PyTorch oktatóanyag
Pytorch oktatóanyag összefoglalója
Ebben a pytorch oktatóanyagban az összes fogalmat a semmiből tanulja meg. Ez az oktatóanyag az alapvető és haladó témákat tárgyalja, mint például a pytorch meghatározása, a pytorch előnyei és hátrányai, összehasonlítás, telepítés, pytorch keretrendszer, regresszió és képosztályozás. Ez a pytorch oktatóanyag teljesen ingyenes.
Mi az a PyTorh?
PyTorch egy nyílt forrású Torch alapú gépi tanulási könyvtár természetes nyelvi feldolgozáshoz PythonHasonló a NumPy-hoz, de erős GPU-támogatással. Dinamikus számítási grafikonokat kínál, amelyeket útközben is módosíthatsz az autograd segítségével. PyTorA ch gyorsabb is, mint néhány más keretrendszer. A Facebook AI Research Groupja fejlesztette ki 2016-ban.
PyTorElőnyök és hátrányok
A következők a Py előnyei és hátrányaiTorch:
A Py előnyeiTorch
- Egyszerű könyvtár
PyTorA ch kód egyszerű. Könnyen érthető, és a könyvtárat azonnal használhatod. Például nézd meg az alábbi kódrészletet:
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.layer = torch.nn.Linear(1, 1)
def forward(self, x):
x = self.layer(x)
return x
Mint fentebb említettük, könnyen meghatározhatja a hálózati modellt, és gyorsan megértheti a kódot, különösebb képzés nélkül.
- Dinamikus számítási grafikon

Kép forrása: A mély tanulás felfedezése Py segítségévelTorch
A Pytorch a Dynamic Computational Graph (DAG) szolgáltatást kínálja. A számítási gráfok matematikai kifejezések gráfmodellekben vagy elméletekben, például csomópontokban és élekben való kifejezésének egyik módja. A csomópont elvégzi a matematikai műveletet, az él pedig egy tenzor, amely a csomópontokba kerül, és a csomópont kimenetét Tenzorban hordozza.
A DAG egy tetszőleges alakú gráf, amely képes műveleteket végrehajtani a különböző bemeneti gráfok között. Minden iteráció során új gráf jön létre. Tehát lehetséges ugyanaz a gráfstruktúra, vagy új gráf létrehozása más művelettel, vagy nevezhetjük dinamikus gráfnak.
- Jobb teljesítmény
A közösségek és kutatók összehasonlítják és összehasonlítják a keretrendszereket, hogy megtudják, melyik a gyorsabb. GitHub repo Összehasonlítás a Deep Learning Frameworks és GPU-k terén arról számolt be, hogy PyTorA ch gyorsabb, mint a másik keretrendszer a másodpercenként feldolgozott képek számát tekintve.
Amint az alábbiakban látható, az összehasonlító grafikonok a vgg16-tal és a resnet152-vel


- Bennszülött Python
PyTorA ch inkább Python alapú. Például, ha egy modellt szeretnél betanítani, használhatsz natív vezérlőfolyamatot, mint például a loo.ping és rekurziókat anélkül, hogy további speciális változókat vagy munkameneteket kellene hozzáadni a futtatásukhoz. Ez nagyon hasznos a betanítási folyamat szempontjából.
A Pytorch az Imperative Programming-ot is megvalósítja, és határozottan rugalmasabb. Tehát lehetséges a tenzorérték kinyomtatása a számítási folyamat közepén.
Py hátrányaTorch
PyTorA ch külső fejlesztésű alkalmazásokat igényel a vizualizációhoz. Éles környezethez API-kiszolgálóra is szükség van.
Következő ebben a Py-benTorch oktatóanyagban megismerkedünk a Py közötti különbséggelTorch és TensorFlow.
PyTorch vs. Tensorflow
| Vizsgált paraméter | PyTorch | tenzor áramlás |
|---|---|---|
| Modell meghatározása | A modell egy alosztályban van meghatározva, és könnyen használható csomagot kínál | A modell sokakkal van meghatározva, és meg kell értened a szintaxist |
| GPU támogatás | Igen | Igen |
| Grafikon típusa | Dinamikus | Statikus |
| Eszközök | Nincs vizualizációs eszköz | Használhatja a Tensorboard vizualizációs eszközt |
| Közösség | A közösség még mindig növekszik | Nagy, aktív közösségek |
Py telepítéseTorch
Linux
Egyszerűen telepíthető Linuxra. Dönthet úgy, hogy virtuális környezetet használ, vagy közvetlenül telepíti root hozzáféréssel. Írja be ezt a parancsot a terminálba
pip3 install --upgrade torch torchvision
AWS Sagemaker
A Sagemaker az egyik platform Amazon Webes szolgáltatás amely egy erőteljes gépi tanulási motort kínál előre telepített mély tanulási konfigurációkkal az adattudósok vagy fejlesztők számára, hogy bármilyen léptékű modelleket építhessenek, taníthassanak és telepíthessenek.
Először nyissa meg a Amazon Sagemaker konzolra, kattintson a Jegyzetfüzetpéldány létrehozása elemre, és adja meg a jegyzetfüzet összes adatát.

A következő lépésben kattintson a Megnyitás gombra a notebook példány elindításához.

Végül In Jupyter, Kattintson az Új elemre, és válassza a conda_pytorch_p36 lehetőséget, és máris használhatja notebook példányát a Pytorch telepítésével.
Következő ebben a Py-benTorch bemutató, Py-ról fogunk tanulniTorch keretrendszer alapjai.
PyTorch keretrendszer alapjai
Tanuljuk meg a Py alapfogalmaitTormielőtt mélyebben belemerülnénk. PyTorA ch függvény minden változóhoz Tenzort használ, hasonlóan a numpy ndarray függvényéhez, de GPU-számítási támogatással. Itt bemutatjuk a hálózati modellt, a veszteségfüggvényt, a Backprop-ot és az optimalizálót.
Hálózati modell
A hálózat a fáklya.nn alosztályozásával építhető fel. 2 fő része van,
- Az első rész a paraméterek és fóliák meghatározása, amelyeket használni fog
- A második rész a fő feladat, az úgynevezett továbbítási folyamat, amely bemenetet vesz és megjósolja a kimenetet.
Import torch
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv1 = nn.Conv2d(3, 20, 5)
self.conv2 = nn.Conv2d(20, 40, 5)
self.fc1 = nn.Linear(320, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
return F.log_softmax(x)
net = Model()
Mint fentebb látható, létrehoz egy nn.Module osztályt Modell néven. 2 Conv2d réteget és egy Lineáris réteget tartalmaz. Az első conv2d réteg bemeneti értéke 3, a kimeneti alakja pedig 20. A második réteg 20-as bemeneti értéket vesz fel, és 40-es kimeneti formát hoz létre. Az utolsó réteg egy teljesen összekapcsolt, 320-as formájú réteg. 10-es kimenet.
A továbbítási folyamat az X bemenetét veszi, és továbbítja a conv1 réteghez, és végrehajtja a ReLU funkciót,
Hasonlóképpen a conv2 réteget is táplálja. Ezt követően az x átformálódik (-1, 320)-ra, és bekerül az utolsó FC rétegbe. A kimenet elküldése előtt használja a softmax aktiválási funkciót.
A visszafelé irányuló folyamatot az autograd automatikusan definiálja, így csak a továbbító folyamatot kell meghatároznia.
Veszteség funkció
A veszteségfüggvényt arra használjuk, hogy megmérjük, mennyire képes az előrejelzési modell megjósolni a várható eredményeket. PyTorA ch már számos szabványos veszteségfüggvényt tartalmaz a torch.nn modulban. Például a Cross-Entropy Loss függvényt használhatod egy többosztályos Py megoldására.Torch osztályozási probléma. Könnyű definiálni a veszteségfüggvényt és kiszámítani a veszteségeket:
loss_fn = nn.CrossEntropyLoss() #training process loss = loss_fn(out, target)
Könnyű saját veszteségfüggvényt számolni Py-valTorch.
Backprop
A visszaterjesztés végrehajtásához egyszerűen hívja meg a los.backward() parancsot. A hiba kiszámításra kerül, de ne felejtse el törölni a meglévő gradienst a zero_grad() paranccsal
net.zero_grad() # to clear the existing gradient loss.backward() # to perform backpropragation
Optimizer
A torch.optim általános optimalizálási algoritmusokat biztosít. Egy optimalizálót egy egyszerű lépéssel határozhat meg:
optimizer = torch.optim.SGD(net.parameters(), lr = 0.01, momentum=0.9)
Átadnia kell a hálózati modell paramétereit és a tanulási sebességet, hogy a paraméterek minden iterációnál frissüljenek a backprop folyamat után.
Egyszerű regresszió Py-valTorch
Tanuljunk egyszerű regressziót Py-valTorch példák:
1. lépés) Hálózati modellünk létrehozása
Hálózati modellünk egy egyszerű Lineáris réteg, amelynek bemeneti és kimeneti alakja 1.
from __future__ import print_function
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.layer = torch.nn.Linear(1, 1)
def forward(self, x):
x = self.layer(x)
return x
net = Net()
print(net)
És a hálózati kimenetnek ilyennek kell lennie
Net( (hidden): Linear(in_features=1, out_features=1, bias=True) )
2. lépés) Tesztadatok
Mielőtt elkezdené a képzési folyamatot, ismernie kell adatainkat. Véletlenszerű függvényt készít a modellünk teszteléséhez. Y = x3 sin(x)+ 3x+0.8 rand(100)
# Visualize our data import matplotlib.pyplot as plt import numpy as np x = np.random.rand(100) y = np.sin(x) * np.power(x,3) + 3*x + np.random.rand(100)*0.8 plt.scatter(x, y) plt.show()
Íme a függvényünk szórásdiagramja:

A betanítási folyamat megkezdése előtt a numpy tömböt olyan változókká kell konvertálni, amelyeket a Torch és autograd, ahogy az az alábbi Py ábrán láthatóTorch regressziós példa.
# convert numpy array to tensor in shape of input size x = torch.from_numpy(x.reshape(-1,1)).float() y = torch.from_numpy(y.reshape(-1,1)).float() print(x, y)
3. lépés) Optimalizálás és veszteség
Ezután meg kell határoznia az optimalizálót és a veszteségfüggvényt a képzési folyamatunkhoz.
# Define Optimizer and Loss Function optimizer = torch.optim.SGD(net.parameters(), lr=0.2) loss_func = torch.nn.MSELoss()
4. lépés) Képzés
Most kezdjük el a képzési folyamatunkat. A 250-es korszakban ismételni fogja adatainkat, hogy megtalálja a legjobb értéket hiperparamétereink számára.
inputs = Variable(x)
outputs = Variable(y)
for i in range(250):
prediction = net(inputs)
loss = loss_func(prediction, outputs)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i % 10 == 0:
# plot and show learning process
plt.cla()
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=2)
plt.text(0.5, 0, 'Loss=%.4f' % loss.data.numpy(), fontdict={'size': 10, 'color': 'red'})
plt.pause(0.1)
plt.show()
5. lépés) Eredmény
Amint az alább látható, sikeresen végrehajtottad a Py-tTorch regresszió neurális hálózattal. Valójában minden iterációnál a grafikonon lévő piros vonal frissül és megváltoztatja a pozícióját, hogy illeszkedjen az adatokhoz. De ezen a képen csak a végeredményt mutatja, ahogy az az alábbi Py egyenletben látható.Torch példa:

Képosztályozási példa Py-valTorch
Az egyik népszerű módszer az alapok elsajátítására mély tanulás az MNIST adatkészlettel van. Ez a „Hello World” a mély tanulásban. Az adatkészlet kézzel írt számokat tartalmaz 0-tól 9-ig, összesen 60,000 10,000 oktatási mintával és 28 28 tesztmintával, amelyek már XNUMX × XNUMX pixel méretűek.

1. lépés) Az adatok előfeldolgozása
A Py első lépésébenTorA ch osztályozási példában a torchvision modullal fogod betölteni az adathalmazt.
Mielőtt elkezdenéd a képzési folyamatot, meg kell értened az adatokat. TorA chvision betölti az adatkészletet, és átalakítja a képeket a hálózat megfelelő követelményeinek megfelelően, például az alaknak és a képek normalizálásának megfelelően.
import torch
import torchvision
import numpy as np
from torchvision import datasets, models, transforms
# This is used to transform the images to Tensor and normalize it
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
training = torchvision.datasets.MNIST(root='./data', train=True,
download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(training, batch_size=4,
shuffle=True, num_workers=2)
testing = torchvision.datasets.MNIST(root='./data', train=False,
download=True, transform=transform)
test_loader = torch.utils.data.DataLoader(testing, batch_size=4,
shuffle=False, num_workers=2)
classes = ('0', '1', '2', '3',
'4', '5', '6', '7', '8', '9')
import matplotlib.pyplot as plt
import numpy as np
#create an iterator for train_loader
# get random training images
data_iterator = iter(train_loader)
images, labels = data_iterator.next()
#plot 4 images to visualize the data
rows = 2
columns = 2
fig=plt.figure()
for i in range(4):
fig.add_subplot(rows, columns, i+1)
plt.title(classes[labels[i]])
img = images[i] / 2 + 0.5 # this is for unnormalize the image
img = torchvision.transforms.ToPILImage()(img)
plt.imshow(img)
plt.show()
A transzformációs függvény tenzorrá alakítja a képeket és normalizálja az értéket. A torchvision.transforms.MNIST függvény letölti az adatkészletet (ha nem elérhető) a könyvtárból, szükség esetén beállítja az adatkészletet betanításra, és elvégzi az átalakítási folyamatot.
Az adatkészlet megjelenítéséhez használja a data_iteratort a következő képek és címkék kötegének lekéréséhez. Matplotot használ a képek és a megfelelő címkék ábrázolásához. Amint az alábbi képeinken és azok címkéin látható.
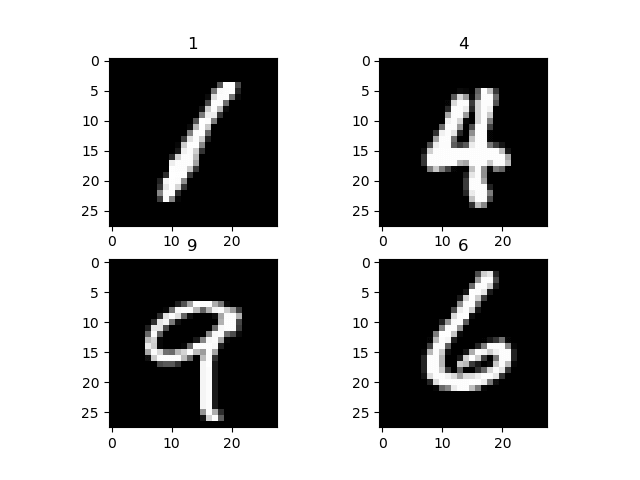
2. lépés: Hálózati modell konfigurálása
Most ebben a Py-banTorPéldában egy egyszerű Py neurális hálózatot fogsz készíteni.Torch képosztályozás.
Itt bemutatunk egy másik módszert a hálózati modell létrehozására Py-ban.Torch. Az nn.Sequential függvényt fogjuk használni egy szekvencia modell létrehozásához ahelyett, hogy az nn.Module alosztályát hoznánk létre.
import torch.nn as nn
# flatten the tensor into
class Flatten(nn.Module):
def forward(self, input):
return input.view(input.size(0), -1)
#sequential based model
seq_model = nn.Sequential(
nn.Conv2d(1, 10, kernel_size=5),
nn.MaxPool2d(2),
nn.ReLU(),
nn.Dropout2d(),
nn.Conv2d(10, 20, kernel_size=5),
nn.MaxPool2d(2),
nn.ReLU(),
Flatten(),
nn.Linear(320, 50),
nn.ReLU(),
nn.Linear(50, 10),
nn.Softmax(),
)
net = seq_model
print(net)
Íme a hálózati modellünk kimenete
Sequential( (0): Conv2d(1, 10, kernel_size=(5, 5), stride=(1, 1)) (1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (2): ReLU() (3): Dropout2d(p=0.5) (4): Conv2d(10, 20, kernel_size=(5, 5), stride=(1, 1)) (5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (6): ReLU() (7): Flatten() (8): Linear(in_features=320, out_features=50, bias=True) (9): ReLU() (10): Linear(in_features=50, out_features=10, bias=True) (11): Softmax() )
Hálózati magyarázat
- A sorrend az, hogy az első réteg egy Conv2D réteg, amelynek bemeneti alakja 1 és kimeneti alakja 10, kernelmérete 5
- Ezután van egy MaxPool2D rétege
- Egy ReLU aktiválási funkció
- a Dropout réteg az alacsony valószínűségű értékek eldobásához.
- Ezután egy második Conv2d 10-es bemeneti alakkal az utolsó rétegből és 20-as kimeneti alakzattal 5-ös kernelmérettel
- Ezután egy MaxPool2d réteg
- ReLU aktiválási funkció.
- Ezt követően a tenzort le kell simítani, mielőtt betáplálná a Lineáris rétegbe
- A Linear Layer leképezi a kimenetünket a második Lineáris rétegre a softmax aktiválási funkcióval
3. lépés: Tanítsa meg a modellt
A képzési folyamat megkezdése előtt be kell állítani a kritériumot és az optimalizáló funkciót.
A kritériumhoz a CrossEntropyLoss-t fogod használni. Az optimalizálóhoz az SGD-t fogod használni 0.001 tanulási rátával és 0.9 momentummal, ahogy az az alábbi Py ábrán látható.Torch példa.
import torch.optim as optim criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
A továbbítási folyamat felveszi a bemeneti alakot, és átadja az első conv2d rétegnek. Ezután a maxpool2d-be kerül betáplálásra, végül pedig a ReLU aktiválási funkciójába. Ugyanez a folyamat megy végbe a második conv2d rétegben is. Ezt követően a bemenet átformálódik (-1,320) értékre, és betáplálódik az fc rétegbe a kimenet előrejelzéséhez.
Most elkezdheti a képzési folyamatot. 2-szer vagy 2-es periódussal át fogja ismételni az adatkészletünket, és minden 2000-es tételnél kinyomtatja az aktuális veszteséget.
for epoch in range(2):
#set the running loss at each epoch to zero
running_loss = 0.0
# we will enumerate the train loader with starting index of 0
# for each iteration (i) and the data (tuple of input and labels)
for i, data in enumerate(train_loader, 0):
inputs, labels = data
# clear the gradient
optimizer.zero_grad()
#feed the input and acquire the output from network
outputs = net(inputs)
#calculating the predicted and the expected loss
loss = criterion(outputs, labels)
#compute the gradient
loss.backward()
#update the parameters
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 1000 == 0:
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 1000))
running_loss = 0.0
Minden korszakban a felsoroló megkapja a következő bemeneti sort és a megfelelő címkéket. Mielőtt betápláljuk a bemenetet a hálózati modellünkbe, törölnünk kell az előző gradienst. Erre azért van szükség, mert a visszafelé irányuló folyamat (backpropagation process) után a gradiens felhalmozódik ahelyett, hogy lecserélné. Ezután kiszámítjuk a veszteségeket a várható kimenetből a várható kimenetből. Ezt követően visszaszaporítást végzünk a gradiens kiszámításához, végül frissítjük a paramétereket.
Íme az edzési folyamat eredménye
[1, 1] loss: 0.002 [1, 1001] loss: 2.302 [1, 2001] loss: 2.295 [1, 3001] loss: 2.204 [1, 4001] loss: 1.930 [1, 5001] loss: 1.791 [1, 6001] loss: 1.756 [1, 7001] loss: 1.744 [1, 8001] loss: 1.696 [1, 9001] loss: 1.650 [1, 10001] loss: 1.640 [1, 11001] loss: 1.631 [1, 12001] loss: 1.631 [1, 13001] loss: 1.624 [1, 14001] loss: 1.616 [2, 1] loss: 0.001 [2, 1001] loss: 1.604 [2, 2001] loss: 1.607 [2, 3001] loss: 1.602 [2, 4001] loss: 1.596 [2, 5001] loss: 1.608 [2, 6001] loss: 1.589 [2, 7001] loss: 1.610 [2, 8001] loss: 1.596 [2, 9001] loss: 1.598 [2, 10001] loss: 1.603 [2, 11001] loss: 1.596 [2, 12001] loss: 1.587 [2, 13001] loss: 1.596 [2, 14001] loss: 1.603
4. lépés) Tesztelje a modellt
Miután betanította modellünket, tesztelnie kell vagy értékelnie kell más képkészletekkel.
A test_loaderhez egy iterátort fogunk használni, amely képeket és címkéket állít elő, amelyeket átad a betanított modellnek. Megjelenik a várható kimenet, és összehasonlítja a várt kimenettel.
#make an iterator from test_loader
#Get a batch of training images
test_iterator = iter(test_loader)
images, labels = test_iterator.next()
results = net(images)
_, predicted = torch.max(results, 1)
print('Predicted: ', ' '.join('%5s' % classes[predicted[j]] for j in range(4)))
fig2 = plt.figure()
for i in range(4):
fig2.add_subplot(rows, columns, i+1)
plt.title('truth ' + classes[labels[i]] + ': predict ' + classes[predicted[i]])
img = images[i] / 2 + 0.5 # this is to unnormalize the image
img = torchvision.transforms.ToPILImage()(img)
plt.imshow(img)
plt.show()

Összegzésként
- PyTorA ch egy nyílt forráskódú Torch alapú Gépi tanulás könyvtár számára természetes nyelvfeldolgozás segítségével Python.
- A Py előnyeiTorch: 1) Egyszerű könyvtár, 2) Dinamikus számítási gráf, 3) Jobb teljesítmény, 4) Natív Python
- PyTorA ch függvény minden változóhoz Tenzort használ, hasonlóan a numpy ndarray függvényéhez, de GPU számítási támogatással.
- A mély tanulás alapjainak elsajátításának egyik népszerű módszere az MNIST adatkészlet.