ETL テストのチュートリアル
⚡ スマートサマリー
ETLテストは、データがソースシステムから変換ロジックを経てターゲットデータウェアハウスにどのように流れるかを検証し、正確性、完全性、信頼性を確認します。この資料では、プロセス段階、テストの種類、一般的なバグの種類、自動化手法、そして初心者から中級者までのテスターが必要とする実践的なベストプラクティスについて解説します。

ETLとは何ですか?
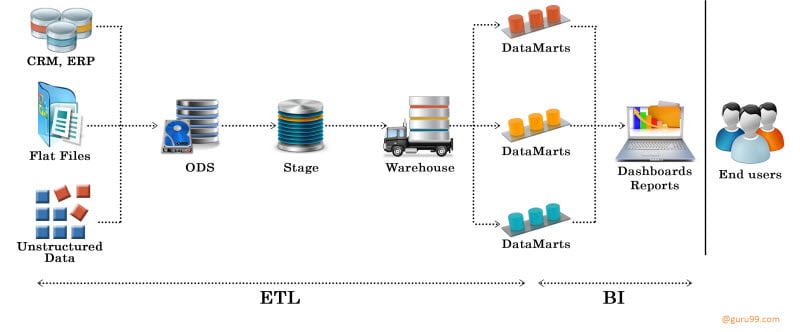
ETL の略 Extract-Transform-Load、そして、データがソースシステムからデータウェアハウスにどのように移動するかを説明します。データは、tracOLTPデータベースから取得されたデータは、データウェアハウスのスキーマに合わせて変換され、ウェアハウスデータベースにロードされます。多くのウェアハウスは、テキストファイル、レガシーアプリケーション、スプレッドシートなど、OLTP以外のシステムからのデータも取り込んでいます。
例えば、小売店には販売、マーケティング、物流といった部門が分かれている場合があります。各部門は顧客情報を独立して扱い、データの保存方法もそれぞれ異なります。販売部門は顧客名で記録を保存するかもしれませんが、マーケティング部門は顧客IDを使用するかもしれません。
ビジネスチームがさまざまなマーケティングキャンペーンにわたる顧客の購入履歴全体をレビューしたい場合、データが分断されているため、非常に面倒です。解決策は、 データウェアハウス ETL(抽出、変換、ロード)を使用して、異なるソースからの情報を統一された構造に格納します。ETLは、異なるデータセットを統一された構造に変換できるため、BIツールは後で有意義な洞察やレポートを導き出すことができます。
次の図は、ETLテストのプロセスフローと、このガイド全体を通して使用する主要な概念を示しています。
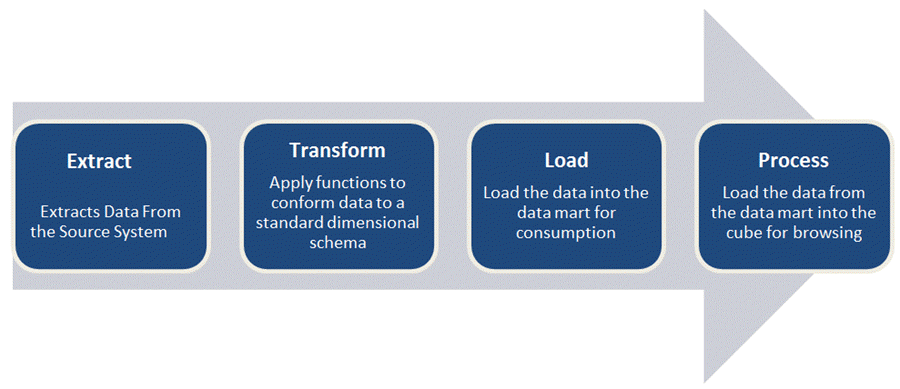
1) 例tract
- Extrac1つ以上のソースシステムからの関連データ。
2) 変換
- データをDW(データウェアハウス)形式に変換する。
- キーの構築:キーとは、エンティティを一意に識別する1つ以上のデータ属性のことです。 キーの種類 主キー、代替キー、外部キー、複合キー、および代理キーは、データウェアハウスが所有し、他のエンティティがこれらのキーを割り当てることを決して許可しません。
- データクレンジング:データが抽出された後trac処理が完了すると、次の段階であるクリーニングとコンフォーミングに進みます。クリーニングでは、データの欠落を修正し、エラーを特定します。コンフォーミングでは、互換性のないデータセット間の競合を解消し、エンタープライズデータウェアハウスで使用できるようにします。また、ソースシステムの問題を診断し、データ品質を向上させるためのメタデータも作成します。
3) ロード
- データウェアハウス(DW)にデータをロードする。
- 集約の構築: 集約は、データからデータを要約して保存します。 ファクトテーブル エンドユーザーからのクエリのパフォーマンスを向上させるため。
ETLテストとは何ですか?
ETLテストは、ビジネス変換後にソースから宛先にロードされたデータが正確であることを保証するために実行されます。また、ソースと宛先の間のさまざまな中間段階でのデータの検証も含まれます。ETLはExの略です。tract-Transform-Load、ETLテストは、これら3つの段階と、データがそれらの間を行き来するポイントをそれぞれ網羅します。
ETLテストが重要な理由とは?
ETLテストとは何かを理解したら、次に疑問に思うのは、なぜ組織がこれほど多くの労力をETLテストに費やすのかということです。ビジネス上の意思決定は、正確で完全かつ信頼できるデータに基づいて行われるため、たった1つの変換エラーが、財務報告、顧客分析、規制開示などにまで影響を及ぼす可能性があるのです。
以下の点が、強力なETLテストの実践的な価値を説明しています。
- データの精度: これは、ビジネスルールによって変換された値が文書化されたマップと一致することを確認するものです。ping 仕様を定め、静かなる不正行為を防ぐ。
- 信頼できる報道: ダッシュボードやBIツールはデータウェアハウスに依存するため、検証済みのETLパイプラインによって、下流のすべてのレポートとKPIが保護されます。
- 企業コンプライアンス: 銀行、医療、保険などの業界では、データの来歴と完全性がエンドツーエンドで維持されていることを証明する必要がある。
- やり直しの削減: 下位環境で欠陥を検出することで、コストのかかる本番環境の再ロード、手動による照合、および顧客対応上のエラーを回避できます。
- パフォーマンス保証: ETLテストでは、負荷ウィンドウ、スループット、ボトルネックを測定することで、データ量の増加に合わせてデータウェアハウスが継続的に拡張できるようにします。
こうした動機が明確になったところで、次のセクションでは、ETLテスターが実際のプロジェクトで従う構造化されたプロセスについて説明します。
ETL テストプロセス
他のテストプロセスと同様に、ETLも複数のフェーズを経て進行します。ETLテストプロセスの各フェーズは以下のとおりです。
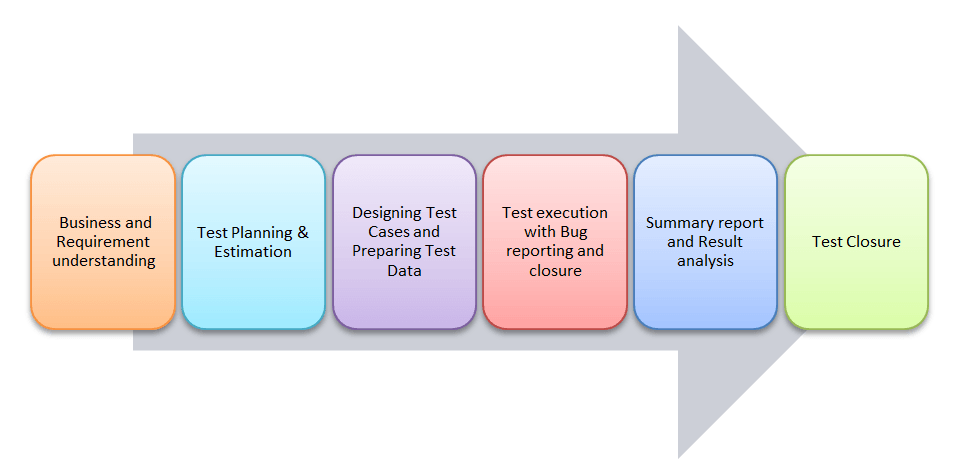
ETLテストは5つの段階で実施されます。
- データソースと要件の特定
- データ収集
- ビジネスロジックとディメンションモデリングを実装する
- データの構築と入力
- レポートの作成

大まかなプロセスを念頭に置きながら、このライフサイクルに含まれる具体的なテストの種類を見ていきましょう。
ETL テストの種類
- 製造検証テスト
テストプロセス: 「テーブルバランス調整」または「本番環境調整」とも呼ばれるこのタイプのETLテストは、データが本番システムに取り込まれる際に実行されます。ビジネス上の意思決定を支援するためには、本番データは正しい順序でなければなりません。 情報 データ検証オプションは、ETLテストの自動化および管理機能を提供し、本番システムが不良データによって損なわれることを防ぎます。 - ソース Target テスト(検証テスト)
テストプロセス: この種のテストは、変換されたデータ値が期待される目標値と一致するかどうかを検証します。 - 用途 Upgrades
テストプロセス: このタイプのETLテストは自動生成できるため、テスト開発時間を大幅に節約できます。データ抽出が適切に行われているかを確認します。trac古いアプリケーションまたはリポジトリから取得したデータが、新しいアプリケーションまたはリポジトリのデータと一致します。 - メタデータのテスト
テストプロセス: メタデータのテストには、データ型チェック、データ長チェック、インデックスまたは制約チェックが含まれます。 - データ完全性テスト
テストプロセス: データ完全性テストでは、想定されるすべてのデータがソースからターゲットにロードされていることを確認します。一般的なテストとしては、変換が単純な場合や変換が行われていない場合に、ソース列とターゲット列の間でレコード数、集計値、および実際のデータを比較して検証することが挙げられます。 - データ精度テスト
テストプロセス: このテストにより、データが正確にロードされ、想定どおりに変換されることが保証されます。 - データ変換テスト
テストプロセス: テストデータの変換は、単一のソースでは実現できない場合が多い。 SQL クエリと出力の比較。変換ルールを検証するために、各行に対して複数のSQLクエリが必要になる場合があります。 - データ品質テスト
テストプロセス:データ品質テストには、構文テストと参照テストが含まれます。これらは、日付や注文番号の誤りによって引き起こされる業務プロセスのエラーを防ぎます。
構文テストは、無効な文字、文字パターン、大文字または小文字の順序の誤りに基づいて、不正確なデータを報告します。
参照テストは、データモデルに対してデータを検証します。例:顧客ID。
データ品質テストには、数値チェック、日付チェック、精度チェック、データチェック、およびヌルチェックも含まれます。
- 増分ETLテスト
テストプロセス: このテストでは、既存データと新規データに加えられた新規データのデータ整合性を確認します。増分テストでは、増分ETLプロセス中に挿入と更新が想定どおりに処理されることを検証します。 - GUI/ナビゲーションのテスト
テストプロセス: このテストでは、フロントエンドレポートのナビゲーションとGUIに関する側面を確認します。
ETL テスト ケースの作成方法
ETLテストは、情報管理業界におけるさまざまなツールやデータベースに適用できる概念です。 ETLテストの目的は、ビジネス変換後にソースから宛先にロードされたデータが正確であることを保証することです。 また、データ送信元と送信先の間の様々な中間段階におけるデータの検証も含まれる。
ETLテストを実行する際、ETLテスターは常に2つのドキュメントを使用します。
- ETLマップping シート: ETLマップping シートには、ソーステーブルと宛先テーブルのすべての情報が含まれており、各列とその参照テーブルでのルックアップも含まれています。ETLテストでは、あらゆる段階でデータを検証するために複数の結合を含む大規模なクエリを作成する必要があるため、ETLテスターはSQLクエリに精通している必要があります。ETLマップping データ検証のためのクエリを作成する際に、シートは非常に役立ちます。
- ソースとターゲットのDBスキーマ: 地図の詳細を確認するために手元に置いておくべきですping シート。
ETL テスト シナリオとテスト ケース
- 地図ping ドキュメント検証
テストケース: マップに該当するETL情報が提供されているか確認してください。ping ドキュメント。すべてのマップで変更ログを維持する必要があります。ping doc。 - 検証
テストケース:1) ソーステーブルとターゲットテーブルの構造を対応するマップと照合して検証するping doc。
2) ソースデータ型とターゲットデータ型は同じである必要があります。
3) ソースとターゲットの両方で、データ型の長さは同じである必要があります。
4) データフィールドの型と形式が指定されていることを確認します。
5) ソースデータ型の長さは、ターゲットデータ型の長さより短くあってはならない。
6) テーブル内の列名をマップと照合して検証するping doc。 - 制約の検証
テストケース: 特定のテーブルに対して、想定どおりに制約が定義されていることを確認してください。 - データの一貫性の問題
テストケース:1) 特定の属性のデータ型と長さは、意味的な定義が同じであっても、ファイルやテーブルによって異なる場合があります。
2) 整合性制約の誤用。 - 完全性の問題
テストケース:1) 想定されるすべてのデータがターゲットテーブルにロードされていることを確認します。
2) ソースとターゲットのレコード数を比較します。
3) 拒否されたレコードがないか確認する。
4) 対象テーブルの列でデータが切り捨てられていないことを確認します。
5)境界値解析を確認する。
6) データウェアハウスにロードされたデータとソースデータの間で、キーフィールドの一意の値を比較します。 - 正確性の問題
テストケース:1) スペルミスや不正確な記録のあるデータ。
2) ヌル値、一意でない値、または範囲外のデータ。 - 変換
テストケース: マップ内のすべてのビジネスルールと変換ロジックを検証しますping 文書は、ターゲットに到達する前に、ソースデータに正しく適用されます。 - データ品質
テストケース:1) 数値チェック:数値の形式と値を検証します。
2) 日付チェック:日付は単一の形式に従い、すべての記録で一貫している必要があります。
3)精度チェック。
4) データチェック。
5) ヌルチェック。 - Null 検証
テストケース: 特定の列に対して「NULL不可」が指定されている場合、NULL値が正しく処理されているかを確認します。 - 重複チェック
テストケース:1) 重複行がないことを確認するために、一意キー、主キー、およびビジネス要件に従って一意であるべきその他の列を検証します。
2) いずれかの列に重複する値が存在するかどうかを確認します。trac複数のソース列から取得し、1つの列に結合しました。
3) クライアントの要件に従って、ターゲット内の複数の列の組み合わせに重複が存在しないことを確認してください。 - 日付の検証
テストケース: 日付値は、ETL開発の多くの分野で使用されます。1) 行の作成日を知るため。
2) ETL開発の観点から、アクティブなレコードを特定する。
3) ビジネス要件の観点から、アクティブなレコードを特定する。
4) 日付の値に基づいて、更新や挿入が生成される場合もあります。 - 完全なデータ検証
テストケース:1) 最良の解決策としてマイナスクエリを使用して、ソーステーブルとターゲットテーブルの完全なデータセットを検証します。
2) ソースからターゲットを引いて、ターゲットからソースを引く必要があります。
3) マイナスクエリが何らかの値を返した場合、それらの行は不一致とみなされるべきである。
4) 交差ステートメントを使用して、ソースとターゲットの行を照合します。
5) intersect 関数によって返されるカウントは、ソーステーブルとターゲットテーブルの個々のカウントと一致するはずです。
6) マイナスクエリが行を返し、交差する行数がソースまたはターゲットの行数より少ない場合、重複行が存在します。 - データのクリーンさ
テストケース: ステージング領域にロードする前に、不要な列を削除する必要があります。
ETL バグの種類
強力なテストケースを用意しても、ETLパイプラインはさまざまな形で失敗する可能性があります。下の図は、注意すべきバグのカテゴリをまとめたもので、続く表ではそれぞれについて説明しています。

| バグの種類 | 詳細説明 |
|---|---|
| ユーザーインターフェイスのバグ/外観上のバグ |
• アプリケーションのGUIに関連する ・フォントスタイル、フォントサイズ、色、配置、スペルミス、ナビゲーションなど |
| 境界値解析 (BVA) 関連のバグ | • 最小値と最大値 |
| 同値クラス分割 (ECP) 関連のバグ | • 有効な型と無効な型 |
| 入出力のバグ |
• 有効な値は受け入れられません • 無効な値が受け入れられました |
| 計算のバグ |
• 数学的な誤り • 最終出力が間違っている |
| ロード条件のバグ |
・複数ユーザーによる利用は許可されていません ・顧客が想定する負荷を許可しない |
| 競合状態のバグ |
・システムがクラッシュしてフリーズする • システムはクライアントプラットフォームを実行できません |
| バージョン管理のバグ |
• ロゴのマッチングなし • バージョン情報はありません ・通常は 回帰テスト |
| ハードウェアのバグ | • デバイスがアプリケーションに応答しない |
| ヘルプソースのバグ | • ヘルプドキュメントの間違い |
データウェアハウスのテスト
データウェアハウスのテスト データウェアハウステストは、データウェアハウス内のデータが企業のデータフレームワークに準拠しているかどうか、その整合性、信頼性、正確性、一貫性をテストする手法です。データウェアハウステストの主な目的は、ウェアハウス内の統合データが企業が意思決定を行うのに十分な信頼性を備えていることを確認することです。ETLテストはデータ移動に焦点を当てていますが、データウェアハウステストは、ETLが最終的にデータを供給する、より広範なストレージおよびレポートレイヤーを対象としています。
データベーステストとETLテストの違い
どちらの分野も構造化データを扱いますが、それぞれ異なる問いに答えます。以下の表は、その実際的な違いを明確に示しています。
| ETL テスト | データベースのテスト |
|---|---|
| データが想定どおりに移動されたかどうかを確認します。 | 主な目的は、データがデータモデルで定義されたルールと基準に従っているかどうかを確認することです。 |
| ソースとターゲットのカウントが一致しているか、変換されたデータが期待どおりであるかを確認します。 | 孤立レコードが存在しないこと、および外部主キー関係が維持されていることを確認します。 |
| ETL処理中に外部主キー関係が保持されていることを確認します。 | 冗長なテーブルが存在しないこと、およびデータベースが最適に正規化されていることを確認します。 |
| 読み込まれたデータに重複がないか確認します。 | 必要な列にデータが欠落していないかを確認します。 |
ETL でのパフォーマンス テスト
ETL でのパフォーマンス テスト ETL は、ETL システムが複数のユーザーとトランザクションの負荷を処理できることを保証するテスト手法です。ETL の主な目的は、 性能試験 セッションのパフォーマンスを最適化および改善するために、パフォーマンスのボトルネックを特定して排除します。ソースおよびターゲットデータベース、マップpings、セッション、そしてシステム自体すべてにボトルネックが存在する可能性があります。
パフォーマンス テストとチューニングに使用される最高のツールの 1 つは Informatica です。
ETL テスターの責任
ETLテスターの主な責任は、以下の3つのカテゴリに分類されます。
- ステージテーブル / SFS または MFS
- ビジネス変革ロジックの適用
- Target ステージファイルまたは変換適用後のテーブルからのテーブル読み込み
ETLテスターの日常業務には、以下のようなものがあります。
- ETL ソフトウェアをテストする
- ETLデータウェアハウスのテストコンポーネント
- バックエンドのデータ駆動型テストを実行する
- 作成、設計、実行 テストケーステスト計画、およびテストハーネス
- 問題点を特定し、潜在的な問題に対する解決策を提供する
- 要件と設計仕様の承認
- データ転送を検証し、フラットファイルをテストする
- カウントテストなどのさまざまなシナリオに対応するSQLクエリを作成します。
ETLテストの自動化
ETLテストの一般的な手法は、SQLスクリプトを使用するか、データを目視で確認することです。これらのアプローチは時間がかかり、エラーが発生しやすく、完全な結果が得られることはほとんどありません。 テストカバレッジ実行を加速し、カバレッジを向上させ、コストを削減し、 欠陥 本番環境および開発環境における検出と自動化は、まさに今求められている。Informaticaはそのようなツールの1つである。
現代のチームは、従来の自動化とAIを活用したヘルパーを組み合わせることで、変換テストの提案、合成ソースデータの生成、スキーマのずれの検出などを可能にし、テスターが反復的なスクリプトの保守ではなく、複雑なビジネスロジックに集中できるようにしている。
ETL テストのベスト プラクティス
- データが正しく変換されていることを確認してください。
- 予測データは、データの損失や切り捨てなしにデータウェアハウスにロードされるべきである。
- ETLアプリケーションが無効なデータを適切に拒否し、該当する場合はデフォルト値に置き換え、その旨を報告するようにしてください。
- 拡張性とパフォーマンスを検証するために、データが規定された想定時間内にデータウェアハウスにロードされていることを確認します。
- すべてのメソッドは、可視性に関わらず、適切な単体テストを持つべきである。
- 有効性を測定するためには、すべての単体テストで適切なカバレッジ手法を用いるべきである。
- テストケースごとに1つのアサーションを心がけてください。
- 創造する 単体テスト 例外を対象とする。
チェックアウト - ETL テストの面接の質問と回答