, teacher_forcing_ratio=0.5):
input_length = source.size(0) #get the input length (number of words in sentence)
batch_size = target.shape[1]
target_length = target.shape[0]
vocab_size = self.decoder.output_dim
#initialize a variable to hold the predicted outputs
outputs = torch.zeros(target_length, batch_size, vocab_size).to(self.device)
#encode every word in a sentence
for i in range(input_length):
encoder_output, encoder_hidden = self.encoder(source[i])
#use the encoder’s hidden layer as the decoder hidden
decoder_hidden = encoder_hidden.to(device)
#add a token before the first predicted word
decoder_input = torch.tensor([SOS_token], device=device) # SOS
#topk is used to get the top K value over a list
#predict the output word from the current target word. If we enable the teaching force, then the #next decoder input is the next word, else, use the decoder output highest value.
for t in range(target_length):
decoder_output, decoder_hidden = self.decoder(decoder_input, decoder_hidden)
outputs[t] = decoder_output
teacher_force = random.random() < teacher_forcing_ratio
topv, topi = decoder_output.topk(1)
input = (target[t] if teacher_force else topi)
if(teacher_force == False and input.item() == EOS_token):
break
return outputs
3. samm) Modelli koolitamine
Seq2seq mudelite koolitusprotsess algab iga lausepaari teisendamisega nende Langi indeksist Tensoriteks. Meie järjestuse jada mudel kasutab optimeerijana SGD-d ja kadude arvutamiseks funktsiooni NLLLoss. Treeningprotsess algab lausepaari sisestamisega mudelile, et ennustada õiget väljundit. Igal etapil arvutatakse mudeli väljund tõeste sõnadega, et leida kadusid ja värskendada parameetreid. Seega, kuna kasutate 75000 75000 iteratsiooni, genereerib meie jada jada mudel meie andmekogumist juhuslikult XNUMX XNUMX paari.
teacher_forcing_ratio = 0.5
def clacModel(model, input_tensor, target_tensor, model_optimizer, criterion):
model_optimizer.zero_grad()
input_length = input_tensor.size(0)
loss = 0
epoch_loss = 0
# print(input_tensor.shape)
output = model(input_tensor, target_tensor)
num_iter = output.size(0)
print(num_iter)
#calculate the loss from a predicted sentence with the expected result
for ot in range(num_iter):
loss += criterion(output[ot], target_tensor[ot])
loss.backward()
model_optimizer.step()
epoch_loss = loss.item() / num_iter
return epoch_loss
def trainModel(model, source, target, pairs, num_iteration=20000):
model.train()
optimizer = optim.SGD(model.parameters(), lr=0.01)
criterion = nn.NLLLoss()
total_loss_iterations = 0
training_pairs = [tensorsFromPair(source, target, random.choice(pairs))
for i in range(num_iteration)]
for iter in range(1, num_iteration+1):
training_pair = training_pairs[iter - 1]
input_tensor = training_pair[0]
target_tensor = training_pair[1]
loss = clacModel(model, input_tensor, target_tensor, optimizer, criterion)
total_loss_iterations += loss
if iter % 5000 == 0:
avarage_loss= total_loss_iterations / 5000
total_loss_iterations = 0
print('%d %.4f' % (iter, avarage_loss))
torch.save(model.state_dict(), 'mytraining.pt')
return model
4. samm) testige mudelit
Seq2seq PyTorchi hindamisprotsess on mudeli väljundi kontrollimine. Iga järjestusest järjestusmudelite paar sisestatakse mudelisse ja genereeritakse ennustatud sõnad. Pärast seda vaatate õige indeksi leidmiseks iga väljundi suurimat väärtust. Ja lõpuks võrdlete, et näha meie mudeli ennustust tõese lausega
def evaluate(model, input_lang, output_lang, sentences, max_length=MAX_LENGTH):
with torch.no_grad():
input_tensor = tensorFromSentence(input_lang, sentences[0])
output_tensor = tensorFromSentence(output_lang, sentences[1])
decoded_words = []
output = model(input_tensor, output_tensor)
# print(output_tensor)
for ot in range(output.size(0)):
topv, topi = output[ot].topk(1)
# print(topi)
if topi[0].item() == EOS_token:
decoded_words.append('<EOS>')
break
else:
decoded_words.append(output_lang.index2word[topi[0].item()])
return decoded_words
def evaluateRandomly(model, source, target, pairs, n=10):
for i in range(n):
pair = random.choice(pairs)
print(‘source {}’.format(pair[0]))
print(‘target {}’.format(pair[1]))
output_words = evaluate(model, source, target, pair)
output_sentence = ' '.join(output_words)
print(‘predicted {}’.format(output_sentence))
Nüüd alustame oma koolitust Seq to Seq-iga, iteratsioonide arvuga 75000 ja RNN-i kihi arvuga 1 peidetud suurusega 512.
lang1 = 'eng'
lang2 = 'ind'
source, target, pairs = process_data(lang1, lang2)
randomize = random.choice(pairs)
print('random sentence {}'.format(randomize))
#print number of words
input_size = source.n_words
output_size = target.n_words
print('Input : {} Output : {}'.format(input_size, output_size))
embed_size = 256
hidden_size = 512
num_layers = 1
num_iteration = 100000
#create encoder-decoder model
encoder = Encoder(input_size, hidden_size, embed_size, num_layers)
decoder = Decoder(output_size, hidden_size, embed_size, num_layers)
model = Seq2Seq(encoder, decoder, device).to(device)
#print model
print(encoder)
print(decoder)
model = trainModel(model, source, target, pairs, num_iteration)
evaluateRandomly(model, source, target, pairs)
Nagu näete, ei sobi meie ennustatud lause eriti hästi, nii et suurema täpsuse saavutamiseks peate treenima palju rohkemate andmetega ning proovima lisada järjestusõppe abil rohkem iteratsioone ja kihtide arvu.
random sentence ['tom is finishing his work', 'tom sedang menyelesaikan pekerjaannya']
Input : 3551 Output : 4253
Encoder(
(embedding): Embedding(3551, 256)
(gru): GRU(256, 512)
)
Decoder(
(embedding): Embedding(4253, 256)
(gru): GRU(256, 512)
(out): Linear(in_features=512, out_features=4253, bias=True)
(softmax): LogSoftmax()
)
Seq2Seq(
(encoder): Encoder(
(embedding): Embedding(3551, 256)
(gru): GRU(256, 512)
)
(decoder): Decoder(
(embedding): Embedding(4253, 256)
(gru): GRU(256, 512)
(out): Linear(in_features=512, out_features=4253, bias=True)
(softmax): LogSoftmax()
)
)
5000 4.0906
10000 3.9129
15000 3.8171
20000 3.8369
25000 3.8199
30000 3.7957
35000 3.8037
40000 3.8098
45000 3.7530
50000 3.7119
55000 3.7263
60000 3.6933
65000 3.6840
70000 3.7058
75000 3.7044
> this is worth one million yen
= ini senilai satu juta yen
< tom sangat satu juta yen <EOS>
> she got good grades in english
= dia mendapatkan nilai bagus dalam bahasa inggris
< tom meminta nilai bagus dalam bahasa inggris <EOS>
> put in a little more sugar
= tambahkan sedikit gula
< tom tidak <EOS>
> are you a japanese student
= apakah kamu siswa dari jepang
< tom kamu memiliki yang jepang <EOS>
> i apologize for having to leave
= saya meminta maaf karena harus pergi
< tom tidak maaf karena harus pergi ke
> he isnt here is he
= dia tidak ada di sini kan
< tom tidak <EOS>
> speaking about trips have you ever been to kobe
= berbicara tentang wisata apa kau pernah ke kobe
< tom tidak <EOS>
> tom bought me roses
= tom membelikanku bunga mawar
< tom tidak bunga mawar <EOS>
> no one was more surprised than tom
= tidak ada seorangpun yang lebih terkejut dari tom
< tom ada orang yang lebih terkejut <EOS>
> i thought it was true
= aku kira itu benar adanya
< tom tidak <EOS>