Seq2seq (ลำดับต่อลำดับ) โมเดลด้วย PyTorch
NLP คืออะไร
NLP หรือการประมวลผลภาษาธรรมชาติเป็นหนึ่งในสาขายอดนิยมของปัญญาประดิษฐ์ที่ช่วยให้คอมพิวเตอร์เข้าใจ จัดการ หรือตอบสนองต่อมนุษย์ในภาษาธรรมชาติของพวกเขา NLP คือเครื่องยนต์เบื้องหลัง Google Translate ที่ช่วยให้เราเข้าใจภาษาอื่นๆ
Seq2Seq คืออะไร?
Seq2Seq เป็นวิธีการแปลด้วยเครื่องโดยใช้ตัวเข้ารหัสและตัวถอดรหัสซึ่งแมปอินพุตของลำดับกับเอาต์พุตของลำดับด้วยแท็กและค่าความสนใจ แนวคิดคือการใช้ 2 RNN ที่จะทำงานร่วมกับโทเค็นพิเศษและพยายามทำนายลำดับสถานะถัดไปจากลำดับก่อนหน้า
วิธีทำนายลำดับจากลำดับก่อนหน้า
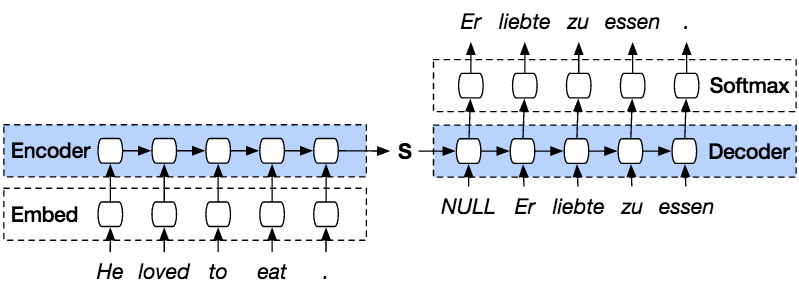
ต่อไปนี้เป็นขั้นตอนในการทำนายลำดับจากลำดับก่อนหน้าด้วย PyTorch
ขั้นตอนที่ 1) กำลังโหลดข้อมูลของเรา
สำหรับชุดข้อมูลของเรา คุณจะใช้ชุดข้อมูลจาก คู่ประโยคสองภาษาที่คั่นด้วยแท็บ- ที่นี่ฉันจะใช้ชุดข้อมูลภาษาอังกฤษเป็นภาษาอินโดนีเซีย คุณสามารถเลือกสิ่งที่คุณต้องการได้ แต่อย่าลืมเปลี่ยนชื่อไฟล์และไดเร็กทอรีในโค้ด
from __future__ import unicode_literals, print_function, division
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import numpy as np
import pandas as pd
import os
import re
import random
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
ขั้นตอนที่ 2) การเตรียมข้อมูล
คุณไม่สามารถใช้ชุดข้อมูลโดยตรง คุณต้องแยกประโยคออกเป็นคำและแปลงเป็น One-Hot Vector ทุกคำจะถูกจัดทำดัชนีไม่ซ้ำกันในคลาส Lang เพื่อสร้างพจนานุกรม Lang Class จะจัดเก็บทุกประโยคและแบ่งคำต่อคำด้วย addSentence จากนั้นสร้างพจนานุกรมโดยการจัดทำดัชนีทุกคำที่ไม่รู้จักสำหรับโมเดล Sequence to Sequence
SOS_token = 0
EOS_token = 1
MAX_LENGTH = 20
#initialize Lang Class
class Lang:
def __init__(self):
#initialize containers to hold the words and corresponding index
self.word2index = {}
self.word2count = {}
self.index2word = {0: "SOS", 1: "EOS"}
self.n_words = 2 # Count SOS and EOS
#split a sentence into words and add it to the container
def addSentence(self, sentence):
for word in sentence.split(' '):
self.addWord(word)
#If the word is not in the container, the word will be added to it,
#else, update the word counter
def addWord(self, word):
if word not in self.word2index:
self.word2index[word] = self.n_words
self.word2count[word] = 1
self.index2word[self.n_words] = word
self.n_words += 1
else:
self.word2count[word] += 1
Lang Class เป็นคลาสที่จะช่วยเราสร้างพจนานุกรม สำหรับแต่ละภาษา ทุกประโยคจะถูกแบ่งออกเป็นคำแล้วเพิ่มลงในคอนเทนเนอร์ แต่ละคอนเทนเนอร์จะเก็บคำไว้ในดัชนีที่เหมาะสม นับคำ และเพิ่มดัชนีของคำเพื่อให้เราสามารถใช้ค้นหาดัชนีของคำหรือค้นหาคำจากดัชนีของมันได้
เนื่องจากข้อมูลของเราถูกคั่นด้วย TAB คุณจึงจำเป็นต้องใช้ หมีแพนด้า เป็นตัวโหลดข้อมูลของเรา Pandas จะอ่านข้อมูลของเราในรูปแบบ dataFrame และแยกออกเป็นประโยคแหล่งที่มาและเป้าหมายของเรา สำหรับทุกประโยคที่คุณมี
- คุณจะทำให้ปกติเป็นตัวพิมพ์เล็ก
- ลบอักขระที่ไม่ใช่ทั้งหมด
- แปลงเป็น ASCII จาก Unicode
- แยกประโยคเพื่อให้คุณได้แต่ละคำในนั้น
#Normalize every sentence
def normalize_sentence(df, lang):
sentence = df[lang].str.lower()
sentence = sentence.str.replace('[^A-Za-z\s]+', '')
sentence = sentence.str.normalize('NFD')
sentence = sentence.str.encode('ascii', errors='ignore').str.decode('utf-8')
return sentence
def read_sentence(df, lang1, lang2):
sentence1 = normalize_sentence(df, lang1)
sentence2 = normalize_sentence(df, lang2)
return sentence1, sentence2
def read_file(loc, lang1, lang2):
df = pd.read_csv(loc, delimiter='\t', header=None, names=[lang1, lang2])
return df
def process_data(lang1,lang2):
df = read_file('text/%s-%s.txt' % (lang1, lang2), lang1, lang2)
print("Read %s sentence pairs" % len(df))
sentence1, sentence2 = read_sentence(df, lang1, lang2)
source = Lang()
target = Lang()
pairs = []
for i in range(len(df)):
if len(sentence1[i].split(' ')) < MAX_LENGTH and len(sentence2[i].split(' ')) < MAX_LENGTH:
full = [sentence1[i], sentence2[i]]
source.addSentence(sentence1[i])
target.addSentence(sentence2[i])
pairs.append(full)
return source, target, pairs
ฟังก์ชั่นที่มีประโยชน์อีกอย่างที่คุณจะใช้คือการแปลงคู่เป็นเทนเซอร์ สิ่งนี้สำคัญมากเนื่องจากเครือข่ายของเราอ่านเฉพาะข้อมูลประเภทเทนเซอร์เท่านั้น สิ่งสำคัญคือเนื่องจากนี่คือส่วนที่ทุกท้ายประโยคจะมีโทเค็นเพื่อบอกเครือข่ายว่าอินพุตเสร็จสิ้นแล้ว สำหรับทุกคำในประโยคจะได้รับดัชนีจากคำที่เหมาะสมในพจนานุกรมและเพิ่มโทเค็นที่ท้ายประโยค
def indexesFromSentence(lang, sentence):
return [lang.word2index[word] for word in sentence.split(' ')]
def tensorFromSentence(lang, sentence):
indexes = indexesFromSentence(lang, sentence)
indexes.append(EOS_token)
return torch.tensor(indexes, dtype=torch.long, device=device).view(-1, 1)
def tensorsFromPair(input_lang, output_lang, pair):
input_tensor = tensorFromSentence(input_lang, pair[0])
target_tensor = tensorFromSentence(output_lang, pair[1])
return (input_tensor, target_tensor)
โมเดล Seq2Seq

โมเดล PyTorch Seq2seq เป็นโมเดลประเภทหนึ่งที่ใช้ตัวถอดรหัสตัวเข้ารหัส PyTorch ที่ด้านบนของโมเดล ตัวเข้ารหัสจะเข้ารหัสคำในประโยคทีละคำลงในดัชนีของคำศัพท์หรือคำที่รู้จักด้วยดัชนี และตัวถอดรหัสจะทำนายเอาต์พุตของอินพุตที่เข้ารหัสโดยการถอดรหัสอินพุตตามลำดับ และจะพยายามใช้อินพุตสุดท้ายเป็นอินพุตถัดไปหาก มันเป็นไปได้. ด้วยวิธีนี้ ยังสามารถคาดเดาอินพุตถัดไปเพื่อสร้างประโยคได้อีกด้วย แต่ละประโยคจะได้รับโทเค็นเพื่อทำเครื่องหมายจุดสิ้นสุดของลำดับ เมื่อสิ้นสุดการทำนาย จะมีโทเค็นเพื่อทำเครื่องหมายจุดสิ้นสุดของผลลัพธ์ด้วย ดังนั้นจากตัวเข้ารหัส มันจะส่งสถานะไปยังตัวถอดรหัสเพื่อทำนายเอาต์พุต

ตัวเข้ารหัสจะเข้ารหัสประโยคที่เราป้อนทีละคำตามลำดับ และในตอนท้ายจะมีโทเค็นเพื่อทำเครื่องหมายจุดสิ้นสุดของประโยค ตัวเข้ารหัสประกอบด้วยเลเยอร์ Embedding และเลเยอร์ GRU เลเยอร์การฝังเป็นตารางการค้นหาที่จัดเก็บการฝังข้อมูลที่เราป้อนลงในพจนานุกรมคำศัพท์ที่มีขนาดคงที่ มันจะถูกส่งผ่านไปยังเลเยอร์ GRU GRU layer คือ Gated Recurrent Unit ที่ประกอบด้วยเลเยอร์หลายประเภท ร.น. ที่จะคำนวณอินพุตตามลำดับ เลเยอร์นี้จะคำนวณสถานะที่ซ่อนอยู่จากสถานะก่อนหน้า และอัปเดตการรีเซ็ต อัปเดต และเกตใหม่

ตัวถอดรหัสจะถอดรหัสอินพุตจากเอาต์พุตตัวเข้ารหัส จะพยายามคาดการณ์เอาต์พุตถัดไปและพยายามใช้เป็นอินพุตถัดไปหากเป็นไปได้ ตัวถอดรหัสประกอบด้วยเลเยอร์การฝัง เลเยอร์ GRU และเลเยอร์เชิงเส้น เลเยอร์ที่ฝังจะสร้างตารางการค้นหาสำหรับเอาต์พุตและส่งผ่านไปยังเลเยอร์ GRU เพื่อคำนวณสถานะเอาต์พุตที่คาดการณ์ไว้ หลังจากนั้นเลเยอร์เชิงเส้นจะช่วยคำนวณฟังก์ชันการเปิดใช้งานเพื่อกำหนดค่าที่แท้จริงของเอาต์พุตที่คาดการณ์ไว้
class Encoder(nn.Module):
def __init__(self, input_dim, hidden_dim, embbed_dim, num_layers):
super(Encoder, self).__init__()
#set the encoder input dimesion , embbed dimesion, hidden dimesion, and number of layers
self.input_dim = input_dim
self.embbed_dim = embbed_dim
self.hidden_dim = hidden_dim
self.num_layers = num_layers
#initialize the embedding layer with input and embbed dimention
self.embedding = nn.Embedding(input_dim, self.embbed_dim)
#intialize the GRU to take the input dimetion of embbed, and output dimention of hidden and
#set the number of gru layers
self.gru = nn.GRU(self.embbed_dim, self.hidden_dim, num_layers=self.num_layers)
def forward(self, src):
embedded = self.embedding(src).view(1,1,-1)
outputs, hidden = self.gru(embedded)
return outputs, hidden
class Decoder(nn.Module):
def __init__(self, output_dim, hidden_dim, embbed_dim, num_layers):
super(Decoder, self).__init__()
#set the encoder output dimension, embed dimension, hidden dimension, and number of layers
self.embbed_dim = embbed_dim
self.hidden_dim = hidden_dim
self.output_dim = output_dim
self.num_layers = num_layers
# initialize every layer with the appropriate dimension. For the decoder layer, it will consist of an embedding, GRU, a Linear layer and a Log softmax activation function.
self.embedding = nn.Embedding(output_dim, self.embbed_dim)
self.gru = nn.GRU(self.embbed_dim, self.hidden_dim, num_layers=self.num_layers)
self.out = nn.Linear(self.hidden_dim, output_dim)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, input, hidden):
# reshape the input to (1, batch_size)
input = input.view(1, -1)
embedded = F.relu(self.embedding(input))
output, hidden = self.gru(embedded, hidden)
prediction = self.softmax(self.out(output[0]))
return prediction, hidden
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device, MAX_LENGTH=MAX_LENGTH):
super().__init__()
#initialize the encoder and decoder
self.encoder = encoder
self.decoder = decoder
self.device = device
def forward(self, source, target, teacher_forcing_ratio=0.5):
input_length = source.size(0) #get the input length (number of words in sentence)
batch_size = target.shape[1]
target_length = target.shape[0]
vocab_size = self.decoder.output_dim
#initialize a variable to hold the predicted outputs
outputs = torch.zeros(target_length, batch_size, vocab_size).to(self.device)
#encode every word in a sentence
for i in range(input_length):
encoder_output, encoder_hidden = self.encoder(source[i])
#use the encoder’s hidden layer as the decoder hidden
decoder_hidden = encoder_hidden.to(device)
#add a token before the first predicted word
decoder_input = torch.tensor([SOS_token], device=device) # SOS
#topk is used to get the top K value over a list
#predict the output word from the current target word. If we enable the teaching force, then the #next decoder input is the next word, else, use the decoder output highest value.
for t in range(target_length):
decoder_output, decoder_hidden = self.decoder(decoder_input, decoder_hidden)
outputs[t] = decoder_output
teacher_force = random.random() < teacher_forcing_ratio
topv, topi = decoder_output.topk(1)
input = (target[t] if teacher_force else topi)
if(teacher_force == False and input.item() == EOS_token):
break
return outputs
ขั้นตอนที่ 3) การฝึกโมเดล
กระบวนการฝึกอบรมในโมเดล Seq2seq เริ่มต้นด้วยการแปลงประโยคแต่ละคู่เป็นเทนเซอร์จากดัชนี Lang แบบจำลองลำดับต่อลำดับของเราจะใช้ SGD เป็นตัวเพิ่มประสิทธิภาพและฟังก์ชัน NLLLoss เพื่อคำนวณการสูญเสีย กระบวนการฝึกอบรมเริ่มต้นด้วยการป้อนคู่ประโยคให้กับโมเดลเพื่อคาดเดาผลลัพธ์ที่ถูกต้อง ในแต่ละขั้นตอน ผลลัพธ์จากแบบจำลองจะถูกคำนวณด้วยคำจริงเพื่อค้นหาการสูญเสียและอัพเดตพารามิเตอร์ ดังนั้นเนื่องจากคุณจะใช้การวนซ้ำ 75000 ครั้ง แบบจำลองลำดับต่อลำดับของเราจะสร้างคู่แบบสุ่ม 75000 คู่จากชุดข้อมูลของเรา
teacher_forcing_ratio = 0.5
def clacModel(model, input_tensor, target_tensor, model_optimizer, criterion):
model_optimizer.zero_grad()
input_length = input_tensor.size(0)
loss = 0
epoch_loss = 0
# print(input_tensor.shape)
output = model(input_tensor, target_tensor)
num_iter = output.size(0)
print(num_iter)
#calculate the loss from a predicted sentence with the expected result
for ot in range(num_iter):
loss += criterion(output[ot], target_tensor[ot])
loss.backward()
model_optimizer.step()
epoch_loss = loss.item() / num_iter
return epoch_loss
def trainModel(model, source, target, pairs, num_iteration=20000):
model.train()
optimizer = optim.SGD(model.parameters(), lr=0.01)
criterion = nn.NLLLoss()
total_loss_iterations = 0
training_pairs = [tensorsFromPair(source, target, random.choice(pairs))
for i in range(num_iteration)]
for iter in range(1, num_iteration+1):
training_pair = training_pairs[iter - 1]
input_tensor = training_pair[0]
target_tensor = training_pair[1]
loss = clacModel(model, input_tensor, target_tensor, optimizer, criterion)
total_loss_iterations += loss
if iter % 5000 == 0:
avarage_loss= total_loss_iterations / 5000
total_loss_iterations = 0
print('%d %.4f' % (iter, avarage_loss))
torch.save(model.state_dict(), 'mytraining.pt')
return model
ขั้นตอนที่ 4) ทดสอบโมเดล
ขั้นตอนการประเมินของ Seq2seq PyTorch คือการตรวจสอบเอาต์พุตของโมเดล แต่ละคู่ของโมเดล Sequence to Sequence จะถูกป้อนเข้าไปในโมเดลและสร้างคำที่คาดการณ์ไว้ หลังจากนั้นคุณจะดูค่าสูงสุดในแต่ละเอาต์พุตเพื่อค้นหาดัชนีที่ถูกต้อง และสุดท้ายคุณจะเปรียบเทียบเพื่อดูการทำนายแบบจำลองของเรากับประโยคจริง
def evaluate(model, input_lang, output_lang, sentences, max_length=MAX_LENGTH):
with torch.no_grad():
input_tensor = tensorFromSentence(input_lang, sentences[0])
output_tensor = tensorFromSentence(output_lang, sentences[1])
decoded_words = []
output = model(input_tensor, output_tensor)
# print(output_tensor)
for ot in range(output.size(0)):
topv, topi = output[ot].topk(1)
# print(topi)
if topi[0].item() == EOS_token:
decoded_words.append('<EOS>')
break
else:
decoded_words.append(output_lang.index2word[topi[0].item()])
return decoded_words
def evaluateRandomly(model, source, target, pairs, n=10):
for i in range(n):
pair = random.choice(pairs)
print(‘source {}’.format(pair[0]))
print(‘target {}’.format(pair[1]))
output_words = evaluate(model, source, target, pair)
output_sentence = ' '.join(output_words)
print(‘predicted {}’.format(output_sentence))
ตอนนี้ เรามาเริ่มต้นการฝึกด้วย Seq ถึง Seq ด้วยจำนวนการวนซ้ำ 75000 และจำนวนเลเยอร์ RNN ที่ 1 โดยมีขนาดที่ซ่อนอยู่ 512
lang1 = 'eng'
lang2 = 'ind'
source, target, pairs = process_data(lang1, lang2)
randomize = random.choice(pairs)
print('random sentence {}'.format(randomize))
#print number of words
input_size = source.n_words
output_size = target.n_words
print('Input : {} Output : {}'.format(input_size, output_size))
embed_size = 256
hidden_size = 512
num_layers = 1
num_iteration = 100000
#create encoder-decoder model
encoder = Encoder(input_size, hidden_size, embed_size, num_layers)
decoder = Decoder(output_size, hidden_size, embed_size, num_layers)
model = Seq2Seq(encoder, decoder, device).to(device)
#print model
print(encoder)
print(decoder)
model = trainModel(model, source, target, pairs, num_iteration)
evaluateRandomly(model, source, target, pairs)
อย่างที่คุณเห็น ประโยคที่คาดเดาของเราไม่ตรงกันมากนัก ดังนั้นเพื่อให้ได้รับความแม่นยำมากขึ้น คุณจะต้องฝึกฝนโดยใช้ข้อมูลมากขึ้นและพยายามเพิ่มการวนซ้ำและจำนวนเลเยอร์โดยใช้ Sequence เพื่อการเรียนรู้ตามลำดับ
random sentence ['tom is finishing his work', 'tom sedang menyelesaikan pekerjaannya']
Input : 3551 Output : 4253
Encoder(
(embedding): Embedding(3551, 256)
(gru): GRU(256, 512)
)
Decoder(
(embedding): Embedding(4253, 256)
(gru): GRU(256, 512)
(out): Linear(in_features=512, out_features=4253, bias=True)
(softmax): LogSoftmax()
)
Seq2Seq(
(encoder): Encoder(
(embedding): Embedding(3551, 256)
(gru): GRU(256, 512)
)
(decoder): Decoder(
(embedding): Embedding(4253, 256)
(gru): GRU(256, 512)
(out): Linear(in_features=512, out_features=4253, bias=True)
(softmax): LogSoftmax()
)
)
5000 4.0906
10000 3.9129
15000 3.8171
20000 3.8369
25000 3.8199
30000 3.7957
35000 3.8037
40000 3.8098
45000 3.7530
50000 3.7119
55000 3.7263
60000 3.6933
65000 3.6840
70000 3.7058
75000 3.7044
> this is worth one million yen
= ini senilai satu juta yen
< tom sangat satu juta yen <EOS>
> she got good grades in english
= dia mendapatkan nilai bagus dalam bahasa inggris
< tom meminta nilai bagus dalam bahasa inggris <EOS>
> put in a little more sugar
= tambahkan sedikit gula
< tom tidak <EOS>
> are you a japanese student
= apakah kamu siswa dari jepang
< tom kamu memiliki yang jepang <EOS>
> i apologize for having to leave
= saya meminta maaf karena harus pergi
< tom tidak maaf karena harus pergi ke
> he isnt here is he
= dia tidak ada di sini kan
< tom tidak <EOS>
> speaking about trips have you ever been to kobe
= berbicara tentang wisata apa kau pernah ke kobe
< tom tidak <EOS>
> tom bought me roses
= tom membelikanku bunga mawar
< tom tidak bunga mawar <EOS>
> no one was more surprised than tom
= tidak ada seorangpun yang lebih terkejut dari tom
< tom ada orang yang lebih terkejut <EOS>
> i thought it was true
= aku kira itu benar adanya
< tom tidak <EOS>