Tutoriel R ANOVA : unidirectionnel et bidirectionnel (avec exemples)
Qu'est-ce que l'ANOVA ?
Analyse de la variance (ANOVA) est une technique statistique, couramment utilisée pour étudier les différences entre deux ou plusieurs moyennes de groupe. Le test ANOVA est centré sur les différentes sources de variation d'une variable typique. L'ANOVA dans R fournit principalement la preuve de l'existence de l'égalité moyenne entre les groupes. Cette méthode statistique est une extension du test t. Il est utilisé dans une situation où la variable factorielle comporte plus d’un groupe.
ANOVA unidirectionnelle
Il existe de nombreuses situations dans lesquelles vous devez comparer la moyenne entre plusieurs groupes. Par exemple, le service marketing souhaite savoir si trois équipes ont les mêmes performances commerciales.
- Équipe : 3 facteurs de niveau : A, B et C
- Vente : une mesure de performance
Le test ANOVA permet de savoir si les trois groupes ont des performances similaires.
Pour clarifier si les données proviennent de la même population, vous pouvez effectuer une analyse de variance unidirectionnelle (ANOVA unidirectionnelle ci-après). Ce test, comme tout autre test statistique, indique si l'hypothèse H0 peut être acceptée ou rejetée.
Hypothèse dans le test ANOVA unidirectionnel
- H0 : Les moyennes entre les groupes sont identiques
- H3 : Au moins, la moyenne d'un groupe est différente
En d’autres termes, l’hypothèse H0 implique qu’il n’y a pas suffisamment de preuves pour prouver que la moyenne du groupe (facteur) est différente d’un autre.
Ce test est similaire au test t, bien que le test ANOVA soit recommandé dans les situations comportant plus de 2 groupes. Sauf que le test t et l’ANOVA fournissent des résultats similaires.
Hypothèses
Nous supposons que chaque facteur est échantillonné de manière aléatoire, indépendant et provient d'une population normalement distribuée avec des variances inconnues mais égales.
Interpréter le test ANOVA
La statistique F est utilisée pour tester si les données proviennent de populations significativement différentes, c'est-à-dire de moyennes d'échantillon différentes.
Pour calculer la statistique F, vous devez diviser le variabilité entre les groupes au cours de la variabilité intra-groupe.
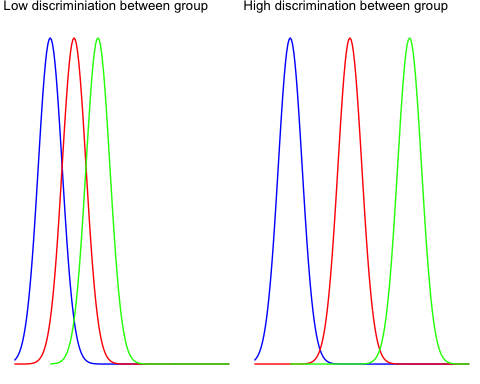
Le entre-groupes la variabilité reflète les différences entre les groupes au sein de l’ensemble de la population. Regardez les deux graphiques ci-dessous pour comprendre le concept de variance entre les groupes.
Le graphique de gauche montre très peu de variation entre les trois groupes, et il est très probable que les trois moyennes tendent vers global moyenne (c'est-à-dire moyenne pour les trois groupes).
Le graphique de droite représente trois distributions très éloignées les unes des autres, et aucune d'entre elles ne se chevauche. Il y a de fortes chances que la différence entre la moyenne totale et la moyenne du groupe soit importante.
Le au sein du groupe la variabilité prend en compte la différence entre les groupes. La variation vient des observations individuelles ; certains points peuvent être totalement différents des intentions du groupe. Le au sein du groupe la variabilité capte cet effet et se réfère à l'erreur d'échantillonnage.
Pour comprendre visuellement le concept de variabilité au sein du groupe, regardez le graphique ci-dessous.
La partie gauche représente la répartition de trois groupes différents. Vous avez augmenté la répartition de chaque échantillon et il est clair que la variance individuelle est importante. Le test F diminuera, ce qui signifie que vous aurez tendance à accepter l'hypothèse nulle
La partie droite montre exactement les mêmes échantillons (moyenne identique) mais avec une variabilité plus faible. Cela conduit à une augmentation du test F et tend en faveur de l’hypothèse alternative.

Vous pouvez utiliser les deux mesures pour construire les statistiques F. Il est très intuitif de comprendre la statistique F. Si le numérateur augmente, cela signifie que la variabilité entre les groupes est élevée et qu'il est probable que les groupes de l'échantillon proviennent de distributions complètement différentes.
En d’autres termes, une statistique F faible indique peu ou pas de différence significative entre la moyenne du groupe.
Exemple de test ANOVA unidirectionnel
Vous utiliserez l'ensemble de données sur les poisons pour mettre en œuvre le test ANOVA unidirectionnel. L'ensemble de données contient 48 lignes et 3 variables :
- Temps : Temps de survie de l'animal
- poison : Type de poison utilisé : niveau de facteur : 1,2 et 3
- traiter : Type de traitement utilisé : niveau de facteur : 1,2 et 3
Avant de commencer à calculer le test ANOVA, vous devez préparer les données comme suit :
- Étape 1 : Importer les données
- Étape 2 : Supprimez les variables inutiles
- Étape 3 : Convertir le poison variable en niveau ordonné
library(dplyr) PATH <- "https://raw.githubusercontent.com/guru99-edu/R-Programming/master/poisons.csv" df <- read.csv(PATH) %>% select(-X) %>% mutate(poison = factor(poison, ordered = TRUE)) glimpse(df)
Sortie :
## Observations: 48 ## Variables: 3 ## $ time <dbl> 0.31, 0.45, 0.46, 0.43, 0.36, 0.29, 0.40, 0.23, 0.22, 0... ## $ poison <ord> 1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 1, 1, 1, 1, 2, 2, 2... ## $ treat <fctr> A, A, A, A, A, A, A, A, A, A, A, A, B, B, B, B, B, B, ...
Notre objectif est de tester l’hypothèse suivante :
- H0 : Il n'y a pas de différence dans la durée moyenne de survie entre les groupes
- H3 : La moyenne des durées de survie est différente pour au moins un groupe.
En d’autres termes, vous voulez savoir s’il existe une différence statistique entre la moyenne des temps de survie selon le type de poison administré au cochon d’Inde.
Vous procéderez comme suit :
- Étape 1 : Vérifiez le format de la variable poison
- Étape 2 : Imprimez la statistique récapitulative : nombre, moyenne et écart type
- Étape 3 : Tracer une boîte à moustaches
- Étape 4 : Calculer le test ANOVA unidirectionnel
- Étape 5 : Exécutez un test t par paire
Étape 1) Vous pouvez vérifier le niveau du poison avec le code suivant. Vous devriez voir trois valeurs de caractères car vous les convertissez en facteur avec le verbe muter.
levels(df$poison)
Sortie :
## [1] "1" "2" "3"
Étape 2) Vous calculez la moyenne et l’écart type.
df % > % group_by(poison) % > % summarise( count_poison = n(), mean_time = mean(time, na.rm = TRUE), sd_time = sd(time, na.rm = TRUE) )
Sortie :
## # A tibble: 3 x 4 ## poison count_poison mean_time sd_time ## <ord> <int> <dbl> <dbl> ## 1 1 16 0.617500 0.20942779 ## 2 2 16 0.544375 0.28936641 ## 3 3 16 0.276250 0.06227627
Étape 3) À la troisième étape, vous pouvez vérifier graphiquement s’il existe une différence entre les distributions. Notez que vous incluez le point instable.
ggplot(df, aes(x = poison, y = time, fill = poison)) +
geom_boxplot() +
geom_jitter(shape = 15,
color = "steelblue",
position = position_jitter(0.21)) +
theme_classic()
Sortie :
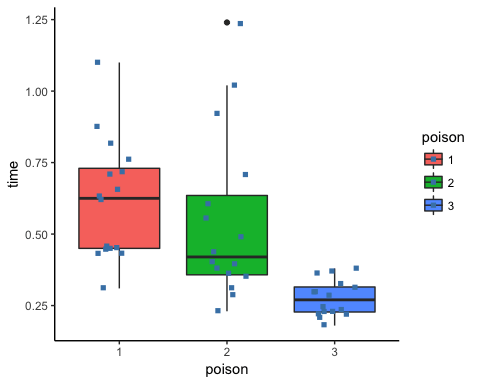
Étape 4) Vous pouvez exécuter le test ANOVA unidirectionnel avec la commande aov. La syntaxe de base d'un test ANOVA est la suivante :
aov(formula, data) Arguments: - formula: The equation you want to estimate - data: The dataset used
La syntaxe de la formule est :
y ~ X1+ X2+...+Xn # X1 + X2 +... refers to the independent variables y ~ . # use all the remaining variables as independent variables
Vous pouvez répondre à notre question : Y a-t-il une différence dans la durée de survie entre le cochon d'Inde, connaissant le type de poison administré.
Notez qu'il est conseillé de stocker le modèle et d'utiliser la fonction summary() pour obtenir une meilleure impression des résultats.
anova_one_way <- aov(time~poison, data = df) summary(anova_one_way)
Explication du code
- aov(time ~ poison, data = df) : Exécutez le test ANOVA avec la formule suivante
- summary(anova_one_way) : Imprimer le résumé du test
Sortie :
## Df Sum Sq Mean Sq F value Pr(>F) ## poison 2 1.033 0.5165 11.79 7.66e-05 *** ## Residuals 45 1.972 0.0438 ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
La valeur p est inférieure au seuil habituel de 0.05. Vous pouvez affirmer avec certitude qu'il existe une différence statistique entre les groupes, indiquée par le « * ».
Comparaison par paire
Le test ANOVA unidirectionnel n’indique pas quel groupe a une moyenne différente. Au lieu de cela, vous pouvez effectuer un test Tukey avec la fonction TukeyHSD().
TukeyHSD(anova_one_way)
Sortie :

ANOVA bidirectionnelle
Un test ANOVA bidirectionnel ajoute une autre variable de groupe à la formule. Il est identique au test ANOVA unidirectionnel, bien que la formule change légèrement :
y=x1+x2
avec est une variable quantitative et et sont des variables catégorielles.
Hypothèse dans le test ANOVA bidirectionnel
- H0 : les moyennes sont égales pour les deux variables (c'est-à-dire la variable factorielle)
- H3 : Les moyennes sont différentes pour les deux variables
Vous ajoutez une variable de traitement à notre modèle. Cette variable indique le traitement réservé au cochon d'Inde. Vous souhaitez voir s'il existe une dépendance statistique entre le poison et le traitement administré au cochon d'Inde.
Nous ajustons notre code en ajoutant un traitement avec l'autre variable indépendante.
anova_two_way <- aov(time~poison + treat, data = df) summary(anova_two_way)
Sortie :
## Df Sum Sq Mean Sq F value Pr(>F) ## poison 2 1.0330 0.5165 20.64 5.7e-07 *** ## treat 3 0.9212 0.3071 12.27 6.7e-06 *** ## Residuals 42 1.0509 0.0250 ## ---
Vous pouvez conclure que le poison et le traitement sont statistiquement différents de 0. Vous pouvez rejeter l’hypothèse NULL et confirmer que le changement de traitement ou de poison a un impact sur la durée de survie.
Résumé
Nous pouvons résumer le test dans le tableau ci-dessous :
| Test | Code | Hypothèse | Valeur P |
|---|---|---|---|
| ANOVA à sens unique |
aov(y ~ X, data = df) |
H3 : La moyenne est différente pour au moins un groupe | 0.05 |
| Par paire |
TukeyHSD(ANOVA summary) |
0.05 | |
| ANOVA à deux voies |
aov(y ~ X1 + X2, data = df) |
H3 : La moyenne est différente pour les deux groupes | 0.05 |